
浅谈数据库同步

【51CTO.com快译】顾名思义,数据库同步(Database synchronization)是指在两个或多个数据库之间建立数据的一致性,并且能够自动相互复制数据记录的更改。随着时间的推移和信息量的增多,此类数据的协调工作应当被持续执行。
从实现机制上说,最简单的操作方式莫过于将数据从源数据库(主数据库)推送到目标数据库(从数据库)。当然,值得注意的是:同步必须基于主键(Primary Key)的约束。同时数据库的结构应当包含有主键或唯一(主)索引,而绝不是复合型(composite)的。
通常,我们会在两到多个数据库之间持续如下类型的同步:
- 插入同步(Insert Synchronization)
- 更新同步(Update Synchronization)
- 删除同步(Drop Synchronization)
- 混合同步(Mixed Synchronization)
数据库插入同步
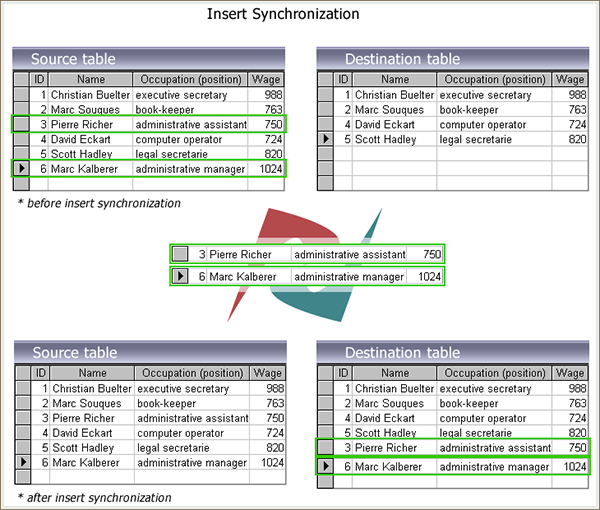
如果目标表中并不具有与源表相同主键值的适当记录,那么源表需要将新的记录自动传输到目标处。也就是说:在数据库完成同步过程后,那些缺少的记录将被插入到目标表的对应位置。
下图展示了数据库插入同步的具体过程:
数据库更新同步
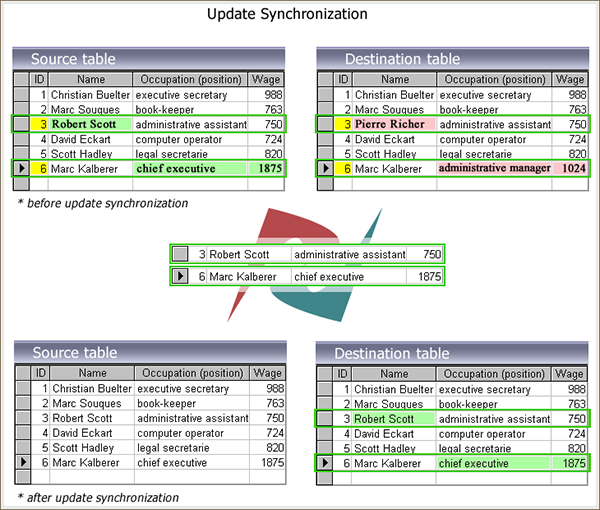
当源数据库发生更改时,我们必须确保在目标数据库中执行适当的更改。显然,在同步之前,我们需要先比较两个数据库的记录值,然后在目标表处替换需要更改的记录,并在两个表之间建立合适的标识,以标记更新数据库的操作已完成。
下图展示了数据库更新同步的具体过程:
数据库删除同步
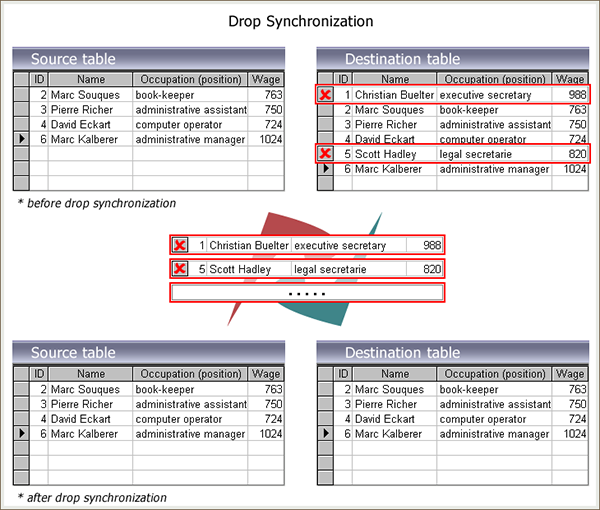
如果某些数据记录已经从源数据库中被删除,那么其对应的记录也需要及时从目标数据库中被移除。也就是说,通过检查“删除同步选项(Drop-sync option)”,那些“滞留”在目标数据库中的多余记录会被及时删除掉,以保障源数据库与目标数据库的存储一致性。
下图展示了数据库删除同步的具体过程:
数据库混合同步
其实在实际应用中,上述三种同步操作从来不是孤立地存在着。为了保持两个数据库的相关性,我们必须在同一套操作中,对目标数据库的对应行/列“打出”添加、更新、以及删除的“组合拳”。
下图展示了数据库混合同步的具体过程:

在《跨数据库转换和同步软件》(请参见-- https://dbconvert.com/)一文中,作者详细介绍了如何在SQL Server、MySQL、Oracle、以及PostgreSQL等时下流行的本地数据库之间,迁移与同步各类数据与记录的操作。当然,此类方法也适用于AWS RDS/Aurora、Microsoft Azure SQL、以及Google Cloud SQL等云端数据库平台。
原标题:What Is Database Synchronization?,作者: Dmitry Narizhnykh
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
相关文章
- HBase从入门到精通系列:误删数据如何抢救?
- 上海人才大数据:上下班1小时,年薪30万
- Kaggle 20G数据集强势分析“绝地求生”,科学吃鸡攻略拿走不谢!
- 数据解读:中国高校招生如何不平等?
- 人工智能与大数据的区别
- 腾云大学与美世咨询联合发布会圆满举行,全面明确行业定义
- 全球十大数据治理解决方案提供商
- Kafka解惑之时间轮 (TimingWheel)
- 还不收藏?Spark动态内存管理源码解析!
- 大数据分析系统Hadoop的13个开源工具
- 数据科学“内战”:统计vs.机器学习
- 零售业强竞争,大数据如何帮助弱者角逐
- 当大数据满足数据可视化时,如何使数据变得可操作
- 深度:Hadoop对Spark五大维度正面比拼报告!
- 伯克利发布迄今为止最大驾驶数据集BDD100K,含10万段视频
- 你的数据化经营为何屡战屡败,118位CTO给出的7个管理经验
- 如何在万亿级别规模的数据量上使用 Spark?
- 什么是预测分析技术?将数据转化为对未来的见解
- 可视化的三大误区,哪些可视化工具受欢迎?
- 深入浅出:大妈也能看懂的大数据分布式计算