
分布式锁的封装也很有讲究呀
分布式锁通常有很多选择,基于 Redis 的,基于 Zookeeper 的,基于数据库等等方案。
Redis 用于缓存数据,在项目中都有使用,所以使用 Redis 来做分布式锁的会稍微多些。
如果用 Redis 来做锁,可以直接用开源的方案,比如redisson。
最常见的使用方式如下所示:
- RLock lock = redisson.getLock("anyLock");
- lock.lock();
- run();
- lock.unlock();
获取锁对象,调用 lock()加锁,执行业务逻辑,调用 unlock()释放锁。
尽管框架提供的使用方式已经很简洁了,但是我们还是有必要对锁做一层包装。做包装的目的是为了提高扩展性和易用性。
抽象接口
如果说我们直接使用 redisson 的原生 API 做加锁,那么很多地方都会出现 RLock 相关的代码,突然有一天,由于某些原因,需要将锁进行替换,这个时候改动的范围就比较大了。每个使用了 RLock 的地方都得改。
如下图:很多 Service 都用到了 RLock.lock()方法,当我们需要替换锁的时候,所有涉及到的类和方法都得修改,改动的点如红色部分所示。
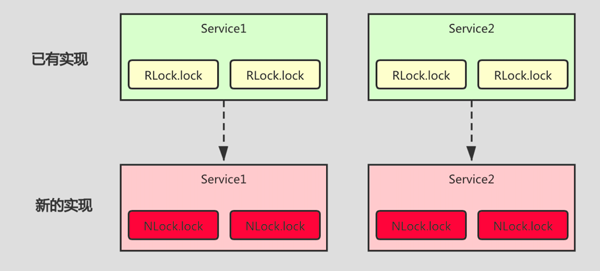
所以我们需要做一层抽象,可以定义一个 DistributedLock 接口来提供锁相关的能力,提供多种实现,这样方便替换和扩展。
如下图:每个 Service 中都是用的 DistributedLock 接口来加锁,当我们需要替换锁的实现时,使用的地方不需要改动,只需要替换 DistributedLock 的实现即可。
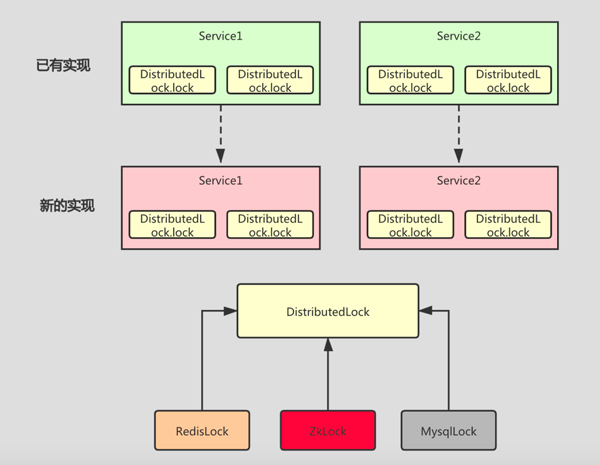
自动释放
自动释放指的是对于加锁之后,业务逻辑执行完毕需要自动关闭锁。按照前面 Redisson 的方式我们需要手动调用 unlock()来释放持有的锁。
当然 Redisson 也提供了超时释放的功能,正常情况下肯定是业务执行完毕就要释放锁了,同一个锁的下个请求才能继续接着处理。
手动释放资源最容易出现的问题就是忘记释放,所以在 JDK7 中引入了 try-with-resources 来自动释放资源,相信大家都很熟悉。
所以我们在封装的时候,尽量不要让使用者去手动释放,减少出错的概率。对于有结果的我们可以使用 Supplier 来传递你的逻辑,对于没有返回结果的可以用 Runnable 来传递你的逻辑。
- /**
- * 加锁
- * @param key 锁Key
- * @param waitTime 尝试加锁,等待时间 (ms)
- * @param leaseTime 上锁后的失效时间 (ms)
- * @param success 锁成功执行的逻辑
- * @param fail 锁失败执行的逻辑
- * @return
- */
- <T> T lock(String key, int waitTime, int leaseTime, Supplier<T> success, Supplier<T> fail);
使用:
- String result = distributedLock.lock("1001", 1000, () -> {
- System.out.println("进来了。。。。");
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- return "success";
- }, () -> {
- System.out.println("加锁失败。。。。");
- return "fail";
- });
容灾处理
另一个需要注意的问题就是锁的可用性,万一对应的 Redis 出问题了,这个时候去加锁肯定会失败,如果不做任何处理,就会影响正常的业务操作,导致业务不可用。
我们除了实现 Redis 的锁之外,还可以实现其他的锁,比如数据库锁。当 Redis 锁不可用的时候降级为数据库锁,虽然性能有所影响,但是不会影响业务。
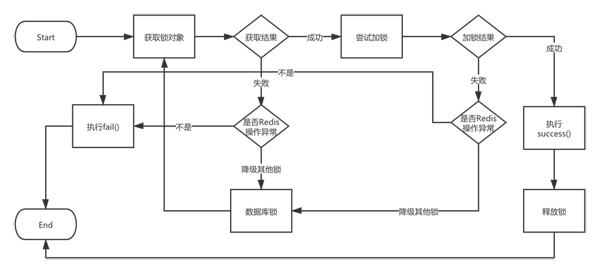
加锁流程
如果数据库锁也不可用了(题外话:所有都不可用可能性非常小),那还是让业务操作失败比较好。因为我们用加锁的场景,肯定是为了防止并发场景带来的问题,如果当锁不可用时,你将异常消费了,让业务操作继续下去,就有可能出现没有加锁的业务问题。
当然监控也非常需要,Redis, 数据库等监控。在出故障的时候,及时有人员介入。
监控体系
Redis, 数据库,Zookeeper 这些承载分布式实现的中间件的监控肯定是必须要有的。另一个监控就是更细粒度的对应锁这个动作的监控。
比如加锁的时间,释放锁的时间,在锁里面执行业务的时间,锁的并发量,执行次数,加锁失败的次数。
这些数据指标都非常重要,能够帮助你及时发现问题。比如 10 秒内几百次加锁失败,都降级成了数据库锁,这个时候你收到了警报,一看就知道 Redis 出问题了,及时解决。
监控方式就随便了,每个公司都不一样,你可以暴露数据给 Prometheus 抓取,也可以集成 Cat 做好埋点,只要能监控,能告警就可以了。
相关文章
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假
- 183条地铁线路,3034个地铁站,发现中国地铁名字的秘密
- 我们分析了复仇者联盟系列所有台词,看看英雄们都爱说什么?没有剧透!
- 百 PB 级 Hadoop 集群存储空间治理
- 数据工程师和数据科学家有什么不同
- 4大数据分析要素 “套路”方法要学会!