
在Scrapy中如何利用Xpath选择器从网页中采集目标数据

这篇文章我们将通过Xpath表达式来进行提取数据,具体教程如下,仍然以之前的网站为例进行说明,我们的目标数据是标题、发布日期、主题、正文内容、点赞数、收藏数、评论数等。具体的教程如下。
/具体实现/

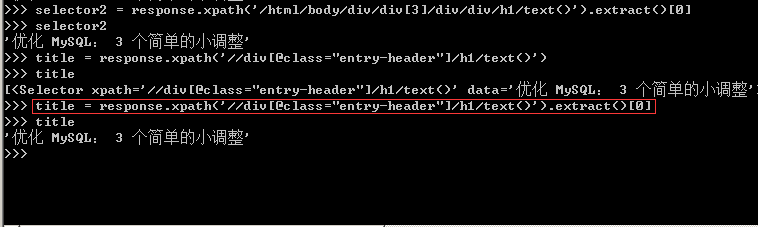
1、针对标题,在上篇文章中就有提及,其Xpath表达式有多种,任选其一即可,在scrapy shell脚本下进行调试,得到标题的提取方式,并写入到爬虫主体文件中。
2、接下来是发布日期的提取,仍然是以交互式的方式实现网页与源码之间的交互,如下图所示。
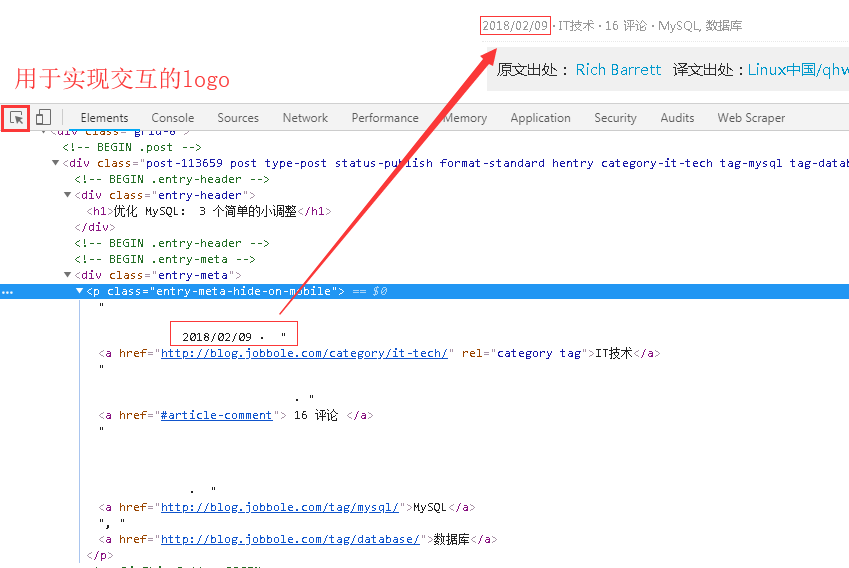
3、而且标签“entry-meta-hide-on-mobile”具有全局唯一性,可以很方便的定位到元素。
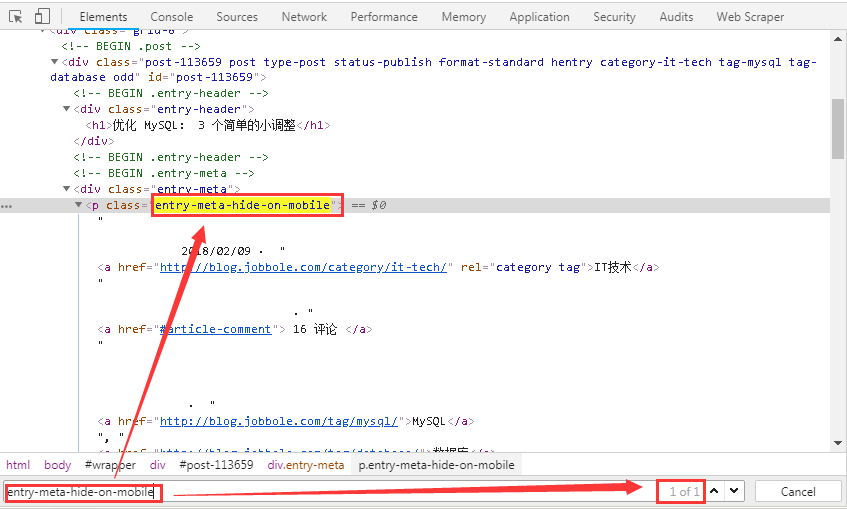
4、根据网页结构,我们可轻易的写出发布日期的Xpath表达式,可以在scrapy shell中先进行测试,再将选择器表达式写入爬虫文件中,详情如下图所示。
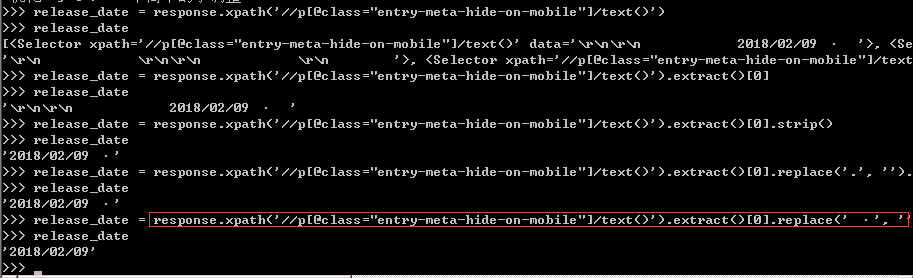
这里有部分杂质信息,需要利用strip()和replace()函数剔除多余的杂质,还日期一个“清白”。
5、关于文章主题标签的Xpath表达式,可以看到其在网页结构上处于日期的下方,如下图所示。
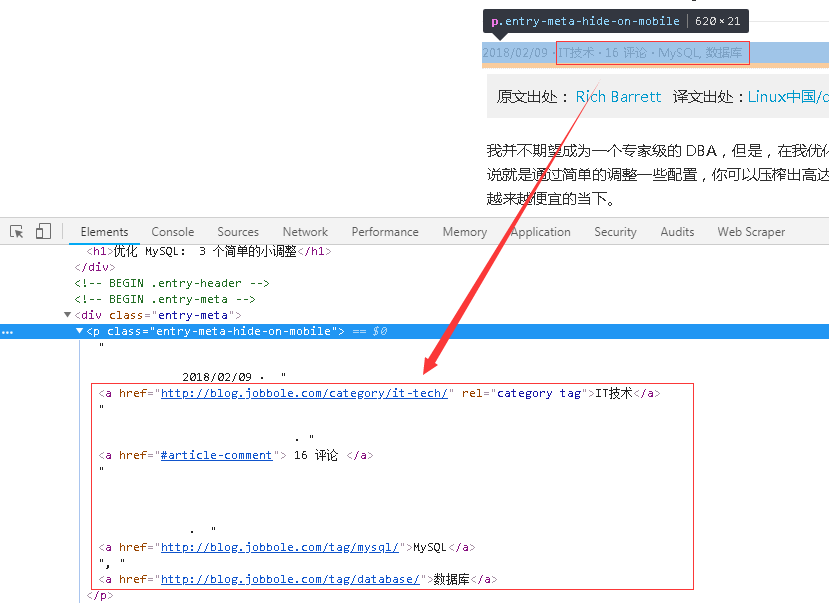
因此可以通过更改一下发布日期的Xpath表达式,即可获取到文章主题标签。
6、文章主题标签处于a标签下,如下图所示。
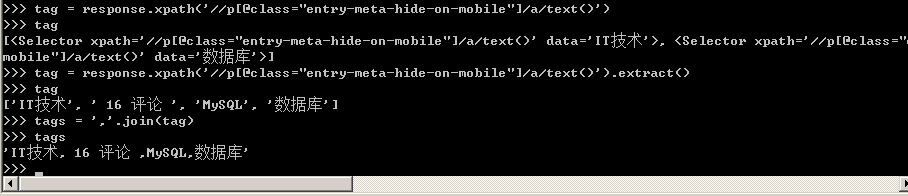
获取到整个列表之后,利用join函数将数组中的元素以逗号连接生成一个新的字符串叫tags,然后写入Scrapy爬虫文件中去。
7、对于点赞数,其分析方法同之前一致,找到唯一的一个标签“vote-post-up”即可定位到数据。
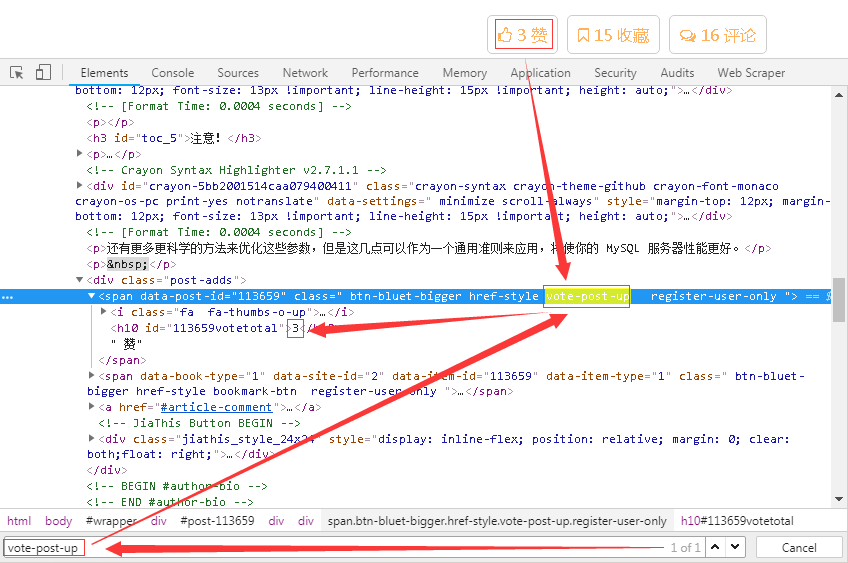
8、细心的小伙伴可能会看到“vote-post-up”属性并不是class标签中唯一一个属性,所以一开始的Xpath表达式匹配的内容为空。
这里给大家安利一个小技巧,如果标签中存在多个属性,且属性是唯一的时候,可以利用contains函数进行助攻,其用法是'//span[contains(@class,"vote-post-up"),务必要多加练习,否则容易忘记。根据网页结构写出Xpath表达式,调试的过程如下图所示。
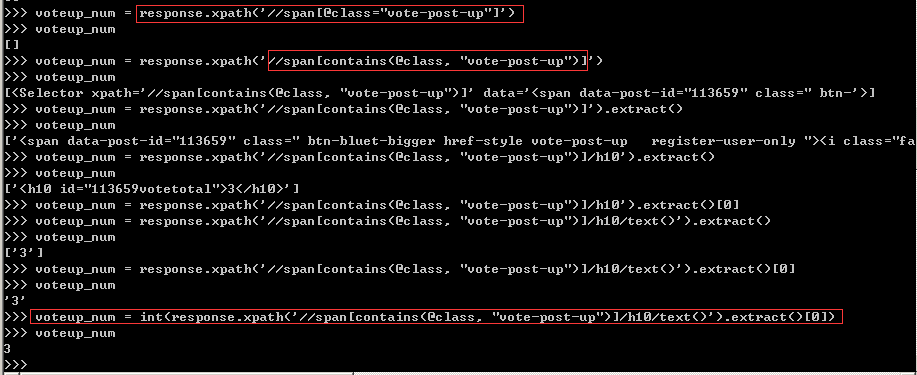
取出的点赞数是个字符串,需要利用int()将其强制转换为数字。
/小结/
本文基于Xpath理论基础,主要介绍了Scrapy爬虫框架中利用Xpath选择器提取某个网页中目标数据的方法,为后面抓取全网数据埋下伏笔,更精彩的操作在下篇文章奉上,希望对大家的学习有帮助。
相关文章
- 在 AWS 中国区对 Amazon Elasticsearch Kibana 进行身份认证的解决方案
- 送你一个编程教练可好?你应当了解的 Amazon CodeGuru
- DynamoDB Accelerator(DAX)服务–无需改写应用,将 DynamoDB 的响应时间从毫秒提升到微秒
- 使用 Amazon Redshift 设计数据湖架构的 ETL 和 ELT 模式:第 2 部分
- 使用 Amazon Redshift 设计数据湖架构的 ETL 和 ELT 模式:第 1 部分
- 如何将 AWS Lambda 与 Spinnaker 集成
- 新功能 – 适用于预置 IOPS (io1) Amazon EBS 卷的多挂载功能
- 借助 AWS IoT Greengrass Docker Application Deployment 连接器将容器应用部署到 IoT 边缘
- 在 AWS 上快速搭建在线教学平台
- 第一部分 SAP on AWS EC2 Auto Recovery
- SAP on AWS 部署架构(引论)
- 新增功能:将 AWS CloudFormation StackSets 用于 AWS Organization 中的多个账户
- Java RMI实现
- 全新 – 在 AWS Well-Architected Tool 中使用无服务器剖析
- 在 Amazon Elasticsearch Service 上推出 Open Distro for Elasticsearch 安全功能
- 使用 AWS 同步路由以跨路由表同步路由,这是一个无服务器的开源项目
- 圣保罗区域的 EC2(R5 和 I3)降价
- AWS Client VPN 的新桌面客户端
- 通过 AWS 上的服务器端 Swift 持续交付
- Java Volatile Keyword