
面试被吊打系列-Redis缓存血崩

本文转载自微信公众号「JAVA日知录」,作者单一色调。转载本文请联系JAVA日知录公众号。
小张兴冲冲去面试,结果因为redis的缓存雪崩问题被面试官拒绝!
小张:面试官,你好。我是来参加面试的。
面试官:你好,小张。我看了你的简历,你们平时在项目中用了redis,能说一下你们使用redis的场景吗?
小张:redis的话我们主要是用来存储一些常用的配置类数据还有一些热点数据;还有存储一些到期失效的数据,比如登录用户颁发的token等。
面试官:那好,既然你们用来存储热点数据。那么我来问你个实际场景,「查询热点数据的时候会先从缓存加载,如果缓存没有命中则会检索数据库获取数据。往往我们还会给热点缓存数据设置一个过期时间。那么我的问题是,假设在某一时间点热点缓存全部过期失效了,这样所有的请求都会直接进入数据库,一瞬间就会把数据库压垮,如果是你会怎么解决这个问题?」
小张:emm...面试官,我肚子有点不舒服,我先回去了。小张卒!
面试官:因为缓存同一时间大面积的失效,或者缓存服务暂时不能提供服务等,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机。这一现象被称之为 「缓存雪崩」。
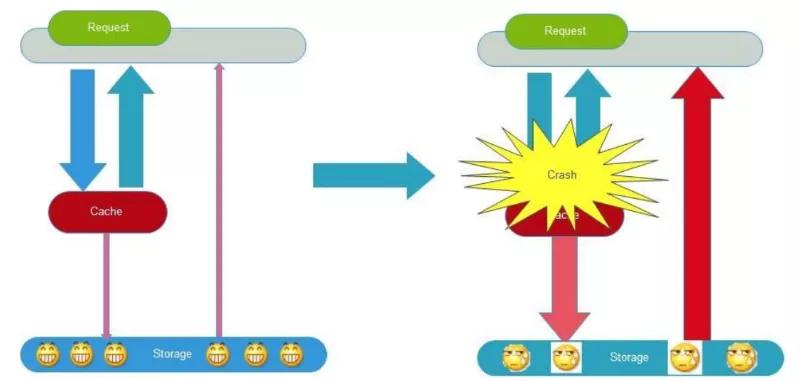
缓存血崩可以通过以下四个维度来解决:
「缓存预热」
数据加热的含义就是在正式部署之前,先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key。
「加上互斥锁」
可以在第一个查询数据的请求上使用一个互斥锁来锁住它,其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后将数据放到redis缓存起来。后面的线程进来发现已经有缓存了,就直接走缓存。
「过期时间均匀分布」
给缓存的时效时间加上随机因子,即给缓存设置不同的过期时间,让缓存失效的时间点尽量均匀。
「构建高可用的缓存系统」
把Redis设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
面试官:各位看官朋友们,你们学会怎么解决缓存雪崩的问题了吗?希望你们以后面试不会被这个问题难倒哟~
小张:学到了学到了,我下次再来。(早知道不提什么热点数据了,不提面试官就不会问。)
面试官:小样,不问这个那么我不会问其他的了吗?你下次再来试试!
相关文章
- 深度解析:AWS Fargate 数据平面
- 如何用 Glue ETL 输出分区数据
- Amazon DocumentDB(兼容 MongoDB)推出基于角色的访问控制
- 利用云上灾备管理工具迁移和保护 EC2 实例
- Amazon RDS Proxy – 现已全面推出
- 使用基于 GTID 的复制通过回退选项迁移至 Amazon Aurora MySQL
- 利用 Amazon Neptune T3 实例将构建图形应用程序的成本降低最多 76%
- 使用 Amazon Neptune 绘制投资依存关系图
- 使用全自动工具将 Neo4j 图形数据库迁移到 Amazon Neptune
- 在 Amazon DocumentDB(兼容 MongoDB)中使用 $dateFromString 和 executionStats
- Amazon DocumentDB(兼容MongoDB)教程第三部分——使用 Robo 3T
- 利用 Amazon CloudWatch 指标做出更好的 Amazon RDS 决策
- 众多的数据库类型,你该怎么选择?
- Amazon DocumentDB 入门(兼容 MongoDB);第 2 部分 – 使用 AWS Cloud9
- Amazon DocumentDB 入门(兼容 MongoDB);第 1 部分 – 使用 Amazon EC2
- 在 Amazon Aurora Global Database 中使用写入转发构建全球分布式 MySQL 应用程序
- Amazon Redshift Spectrum – EB 级的 S3 数据就地查询
- 使用 Amazon Forecast 准确预测用电量
- Java_day17
- 开源软件 ProxySQL 与 AWS RDS 不得不说系列 Blog(二):借助 ProxySQL 的 Firewall 功能保护 AWS RDS 数据库