
xeus-sql:让Jupyter支持SQL处理
现在用Jupyter进行数据处理,对数据工作者来说已经不是一个新鲜事情了。然而如何将大量数据导入却是一个比较棘手的事情。大家都知道关系数据库是数据存储的最重要的载体,那么对数据库的支持是Jupyter数据科学界一个迫切的需求。

此前Jupyter曾发布过一个内核xeus-sqlite允许用户直接从notebook进行SQLite查询。日前Jupyter新发布了一个新的项目xeus-sql,这是对xeus-sqlite的扩展,是Jupyter的通用数据库访问工具,使用它可以在绝大多数的关系数据库上进行SQL查询。
数据库支持
xeus-sql支持市面上的绝大多数数据,包括:
- MySQL
- PostgreSQL的
- SQLite3
- DB2
- Oracle
- Firebird
以及支持ODBC驱动程序的任何数据库。
为了提供所有这些集成,xeus-sql依赖SOCI库作为项目的主干。SOCI在统一的C++ API之后抽象所有不同的数据库连接和查询详细信息。xeus-sql使用SOCI和xeus将SQL功能公开给Jupyter。
安装
为确保安装正常进行,最好xeus在一个全新的conda环境中安装。xeus-sql还需要使用miniconda安装,完整的anaconda 可能会产生冲突。最安全的用法是创建一个以xeus-sqlminiconda安装命名的环境:
- conda create -n xeus-sql
- conda activate xeus-sql
从conda安装
Conda forge提供了MySQL,PostgreSQL和SQLite的打包版本,可以使用conda或mamba轻松安装它们一键安装,使用conda软件包管理器安装xeus-sql:
- conda install xeus-sql jupyterlab -c conda-forge
或者使用mamba:
- mamba install xeus-sql jupyterlab -c conda-forge
或者可以分别安装:
- mamba install xeus-sql soci-mysql -c conda-forge
- mamba install xeus-sql soci-postgresql -c conda-forge
- mamba install xeus-sql soci-mysql -c conda-forge
不同的SQL后端之间存在一些差异,可以参考xeus-sql详细文档和示例学习。
使用方法
要连接MySQ,需要首先安装xeus-sql和soci-mysql,然后用LOAD加载连接数据库:
- %LOAD mysql db=dbname user=user1 password='Password123#@!'
上面db数据库名称,user为连库用户名,password为用户密码。
连接成功就可以执行数据库命令和SQL语句,比如:
- show databases;
- SELECT * FROM test
- INSERT INTO example VALUES (2, 'Core')
- SELECT * FROM example
- INSERT INTO example VALUES (3, 'Table')
其他数据库后端也类似:
firebird:
- %LOAD firebird service=firebird.fdb user=SYSDBA
postgresql:
- %LOAD postgresql dbname=newdvdrental
可视化查询
对于熟悉可视化SQL表和查询结果的表形式的用户,Jupyter的丰富显示系统提供了根据使用的应用程序将它们显示为丰富文本显示还是纯文本显示的选项。
除了显示带有表的查询之外,在还可以直接在Notebook中根据查询结果轻松创建Vega-Lite图形:
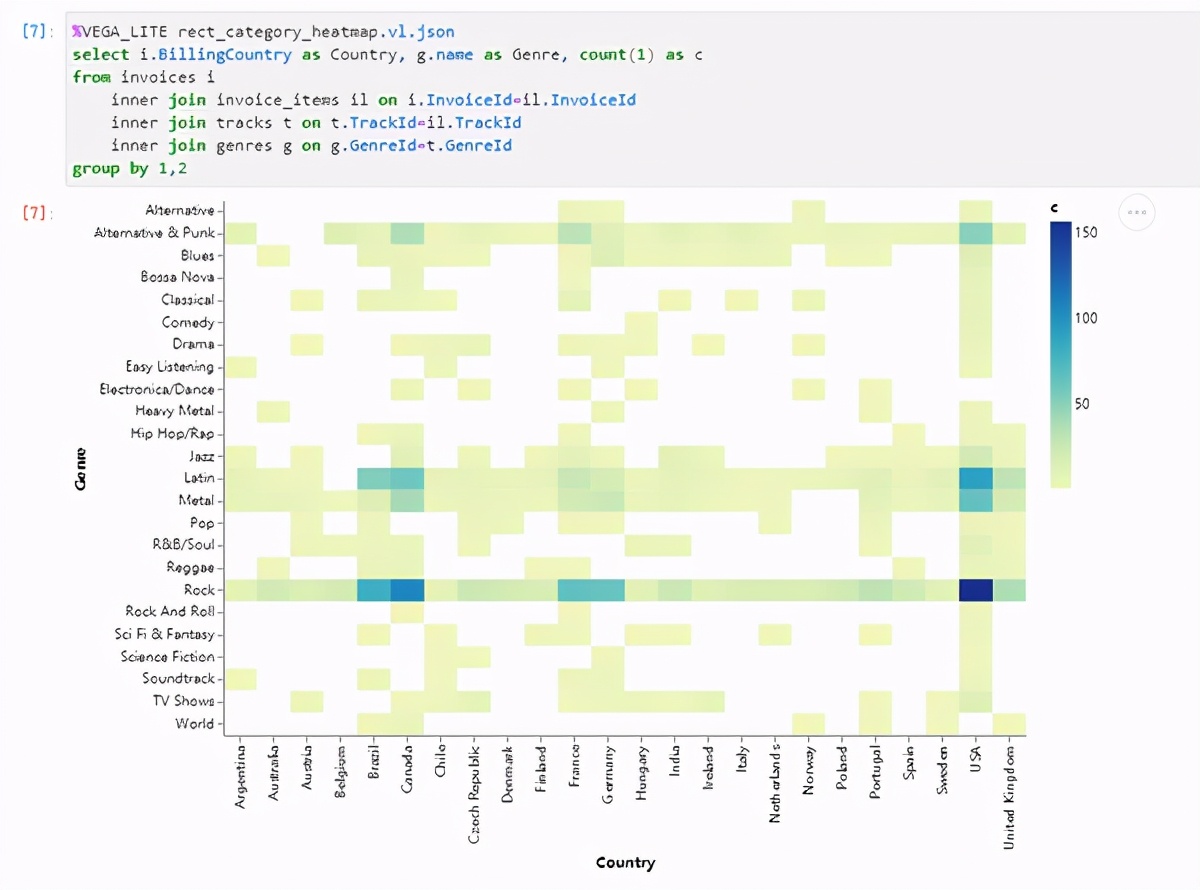
Vega-Lite是一个功能强大的库可以使用xeus-sql从关系数据中创建许多不同的可视化文件。
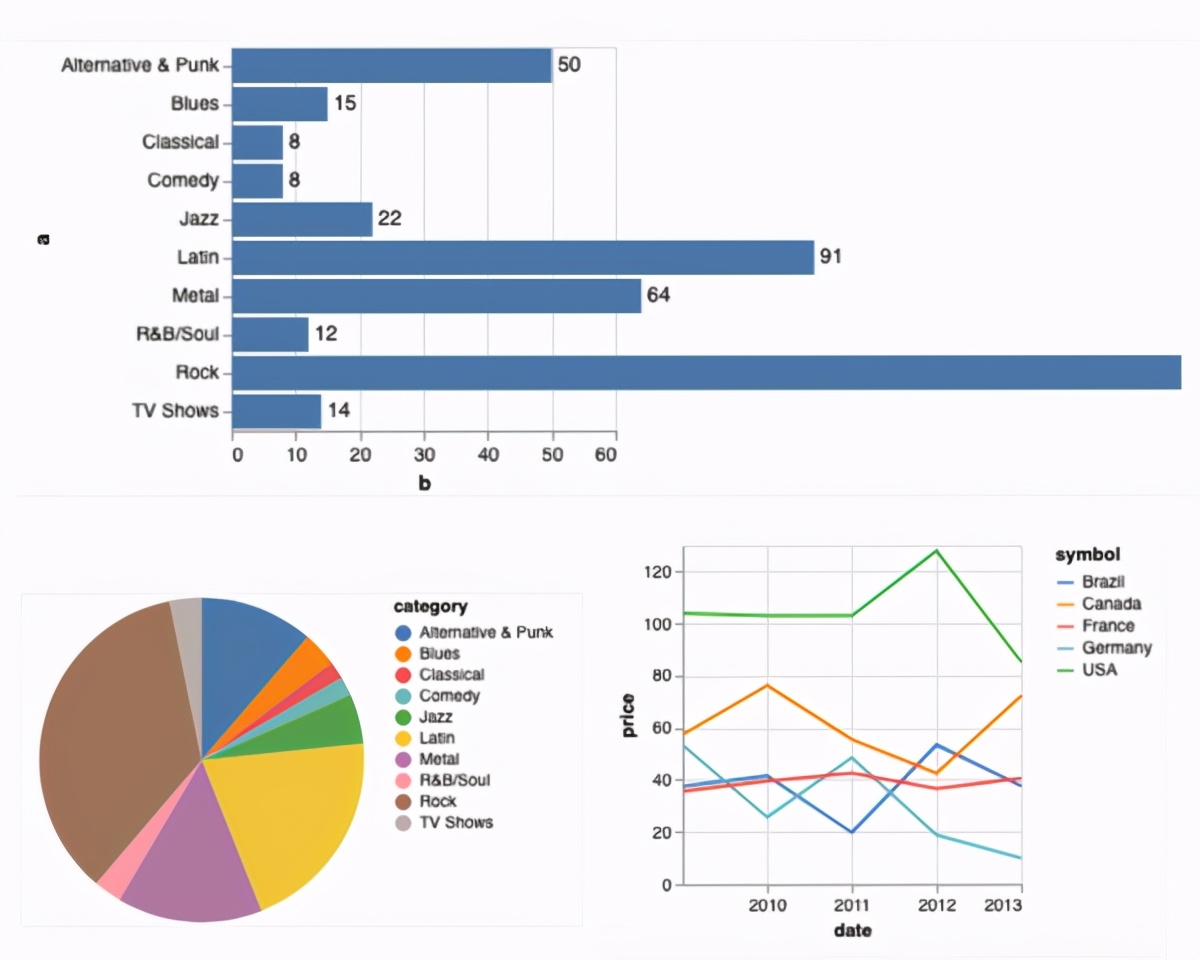
为了支持此功能,xeus-sql依赖于xvega(vega的C++后端)和定制的Jupyter魔术来绘制通过xvega-bindings实用程序库中实现的微型语言。除了使用迷你语言之外,还可以直接提供可视化的JSON规范。
总结
xeus-sql的推出,让Jupyter如虎添翼,可以非常方便数据工作者进行数据处理和可视化。同时对于传统dba和数据库用户可以使用Jupyter作为一个便捷的数据库客户端。
相关文章
- Savings Plan 更新:最高节省 17% 的 Lambda 工作负载
- 第二部分 SAP on AWS Pilot Light
- java nio总结
- python hbase 读写
- python MySQL 插入数据
- Amazon Redshift Spectrum 十二大最佳实践
- 紧急 & 和重要说明– 轮换您的 Amazon RDS、Aurora 和 DocumentDB 证书
- Amazon Redshift Spectrum 将数据仓库扩展到 EB 级别且无需加载
- 2019 年 Alejandra 最爱 re:Invent ? 的五项发布内容
- Java-IO流
- 在 Amazon EMR 上运行 PySpark 报表业务
- 使用 AWS Glue 从 Kinesis 数据流中分离出不同的数据库表格
- Java8 Stream
- 利用 DataSunrise Security 保护和审计 Amazon Redshift 中的 PII 数据
- Java_day10
- 如何在不停机的情况下将大型数据仓库从 IBM Netezza 迁移到 Amazon Redshift 中
- 如何为 Amazon S3 中的 AWS KMS 加密数据启用跨账户 Amazon Redshift COPY 和 Redshift Spectrum 查询
- AWS KMS 实现跨租户的安全数据加密
- 使用 R 完成基于 Amazon Athena 交互分析
- java IO 流