
Redis那些你不经常使用的数据结构
如果你了解过redis,或者使用过它,那么一定知道它的5种常用数据结构,而且如果你面试有被问过redis的话,那么这5种基本数据结构也一定会被问到,不过,我们今天不讨论这些,我们讨论下除此之外的数据结构,也许平时你没有使用过,也许你也没有了解过,不过这不重要,重要的是它们是非常总要的数据结构,在解决特定问题的时候很好用。

Btimap
理论上来说,bitmap并不属于一种特殊的数据结构,从本质上来说,它也是一种string类型数据结构,只不过存储的值为bit,也就是我们常说的二进制010101这样的数据。
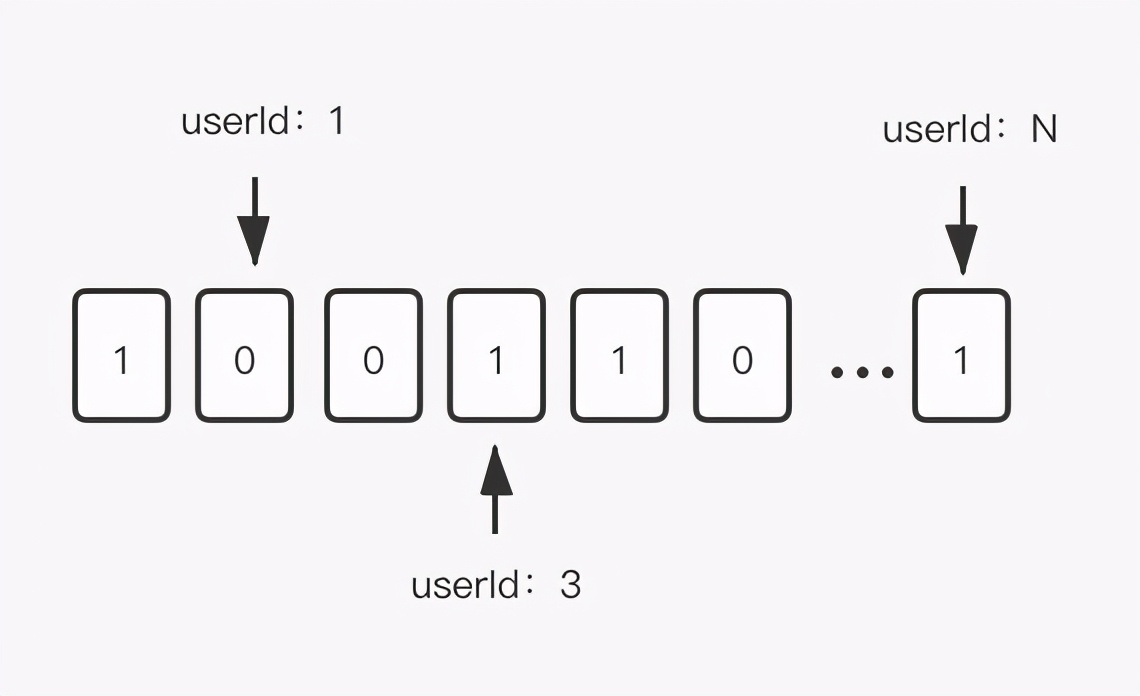
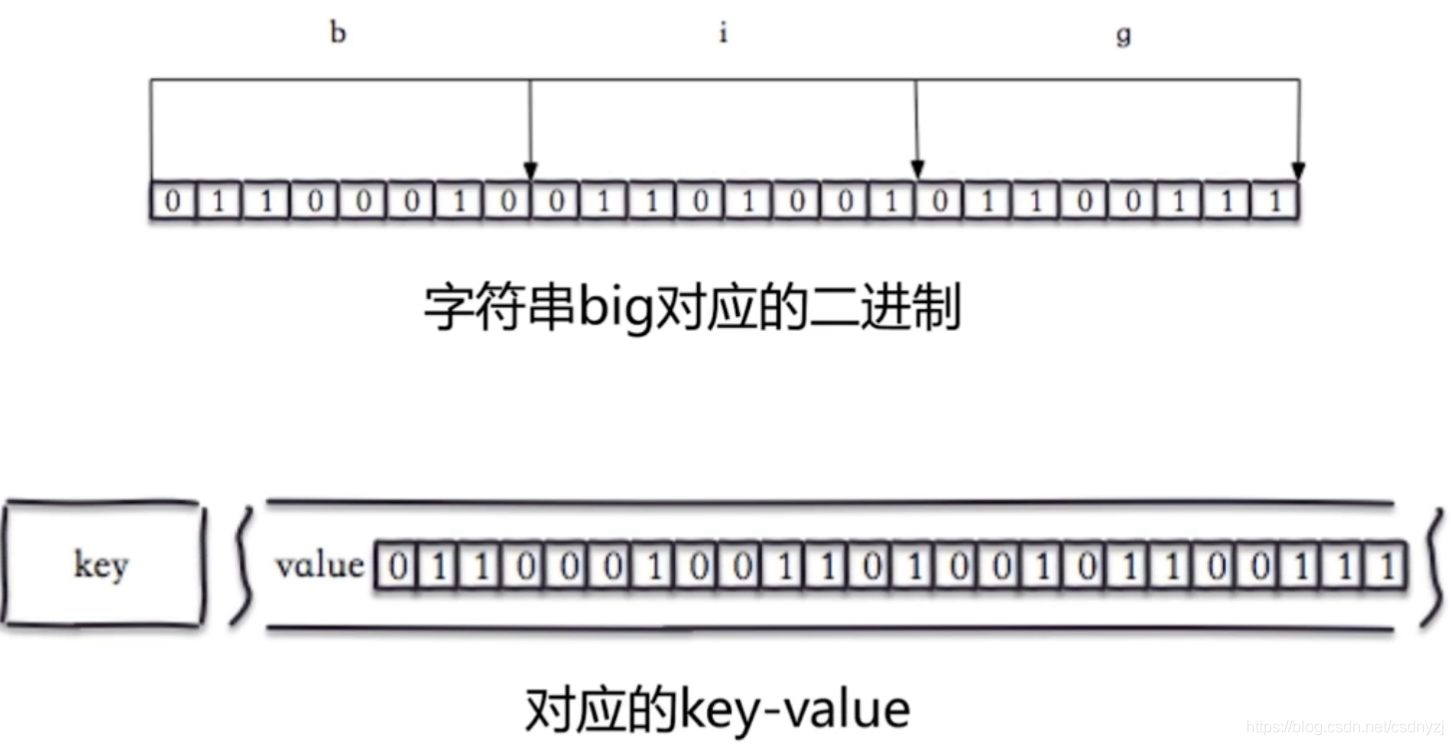
这样的数据结构可以帮助我们使用很少的存储空间,就可以完成很高效的数据查询。
比如我们有这样的需求,我们想要统计每一天的用户签到人数,常规的做法就是将数据放到set集合里面,然后对数据求和即可,然而如果数据量非常大的时候,这样会浪费很大的存储空间,而bitmap完美解决了这样的问题。首先我们可以将每天的日期作为key,然后签到的人的id转换成bit值存储,也就说如果它签到了,那么对应位置的值为1,否则为0,这样就可以通过一个key:value对来统计签到人数。需要说明的是,对于位操作,redis有bitcout来快速统计总和。
HyeprLogLog
从名字我们可以看出来,它有两个log,也就是说它通过两次取对数的操作节省了存储空间。需要说明的一点,这是一个概率数据结构,也就说它只能计算出大概率数值,并不能精确地得到精准数值,不过在大数据问题中,能够用最少的代价得到一个大致精确地值就是我们追求的。
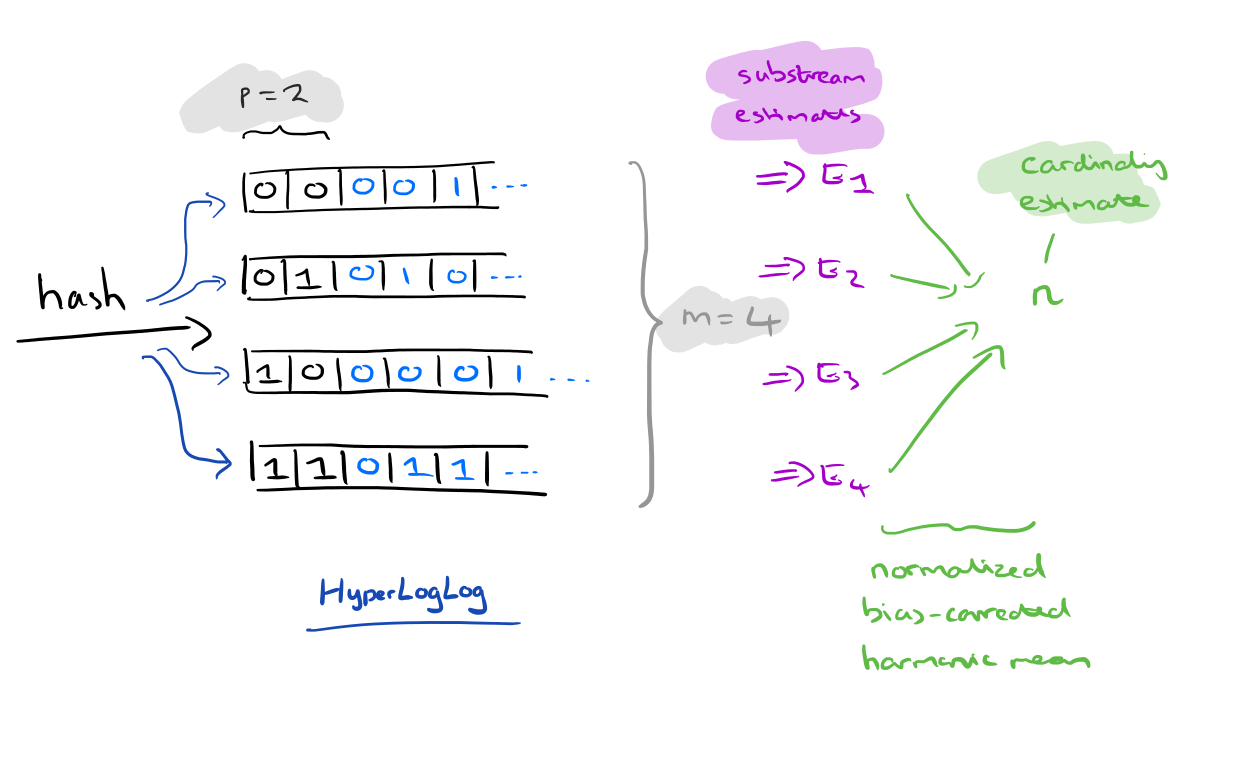
在redis里面,每个hyperloglog键只需要花费12kb大小空间,就可以存储2^64个元素,这大大节省了内存的存储空间。
hyperloglog的数学原理就是基于伯努利过程,是在同样的条件下重复地、相互独立地进行的一种随机试验。
对于一个数据我们通过计算它的hash值得到二进制01值,然后进行分桶操作,再然后在每个桶中再进行位置的计算,因为通过两次的操作就可以让存储的数据成指数增加,而反过来也就说当我们要存储一定的数据,只需要取两次对数的位数的bit就可以存下,所以这也是hyperloglog的名字由来。
有了hyerploglog,还是统计上面的签到的话,我们的存储空间就大大减小了,当然了这是以牺牲一定的精准度为代价的。
Stream
我们都知道在redis中,我们可以通过list来实现消息队列的功能,但是那只是简单地实现,它缺少持久化的功能,缺少数据复制的功能,而Steam就是为了解决这个问题而产生的。
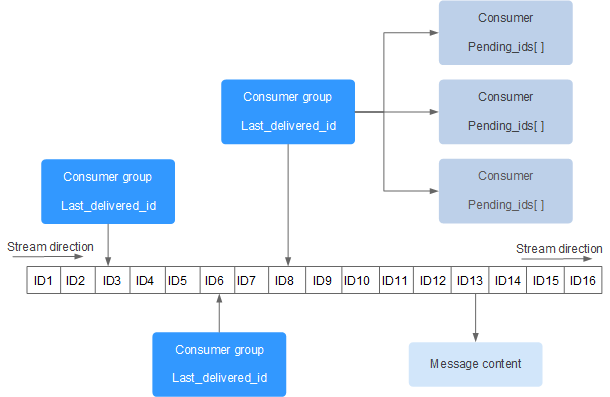
当你觉得rabbitmq过于庞大的时候,那么redis的stream数据结构可以很好地帮助你实现消息队列的几乎全部功能,但是如果你的项目够大,还是请使用正常的消息队列。
GEO
计算2个点的距离我们很容易计算出来,但是如果计算2个地理经纬度坐标点的距离就会变得复杂,如果计算多个点呢?问题就会变得更加复杂,不过这些计算问题,在redis都可以通过GEO来简单实现。
GEO主要是用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。在使用地图的时候,我们经常需要计算得到当前位置一定范围内餐馆,或者影院等建筑物的信息,而通过GEO我们就可以很方便地实现这个功能。
在redis中,通过georadiusbymember这个函数,我们就可以方便地计算出周围点的信息。
总结
相比较string,list,set,sort set, hash这5种结构,你会发现上面介绍的数据结构使用场景很单一,或者说它们的存在主要是为了解决某些特定问题而存在的。
没有哪种数据结构更好的说法,每一种数据结构都有它自己的应用场景,否则它也不会被创造出来。
相关文章
- 运营商大数据:构建城市大脑的智慧基础
- 用数据分析网络暴力有多可怕
- R语言有多强大?十个你不知道的功能
- 小心大数据专业,一哄而上后的“一地鸡毛!”
- 分享一些容易被忽视的Hadoop面试题及答案
- 深度 | 应用架构日趋复杂的今天,如何重构数据库和应用边界?(见文中答案)
- 数据科学的下一个「超能力」:模型可解释性
- 人人都说大数据,那你知道它的核心价值吗?
- 从HDFS和MapReduce两方面了解Hadoop
- 大数据分析师的日常,听起来高大上,其实干的活四个字脏乱差累
- 大数据的技术生态?Hadoop、Hive、Spark之间是什么关系?
- 看待大数据还需“大眼界”?
- 数据分析向云迁移时如何避免混乱
- 预知未来VS确认过去,数据公司的四种模式
- 数据科学岗位将在未来5年内重新洗牌,你准备好转型了吗?
- “老司机”划重点!搞定这120个真实面试问题,杀进数据科学圈
- 大数据方面核心技术有哪些?
- PingCAP CTO 黄东旭:我眼中的未来数据库技术趋势
- 互联网科技企业家两会建言,都在关注哪些方面?
- 6大角度击破数据科学面试套路!助你找到理想工作