
Spark实战电影点评系统(一)
一、通过RDD实战电影点评系统
日常的数据来源有很多渠道,如网络爬虫、网页埋点、系统日志等。下面的案例中使用的是用户观看电影和点评电影的行为数据,数据来源于网络上的公开数据,共有3个数据文件:uers.dat、ratings.dat和movies.dat。
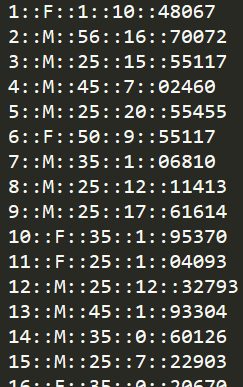
其中,uers.dat的格式如下: UserID::Gender::Age::Occupation::Zip-code ,这个文件里共有6040个用户的信息,每行中用“::”隔开的详细信息包括ID、性别(F、M分别表示女性、男性)、年龄(使用7个年龄段标记)、职业和邮编。
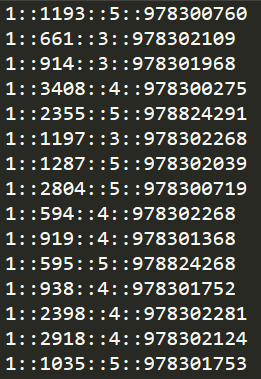
ratings.dat的格式如下: UserID::MovieID::Rating::Timestamp ,这个文件共有一百万多条记录,记录的是评分信息,即用户ID、电影ID、评分(满分是5分)和时间戳。
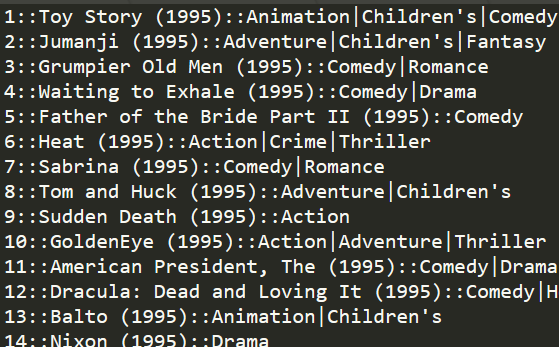
movies.dat的格式如下: MovieID::Title::Genres ,这个文件记录的是电影信息,即电影ID、电影名称和电影类型。
首先初始化Spark,以及读取文件。创建一个Scala的object类,在main方法中配置SparkConf和SparkContext,这里指定程序在本地运行,并且把程序名字设置为“RDD_Movie_Users_Analyzer”。
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD_Movie_User_Analyzer")
/**
* Spark2.0引入SparkSession封装了SparkContext和SQLContext,并且会在builder的getOrCreate方法中判断是否
* 含有符合要求的SparkSession存在,有则使用,没有则进行创建
*/
val spark = SparkSession.builder.config(conf).getOrCreate()
// 获取SparkSession的SparkContext
val sc = spark.sparkContext
// 把Spark程序运行时的日志设置为warn级别,以方便查看运行结果
sc.setLogLevel("WARN")
// 把用到的数据加载进来转换为RDD,此时使用sc.textFile并不会读取文件,而是标记了有这个操作,遇到Action级算子时才回真正去读取文件
val usersRDD = sc.textFile("./src/test1/users.dat")
val moviesRDD = sc.textFile("./src/test1/movies.dat")
val ratingsRDD = sc.textFile("./src/test1/ratings.dat")
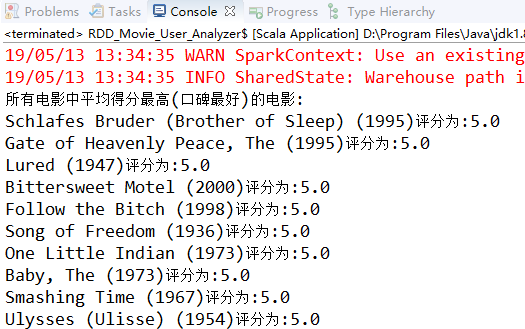
首先我们来写一个案例计算,并打印出所有电影中评分最高的前10个电影名和平均评分。
第一步:从ratingsRDD中取出MovieID和rating,从moviesRDD中取出MovieID和Name,如果后面的代码重复使用这些数据,则可以把它们缓存起来。首先把使用map算子上面的RDD中的每一个元素(即文件中的每一行)以“::”为分隔符进行拆分,然后再使用map算子从拆分后得到的数组中取出需要用到的元素,并把得到的RDD缓存起来
第二步:从ratings的数据中使用map算子获取到形如(movieID,(rating,1))格式的RDD,然后使用reduceByKey把每个电影的总评分以及点评人数算出来。此时得到的RDD格式为(movieID,Sum(ratings),Count(ratings)))。
第三步:把每个电影的Sum(ratings)和Count(ratings)相除,得到包含了电影ID和平均评分的RDD:
第四步:把avgRatings与movieInfo通过关键字(key)连接到一起,得到形如(movieID, (MovieName,AvgRating))的RDD,然后格式化为(AvgRating,MovieName),并按照key(也就是平均评分)降序排列,最终取出前10个并打印出来。
println("所有电影中平均得分最高(口碑最好)的电影:")
val movieInfo = moviesRDD.map(_.split("::")).map(x=>(x(0),x(1))).cache()
val ratings = ratingsRDD.map(_.split("::")).map(x=>(x(0),x(1),x(2))).cache()
val moviesAndRatings = ratings.map(x=>(x._2,(x._3.toDouble,1))).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
val avgRatings = moviesAndRatings.map(x=>(x._1,x._2._1.toDouble/x._2._2))
avgRatings.join(movieInfo).map(item=>(item._2._1,item._2._2))
.sortByKey(false).take(10)
.foreach(record=>println(record._2+"评分为:"+record._1))
接下来我们来看另外一个功能的实现:分析最受男性喜爱的电影Top10和最受女性喜爱的电影Top10。
首先来分析一下:单从ratings中无法计算出最受男性或者女性喜爱的电影Top10,因为该RDD中没有Gender信息,如果需要使用Gender信息进行Gender的分类,此时一定需要聚合。当然,我们力求聚合使用的是mapjoin(分布式计算的一大痛点是数据倾斜,map端的join一定不会数据倾斜),这里是否可使用mapjoin?不可以,因为map端的join是使用broadcast把相对小得多的变量广播出去,这样可以减少一次shuffle,这里,用户的数据非常多,所以要使用正常的join。
使用join连接ratings和users之后,对分别过滤出男性和女性的记录进行处理:
println("========================================")
println("所有电影中最受男性喜爱的电影Top10:")
val usersGender = usersRDD.map(_.split("::")).map(x=>(x(0),x(1)))
val genderRatings = ratings.map(x=>(x._1,(x._1,x._2,x._3))).join(usersGender).cache()
// genderRatings.take(10).foreach(println)
val maleFilteredRatings = genderRatings.filter(x=>x._2._2.equals("M")).map(x=>x._2._1)
val femaleFilteredRatings = genderRatings.filter(x=>x._2._2.equals("F")).map(x=>x._2._1)
maleFilteredRatings.map(x=>(x._2,(x._3.toDouble,1))).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
.map(x=>(x._1,x._2._1.toDouble/x._2._2))
.join(movieInfo)
.map(item=>(item._2._1,item._2._2))
.sortByKey(false)
.take(10)
.foreach(record=>println(record._2+"评分为:"+record._1))
println("========================================")
println("所有电影中最受女性喜爱的电影Top10:")
femaleFilteredRatings.map(x=>(x._2,(x._3.toDouble,1))).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
.map(x=>(x._1,x._2._1.toDouble/x._2._2))
.join(movieInfo)
.map(item=>(item._2._1,item._2._2))
.sortByKey(false)
.take(10)
.foreach(record=>println(record._2+"评分为:"+record._1))

在现实业务场景中,二次排序非常重要,并且经常遇到。下面来模拟一下这些场景,实现对电影评分数据进行二次排序,以Timestamp和Rating两个维度降序排列,值得一提的是,Java版本的二次排序代码非常烦琐,而使用Scala实现就会很简捷,首先我们需要一个继承自Ordered和Serializable的类。
class SecondarySortKey(val first:Double,val second:Double) extends Ordered[SecondarySortKey] with Serializable{
// 在这个类中重写compare方法
override def compare(other:SecondarySortKey):Int={
// 既然是二次排序,那么首先要判断第一个排序字段是否相等,如果不相等,就直接排序
if(this.first-other.first!=0){
(this.first-other.first).toInt
}else {
// 如果第一个字段相等,则比较第二个字段,若想实现多次排序,也可以按照这个模式继续比较下去
if(this.second-other.second>0){
Math.ceil(this.second-other.second).toInt
}else if (this.second-other.second<0) {
Math.floor(this.second-other.second).toInt
}else {
(this.second-other.second).toInt
}
}
}
}
然后再把RDD的每条记录里想要排序的字段封装到上面定义的类中作为key,把该条记录整体作为value。
println("========================================")
println("对电影评分数据以Timestamp和Rating两个维度进行二次降序排列:")
val pairWithSortkey = ratingsRDD.map(line=>{
val spilted = line.split("::")
(new SecondarySortKey(spilted(3).toDouble,spilted(2).toDouble),line)
})
// 直接调用sortByKey,此时会按照之前实现的compare方法排序
val sorted = pairWithSortkey.sortByKey(false)
val sortedResult = sorted.map(sortedline => sortedline._2)
sortedResult.take(10).foreach(println)
取出排序后的RDD的value,此时这些记录已经是按照时间戳和评分排好序的,最终打印出的结果如图所示,从图中可以看到已经按照timestamp和评分降序排列了。
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地