
不同的SQL平台,如何取前百分之N的记录?
最近帮业务部门梳理业务报表,其中有个需求是就算某指标等待时间最长的前百分之十,其实就是对等待时长进行倒序排序后,取结果集的前百分之十。

这个需求在SQL Server和Oracle上都很容易实现,甚至是在MySQL 8.0也很容易实现,只是恰好我们业务数据库是MySQL 5.7
先给大家介绍下不同数据库平台的实现方法。
SQL Server实现方法
SQL Server上有个TOP Percent的方法可以直接取结果的前(或后)百分之N例如有如下一张City表
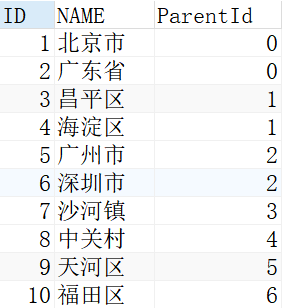
我们取前10%的数据记录可以这样写:
- SELECT
- TOP 10 PERCENT
- *
- FROM City
- ORDER BY ID DESC
结果如下:
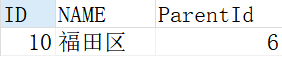
Oracle实现方法
Oracle有个ROWNUM伪列可以用来帮助我们计算前百分之N。ROWNUM伪列的特点:
- ROWNUM是按照记录插入时的顺序排序的
- ROWNUM并不实际存在,是对筛选后的结果集的一个排序,如果不存在结果集就不会有ROWNUM
- ROWNUM不能用基表名作为前缀
- 在使用ROWNUM进行查询时,请注意:
1)若使用大于号(>),则只能使用(>0),其他均不可以 2)若使用小于号(<),同一般情况 3)若使用等于号(=),则只能使用等于1(=1)我们可以先计算出整个表的记录行数量
- SELECT COUNT(*) CNT FROM City
然后根据count聚合查询总条数乘以百分比,来确定要查询的条数
- SELECT 0.1*COUNT(*) CNT FROM City
最后取出伪列小于共有数据的百分比的数据
- SELECT * FROM CITY
- WHERE ID IN
- (
- SELECT ID FROM
- (
- SELECT ID FROM CITY ORDER BY ID DESC
- )
- WHERE ROWNUM < (SELECT COUNT(*)*0.1 FROM CITY)
- )
注意:Oracle不支持子查询内ORDER BY,需要在外面再嵌套一层。
MySQL 8.0的实现方法
MySQL 8.0的实现方法主要是借助窗口函数ROW_NUMBER() OVER()。其实就是给排好序的集合添加一个自增长列,与Oracle的ROWNUM有点类似
- SELECT * FROM
- (
- SELECT *,
- ROW_NUMBER() OVER(ORDER BY ID DESC) rn
- FROM City
- ORDER BY ID DESC
- ) a
- WHERE a.rn<=(SELECT 0.1*COUNT(*) FROM City)
MySQL 5.X的实现方法
我们知道MySQL 5.X是没有开窗函数ROW_NUMBER() OVER()的,那该如何实现呢?
这里我们需要借助变量来实现,其实思路还是创建一个自增长列,只是方法不同。
- SELECT
- A.*,
- @row_num:=@row_num+1 AS ROW_NUM
- FROM
- City A , (SELECT @row_num:=0) B
- ORDER BY ID DESC
这样我们就可以得到一张有自增长列的结果集了,接下来还是按照上面类似的方法,取前10%即可。
- SELECT * FROM
- (
- SELECT
- A.*,
- @row_num:=@row_num+1 AS ROW_NUM
- FROM
- City A , (SELECT @row_num:=0) B
- ORDER BY ID DESC
- ) C
- WHERE C.ROW_NUM<=(@row_num*0.1)
其实MySQL 5.X也挺简单的,只是当时不怎么想用变量,想看看有没有其他办法,最后发现还是得用变量
以上就是不同平台的数据库求前百分之N的方法了,代码可以验证一下收藏起来留着下次直接套用。
总结
其中有涉及一些知识点,需要小伙伴们自己去进一步了解:
- SQL Server的TOP PERCENT
- Oracle的ROWNUM,子查询排序
- ROW_NUMBER() OVER()
- MySQL的变量
相关文章
- SRA数据几种常用的下载方法
- Kafka快速入门(介绍)
- Kafka快速入门(安装集群)
- Kafka快速入门(命令行操作)
- Kafka快速入门(生产者)同步异步发送、分区、消息精确一次发送、幂等性、事务
- 验证Apache log4j漏洞是否存在
- Kafka快速入门(Kafka Broker)节点服役和退役、手动调整副本
- Kafka快速入门(Kafka消费者)
- Redis 简介
- Docker安装Kafka(docker-compose)、EFAK监控
- SpringBoot-Kafka(生产者事务、手动提交offset、定时消费、消息转发、过滤消息内容、自定义分区器、提高吞吐量)
- 多个单细胞样本数据的循环读取
- 云监控 Barad 的云原生实践
- 植物的单细胞数据如何过滤线粒体基因
- JUC-Java多线程Future,CompletableFuture
- ? MySQL事务日志 undo log 详解
- SpringBoot 如何统计、监控 SQL运行情况?
- 使用Sharding-JDBC 实现Mysql读写分离
- HBase 简介
- HBase 快速入门(安装和命令操作)