
【消息中间件】Redis vs Kafka vs RabbitMQ
对微服务使用异步通信时,通常使用消息代理。代理确保不同微服务之间的通信可靠且稳定,消息在系统内得到管理和监控,并且消息不会丢失。您可以从几个消息代理中进行选择,它们的规模和数据功能各不相同。这篇博文将比较三种最受欢迎的代理:RabbitMQ、Kafka 和 Redis。
微服务通信:同步和异步
微服务之间有两种常见的通信方式:同步和异步。在同步通信中,调用者在发送下一条消息之前等待响应,它作为 HTTP 之上的 REST 协议运行。相反,在异步通信中,消息是在不等待响应的情况下发送的。这适用于分布式系统,通常需要消息代理来管理消息。
您选择的通信类型应考虑不同的参数,例如您如何构建微服务、您拥有的基础设施、延迟、规模、依赖关系和通信目的。异步通信的建立可能更复杂,需要向堆栈中添加更多组件,但对微服务使用异步通信的优点大于缺点。
异步通信优势
首先,异步通信根据定义是非阻塞的。它还支持比同步操作更好的扩展。第三,在微服务崩溃的情况下,异步通信机制提供了各种恢复技术,并且通常更擅长处理与崩溃有关的错误。此外,当使用代理而不是 REST 协议时,接收通信的服务实际上不需要相互了解。甚至可以在旧服务运行很长时间后引入新服务,即更好的解耦服务。
最后,在选择异步操作时,您可以提高未来创建中央发现、监控、负载平衡甚至策略执行器的能力。这将为您的代码和系统构建提供灵活性、可扩展性和更多功能。
选择正确的消息代理
异步通信通常通过消息代理进行管理。还有其他方法,例如 aysncio,但它们更加稀缺和有限。
在选择代理来执行异步操作时,您应该考虑以下几点:
Broker Scale — 系统中每秒发送的消息数。
数据持久性——恢复消息的能力。
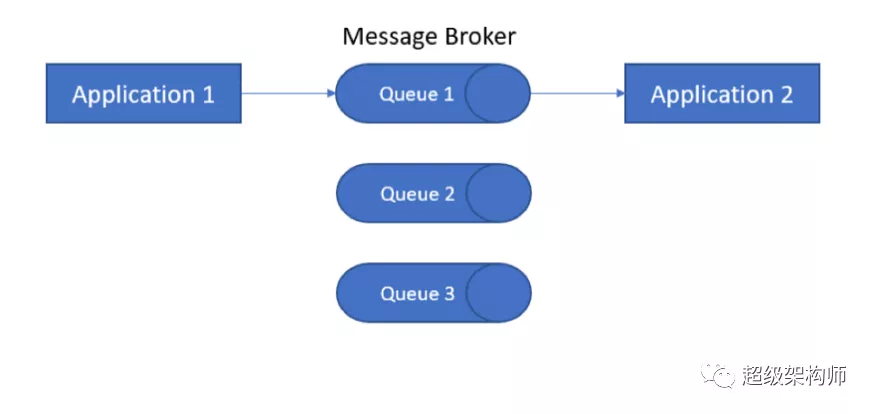
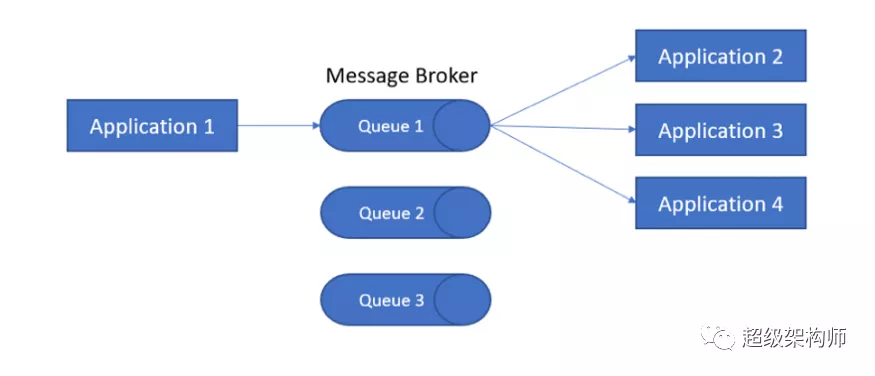
消费者能力——经纪人是否能够管理一对一和/或一对多的消费者。
一对一
一对多
我们检查了最新和最好的服务,以找出这三个类别中最强大的提供商。
比较不同的消息代理
RabbitMQ (AMQP)
规模:
根据配置和资源,这里的大概是每秒 50K msg。
持久性:
支持持久性和瞬态消息。
一对一与一对多消费者:
两者兼而有之。
RabbitMQ 于 2007 年发布,是最早创建的通用消息代理之一。它是一个开源软件,通过实现高级消息队列协议 (AMQP),通过点对点和发布-订阅方法传递消息。它旨在支持复杂的路由逻辑。
有一些托管服务允许您将其用作 SaaS,但它不是本地主要云提供商堆栈的一部分。RabbitMQ 支持所有主要语言,包括 Python、Java、.NET、PHP、Ruby、JavaScript、Go、Swift 等。
在持久模式下会出现一些性能问题。
卡夫卡
规模:
每秒最多可以发送一百万条消息。
持久化:
是的。
一对一 vs 一对多消费者:
只有一对多(乍一看似乎很奇怪,对吧?!)。
Kafka 由 Linkedin 于 2011 年创建,用于处理高吞吐量、低延迟的处理。作为分布式流媒体平台,Kafka 复制了发布订阅服务。它提供数据持久性并存储记录流,使其能够交换质量消息。
Kafka 在 Azure、AWS 和 Confluent 上管理了 SaaS。他们都是Kafka项目的创造者和主要贡献者。Kafka 支持所有主要语言,包括 Python、Java、C/C++、Clojure、.NET、PHP、Ruby、JavaScript、Go、Swift 等。
Redis
规模:
每秒最多可以发送一百万条消息。
持久性:
基本上,没有——它是一个内存中的数据存储。
一对一与一对多消费者:
两者兼而有之。
Redis 与其他消息代理略有不同。从本质上讲,Redis 是一种内存中数据存储,可用作高性能键值存储或消息代理。另一个区别是 Redis 没有持久性,而是将其内存转储到磁盘/数据库中。它也非常适合实时数据处理。
最初,Redis 不是一对一和一对多的。然而,自从 Redis 5.0 引入了 pub-sub,功能得到了提升,一对多成为了一个真正的选择。
每个消息代理的用例
我们介绍了 RabbitMQ、Kafka 和 Redis 的一些特性。这三者都是同类中的野兽,但正如所描述的,它们的运作方式大不相同。以下是我们针对不同用例使用的正确消息代理的建议。
短命消息:Redis
Redis 的内存数据库几乎非常适合具有不需要持久性的短期消息的用例。因为它提供极快的服务和内存中的功能,Redis 是短保留消息的完美候选者,在这种情况下,持久性不是那么重要,您可以容忍一些损失。随着 5.0 中 Redis 流的发布,它也是一对多用例的候选者,由于限制和旧的 pub-sub 功能,这是绝对需要的。
海量数据:Kafka
Kafka 是一个高吞吐量的分布式队列,专为长时间存储大量数据而构建。Kafka 非常适合需要持久性的一对多用例。
复杂路由:RabbitMQ
RabbitMQ 是一个较旧但成熟的代理,具有许多支持复杂路由的特性和功能。当要求的速率不高(超过几万条消息/秒)时,它甚至会支持复杂的路由通信。
考虑您的软件堆栈
当然,最后要考虑的是您当前的软件堆栈。如果您正在寻找一个相对简单的集成过程,并且您不想在一个堆栈中维护不同的代理,您可能更倾向于使用您的堆栈已经支持的代理。
例如,如果您在 RabbitMQ 之上的系统中使用 Celery for Task Queue,您将有动力使用 RabbitMQ 或 Redis,而不是 Kafka,后者不受支持并且需要一些重写。
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地