
当前栏目
一篇文章带你了解Django ORM操作(高端篇)

前言
上次两篇基本学完的Django ORM各种操作,怎么查,各种查。感兴趣的小伙伴可以戳这两篇文章学习下,一篇文章带你了解Django ORM操作(进阶篇)、一篇文章带你了解Django ORM操作(基础篇)。
但是还是遗留了一些技能。,再来瞅瞅吧!
查询
聚合操作
聚合操作,不要被名字吓到了,通常用在筛选完一些数据之后,求一下平均值了,什么的。
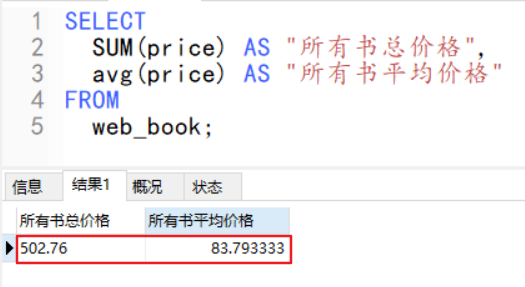
例如:求所有书的总价格和平均价格
原生sql
- SELECT
- SUM(price) AS "所有书总价格",
- avg(price) AS "所有书平均价格"
- FROM
- web_book;
T SUM(price) AS "所有书总价格", avg(price) AS "所有书平均价格"FROMweb_book;
执行结果
ORM
- price = models.Book.objects.all().aggregate(Sum("price"),Avg("price"), )
- print(price)
执行结果

可以发现和上面是一样的,但是会发现列名是默认是字段__聚合函数名。
原生sql是可以指定显示的列名的,同样,ORM也可以。
代码
- # 需要导入的包
- from django.db.models import Avg,Sum
- price = models.Book.objects.all().aggregate(所有书总价格=Sum("price"), 所有书平均价格=Avg("price"), )
- print(price)
执行结果

注:price的类型直接就是dict,所以,在这是不能查看原生sql的。
但是上述ORM对应的原生SQL确实如上,所以那样理解就行了。
分组操作
分组操作,就是将某一列,相同的值进行压缩,然后就可以得出压缩值的数量。
如果压缩的是外键,还可以取出外键的详细信息。
示例:查询出每个出版社出版的数量。
通过研究表结构发现,每出版的书,都在book表中记录,并且每本书会外键一个出版社id。
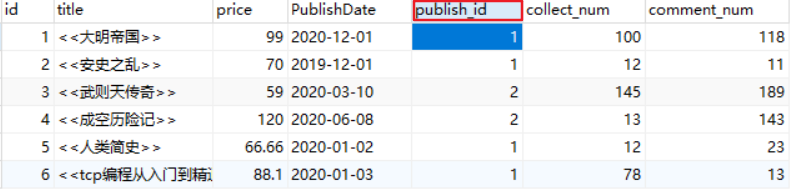
如果我们能对出版社id进行压缩,然后再求出压缩出版社id里面对应的数量。
啧啧,这不就出来了吗?
代码
- from django.db.models import Count
- ret = models.Book.objects.values("publish_id").annotate(publish_count=Count("publish_id"))
- print(ret)
执行结果

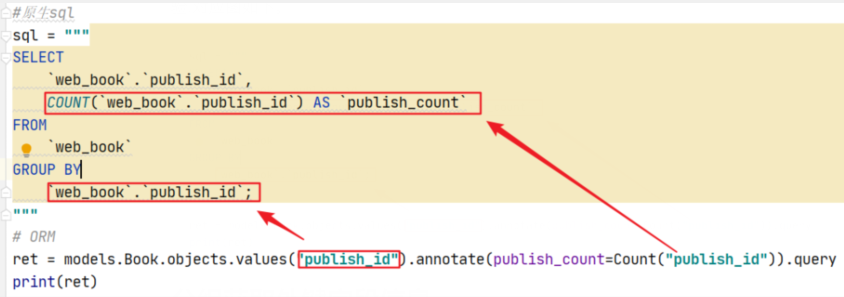
原生sql
- SELECT
- `web_book`.`publish_id`,
- COUNT(`web_book`.`publish_id`) AS `publish_count`
- FROM
- `web_book`
- GROUP BY
- `web_book`.`publish_id`;
ORM分组和原生SQL对应图
这一块,我记得当初我迷茫了一段时间,主要是不知道如何和原生SQL对应上,根据多次测试经验,对应图如下。
分组获取外键字段信息
上述确实可以通过分组实现了功能。
但是上述只能获取出版社id,并不能获取出版社名啥的,但是如何获取压缩外键字段详细信息呢?
代码
- ret = models.Book.objects.values("publish_id").annotate(publish_count=Count("publish_id")).values("publish__title","publish__phone","publish_count")
- print(ret)
执行结果

注:分组(annotate)后面跟的values。
里面只能写外键字段的列和annotate里面的列,不能写其他。
如果分组分的不是外键字段,那就不能再跟values!
分组再筛选
分组再筛选本质就是原生sql的group by .. having,将压缩完的数据在进行条件判断。
但是对压缩的数据进行判断只能通过having。
示例:查询出版社出版的书大于2本的数据。
代码
- ret = models.Book.objects.values("publish_id") \
- .annotate(publish_count=Count("publish_id")) \
- .filter(publish_count__gt=2)
- print(ret)
执行结果

F查询
有时候,我们可能有这样的需求,就是两个列之间进行比较。
比如经典问题,一个商品,找到收藏数大于销量的商品等之类的两列进行比较的需求。
示例:查询book表,评论数小于收藏数的数据。
代码
- from django.db.models import F
- book = models.Book.objects.filter(comment_num__lt=F("collect_num"))
- print(book)
实际结果
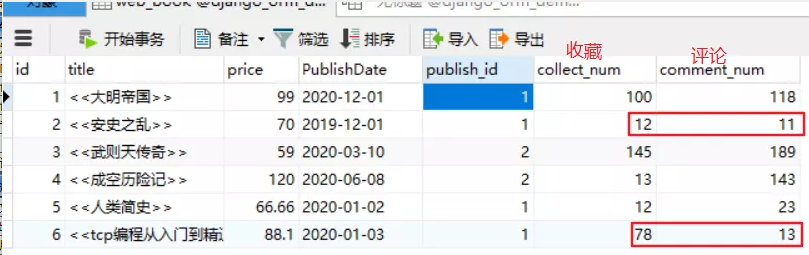
执行结果

F对象还支持加减乘除后的比较
示例:评论数小于两倍收藏数的数据。
代码
可是*,也可以是-,+,÷
- from django.db.models import F
- book = models.Book.objects.filter(comment_num__lt=F("collect_num")*2)
- print(book)
执行结果

F对象还适用于更新
代码
- models.Book.objects.all().update(price=F("price")+30)
Q查询
通常情况下,我们使用的filter(条件1,条件2,...),执行的都是and查询。
但是通常一些时候,我们需要执行or查询。
比如book表,查询title=<<大明帝国>> or title=<<安史之乱>>的。
这时候,如果使用Django ORM,就只能使用Q查询构建条件。
代码
- from django.db.models import Q
- books = models.Book.objects.filter(Q(title="<<大明帝国>>") | Q(title="<<安史之乱>>"))
- print(books)
执行结果

注:|是or的意思,&是and的意思。
所以,如果将上述的|换成&,filter(条件1,条件2,...)一个意思,还是and。
Q查询之~
~相当于not。
示例:查询title = "<<大明帝国>>" or title != "<<安史之乱>>"。
代码
- from django.db.models import Q
- books = models.Book.objects.filter(Q(title="<<大明帝国>>") | ~Q(title="<<安史之乱>>"))
- print(books)
执行结果

Q查询和and混合查询
Q查询和and查询同时出现,Q查询必须在其他查询之前。
示例:查询title = "<<大明帝国>>" or title != "<<安史之乱>>" 并且publish_id=1的。
代码
- from django.db.models import Q
- books = models.Book.objects.filter(Q(title="<<大明帝国>>") | ~Q(title="<<安史之乱>>"),publish_id=1)
- print(books)
执行结果

动态构造Q查询
一些时候,我们可能并不太确定有什么条件。
可能是动态传的,传过来多少,就拼接多少。
Q查询,就能做到这个,在做动态Q查询时,动态Q不仅支持or,还支持and。
示例:查询publish_id=1或者title模糊=大明 的书。
代码
- q = Q()
- # 查询方式,or还是and
- q.connector = "or" # or,and
- # publish_id=1
- q.children.append(("publish_id", "1"))
- # title__contains="大明"
- q.children.append(("title__contains", "大明"))
- books = models.Book.objects.filter(q)
- print(books)
执行结果

增
上面说了那么多,终于算是大概说完了,来简单看一下怎么添加一条数据吧。
示例:添加一本书
代码
方式一,通过objects.create。
这种方式用的最多。
- models.Book.objects.create(
- title="<<人类简史2>>",
- price=66.66,
- PublishDate="2020-01-02",
- comment_num=23,
- collect_num=12,
- # 外键字段 django models对应的mysql 为 字段_id
- publish_id=1,
- # publish字段需要是一个 Publish 对象
- # publish=models.Publish.objects.filter(id=1)
- )
方式二,通过model对象.save()。
- book_obj = models.Book(
- title="<<人类简史2>>",
- price=66.66,
- PublishDate="2020-01-02",
- comment_num=23,
- collect_num=12,
- # 外键字段 django models对应的mysql 为 字段_id
- publish_id=1, )
- book_obj.save()
方式三,通过字典方式。
可能有的时候,我们正好将传过来的参数构造成了一个字典,那就太好了,不需要再一个个取。
- c_dict = {
- "title":"<<tcp编程从入门到精通2>>",
- "price":88.1,
- "PublishDate":"2020-01-03",
- "comment_num":13,
- "collect_num":78,
- "publish_id":1,
- }
- models.Book.objects.create(**c_dict)
更新
注:update只能跟在在filter之后。
示例:将title="<<大明帝国>>"的数据修改为title="<<大明帝国666>>"。
代码
- models.Book.objects.filter(title="<<大明帝国>>").update(title="<<大明帝国666>>")
filter可能筛选到的是多个值,一定要注意
删除
delete只能跟在filter之后。
示例:删除title=<<大明帝国666>>的数据。
- models.Book.objects.filter(title="<<大明帝国666>>").delete()
总结
好了各位,到此为止,基本上,Django ORM操作基本完毕,至少80%的知识都覆盖完毕。
本篇主要补充的是一些高端操作,例如聚合操作,分组操作,分组再筛选操作,F查询和Q查询。
如何动态构造Q查询。
相对来说,Django还是自由度比价高的,而且写起来确实比较省心。
用微笑告诉别人,今天的我比昨天强,今后也一样。

相关文章
- 鲜为人知但很有用的 HTML 属性
- 翻转再翻转!有意思的水平横向溢出滚动
- 自定义计数器小技巧!CSS 实现长按点赞累加动画
- 过五关!React高频面试题指南
- 软件开发中的十个认知偏差
- 不需要 JS!仅用 CSS 也能达到监听页面滚动的效果!
- 一文读懂TypeScript类型兼容性
- Vue 的响应式原则与双向数据绑定
- 快速掌握 TypeScript 新语法:Infer Extends
- JWT教你如何证明你是我的人!
- 一篇带给你 V8 GC 的实现
- 面试官:请使用JS完成一个LRU缓存?
- 通过可视化来学习JavaScript事件循环
- 新的跨域策略:使用 COOP、COEP 为浏览器创建更安全的环境
- 为什么有人说 vite 快,有人却说 vite 慢?
- 种草 Vue3 中几个好玩的插件和配置
- 超全面的前端工程化配置指南
- Vue 状态管理未来样子
- Volatile关键字能保证原子性么?
- 面试突击:SpringBoot 有几种读取配置文件的方法?