
数据库开发应知应会之笛卡尔积
2023-03-14 09:31:30 时间
很多数据库开发人员都听说过笛卡尔积的概念,也可能偶尔碰上过因为SQL语句或者数据表数据问题而产生的笛卡尔积问题。但是很多人对于笛卡尔积产生的原因和如何避免还是有些一知半解。所以我们今天就简单明了地给大家介绍一下什么情况下会产生笛卡尔积问题,以及如何避免。
一、什么是笛卡尔积
笛卡尔积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
假设集合A={a, b}有两个元素,集合B={0, 1, 2}有三个元素,则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}有2*3为6个元素。
在SQL查询语句中,出现笛卡尔积的情况都是出现在关联查询上,具体包括下面两种。我们以下面两张表为例,给大家介绍一下。
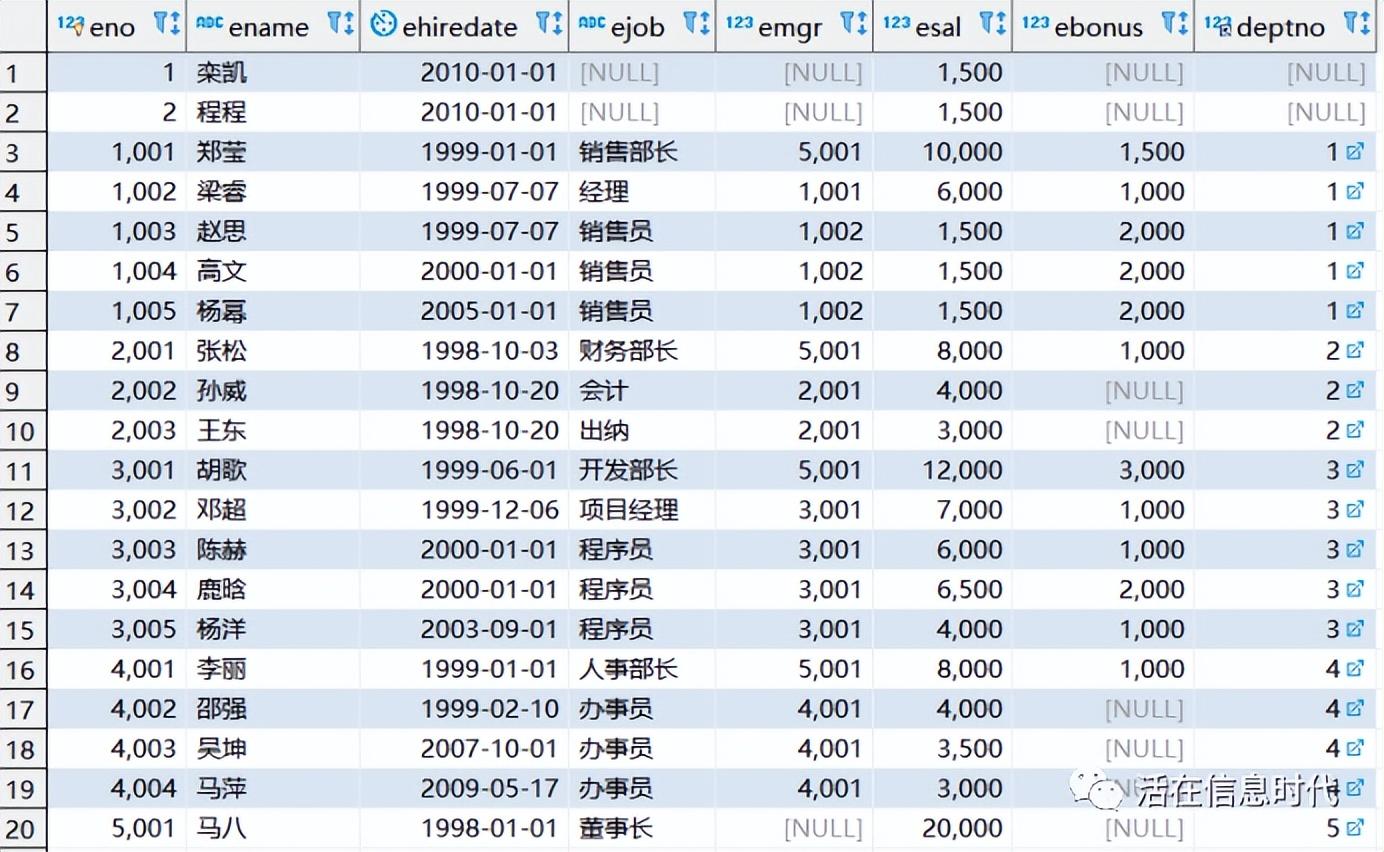
第一张表是雇员表:有20条数据,如下图:
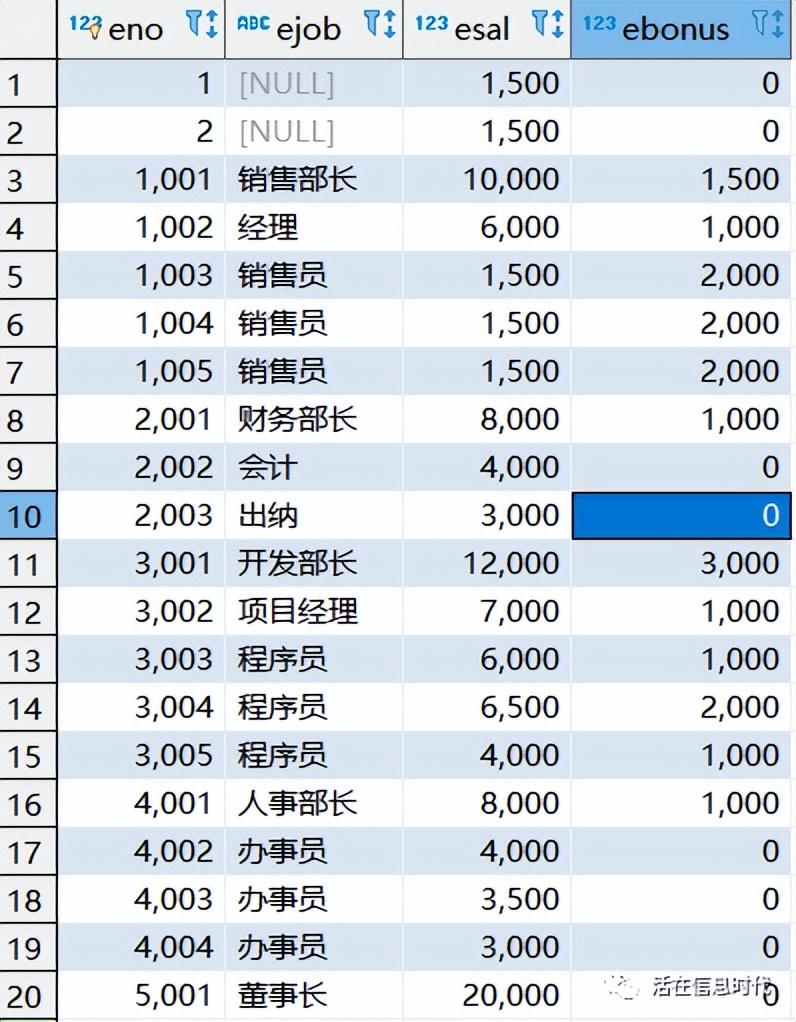
第二张表为工资表:也有二十条数据,如下图:
二、数据表关联查询时,如果连接没有ON条件,会出现全部笛卡尔积
对于以上的两张表,如果我们查询
结果为:
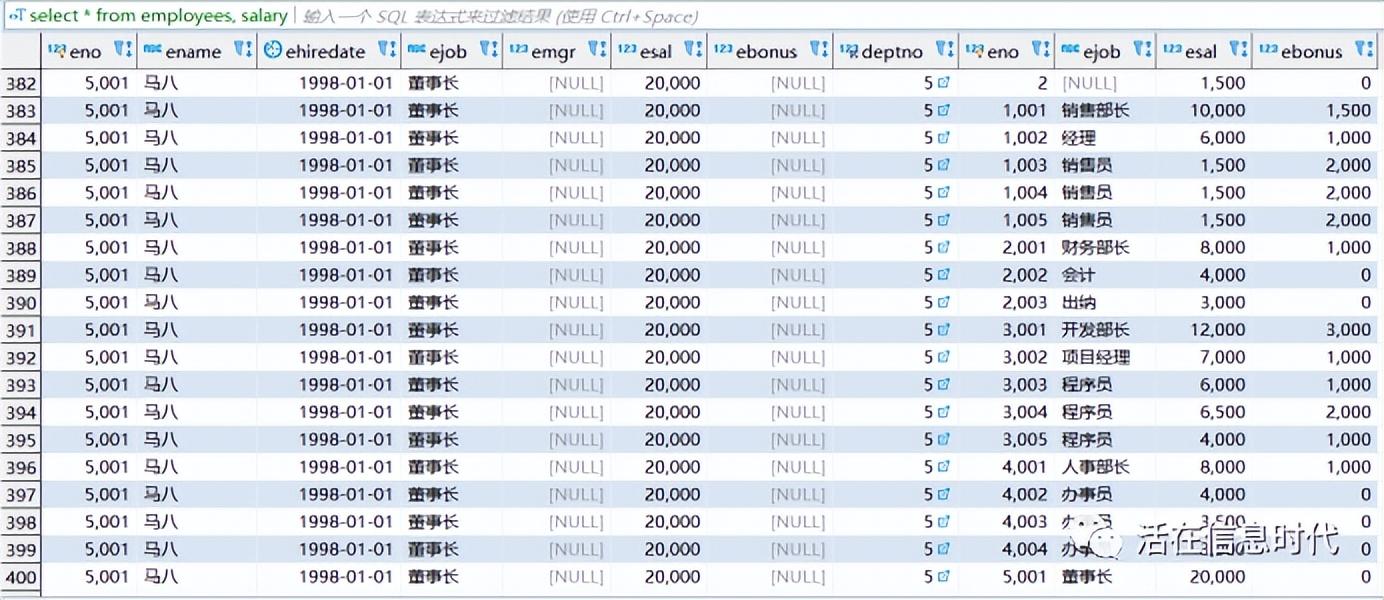
可以看出,一共出现了20*20=400条数据。即出现了全部笛卡尔积。
三、数据表关联查询时,如果ON条件字段是非唯一字段,会出现部分笛卡尔积
以上面的数据为例,如果我们以ejob字段进行连接的话,语句如下:
结果为:
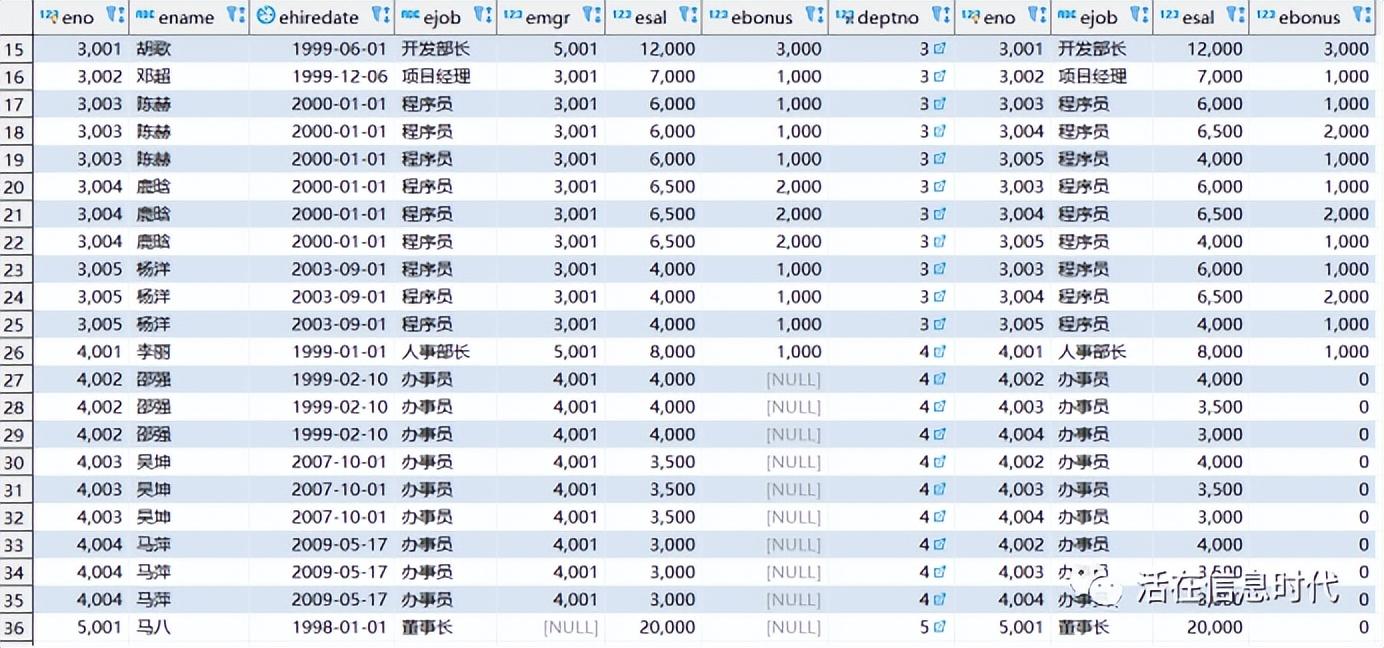
可以看出,由于ejob不是唯一字段,最终出现了36条结果,也就是出现了部分笛卡尔积。
四、如何才能不出现笛卡尔积的查询结果
为避免出现查询结果为笛卡尔积的冗余数据情况,应该在连接查询时,使用唯一字段进行连接。
相关文章
- 用Pandas处理大数据——节省90%内存消耗的小贴士
- 2018全球大数据产业将呈七大发展趋势
- 干货分享:数据分析的六大黄金法则
- 从大数据的角度看:年货变迁、消费升级和财富效应
- 玩转大数据可视化的几个必会工具
- 自建Hadoop集群迁移到EMR之数据迁移篇
- 科普帖:五分钟快速了解大数据及其必备技能
- Apache Spark中的决策树
- 大数据预测,是玄学还是科学?
- 云时代背景下,数据中心的位置仍然为王
- Tech Neo技术沙龙第18期专题回顾 ——智能化运维发展趋势(含视频、PPT)
- 基于Hadoop生态SparkStreaming的大数据实时流处理平台的搭建
- 数据分析会带来意想不到的好处
- 55个实用的大数据可视化分析工具!
- 大数据其实没那么有用,但是炒作它的人确实是都赚钱了
- 用数据目录解决数据蔓延的问题
- Facebook如何运用机器学习进行十亿级用户数据处理
- 足球比赛中的实时数据是如何统计出来的?人工 or 人工智能?
- Hadoop 3.0: YARN Resource自定义资源配置说明
- 大数据处理为何选择Spark,而不是Hadoop