
HarmonyOS Sample之AI能力之NLU引擎服务

1.介绍
NLU(the natural language understanding)自然语言理解引擎服务。
该引擎服务提供了 分词、词性标注、实体识别、意图识别、关键词提取等接口,有同步和异步两种方法。
这一期的内容包括:分词能力、词性标注、关键字提取、实体识别。相关代码都增加了注释说明和调试日志,方便理解和学习。
2.效果展示

3.搭建环境
安装DevEco Studio,详情请参考DevEco Studio下载。
设置DevEco Studio开发环境,DevEco Studio开发环境需要依赖于网络环境,需要连接上网络才能确保工具的正常使用,可以根据如下两种情况来配置开发环境:
如果可以直接访问Internet,只需进行下载HarmonyOS SDK操作。
如果网络不能直接访问Internet,需要通过代理服务器才可以访问,请参考配置开发环境。
下载源码后,使用DevEco Studio 打开项目,模拟器运行即可。
真机运行需要将config.json中的buddleName修改为自己的,如果没有请到AGC上进行配置,参见 使用模拟器进行调试 。
4.项目结构
5.代码讲解
5.1 分词能力(getWordSegment)
分词API的主要功能是将一个汉字序列切分成一个一个单独的词,可自定义分词的粒度。
场景:1.搜索引擎开发场景,搜索结果的相关度排序;2.用户选择用户选择文本的场景,例如双击选择分本时,按照分词进行选中等。
5.1.1 核心类
- import ohos.ai.nlu.NluClient; //提供调用自然语言理解 (NLU) 引擎服务的方法。
- import ohos.ai.nlu.NluRequestType; //定义调用 NLU 引擎功能的请求类型。
- import ohos.ai.nlu.ResponseResult; //以JSON格式提供NLU识别结果。
5.1.2 使用流程
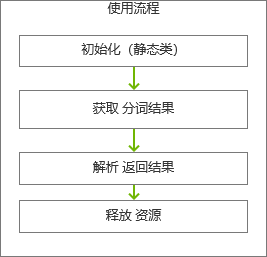
1.NluClient静态类进行初始化
- NluClient.getInstance().init(Context context,
- OnResultListener<Integer> listener,boolean isLoadModel)
2.获取分词结果
- // 1.同步接口
- ResponseResult responseResult =
- NluClient.getInstance().getWordSegment(requestData,NluRequestType.REQUEST_TYPE_LOCAL);
- //2.异步接口
- NluClient.getInstance()
- .getWordSegment(requestData,NluRequestType.REQUEST_TYPE_LOCAL,
- asyncResult -> {
- //发送分词结果
- sendResult(asyncResult.getResponseResult(), 0);
- release();
- });
requestData:JSON格式,参数名包括{text,type,callPkg,callType,callVersion,callState},其中,
text:待分析的文本,必填项;
type:分词的粒度,枚举值,0:基本词 ;1:在基本词的基础上,做实体合并;223372036854775807:在type为1的基础上,把实体时间、地点等整体结构合并,出现符号隔开不合并,并把一些常用短语合并,默认为0。
requestType: 枚举值,NluRequestType.REQUEST_TYPE_LOCAL 表示调用本地引擎。
3.解析返回结果
ResponseResult responseResult 返回JSON格式字符串,JSON格式,参数名包括:{code,message,words}
- //{"code":0,"message":"success","words":["我","明天","下午","三点",
- //"要","去","江宁万达广场","看","速度","与","激情"]}
- // 将分词结果转换成list
- if (result.contains("\"message\":\"success\"")) {
- switch (operateType) {
- //分词
- case 0:
- String words = result.substring(result.indexOf(WORDS) + STEP,
- result.lastIndexOf("]")).replaceAll("\"", "");
- if ((words == null) || ("".equals(words))) {
- // 未识别到分词结果,返回"no keywords"
- lists = new ArrayList<>(1);
- lists.add("no keywords");
- } else {
- lists = Arrays.asList(words.split(","));
- }
- //构建事件
- event = InnerEvent.get(TWO, ZERO, lists);
- }
- }
4.释放资源
- NluClient.getInstance().destroy(slice);
5.1.3 分词粒度测试
- type=0
- requestData:{“text”:我明天下午三点要去江宁万达广场看速度与激情,“type”:0}
- 分词结果:
- {“code”:0,“message”:“success”,“words”:
- [“我”,“明天”,“下午”,“三点”,“要”,“去”,“江宁万达广场”,“看”,“速度”,“与”,“激情”]}
- type=1
- requestData:{“text”:我明天下午三点要去江宁万达广场看速度与激情,“type”:1}
- 分词结果:
- {“code”:0,“message”:“success”,“words”:
- [“我”,“明天”,“下午”,“三点”,“要”,“去”,“江宁万达广场”,“看”,“速度与激情”]}
- type=9223372036854775807
- requestData:{“text”:我明天下午三点要去江宁万达广场看速度与激情,“type”:9223372036854775807}
- 分词结果:
- {“code”:0,“message”:“success”,“words”:
- [“我”,“明天下午三点”,“要去”,“江宁万达广场”,“看”,“速度与激情”]}
5.2 词性标注(getWordPos)
词性标注提供了getWordPos()接口,该接口可以根据分词粒度,为分词结果中的每个单词标注一个正确的词性。
5.2.1 用法
用法和分词能力类似,获取词性标注的接口是getWordPos(),传入的requestData参数和返回对象ResponseResult都是一样的。
- ResponseResult responseResult =
- NluClient.getInstance().getWordPos(requestData, NluRequestType.REQUEST_TYPE_LOCAL);
5.2.2 词性标注结果
requestData:
- {"text":"我明天下午三点要去江宁万达广场看速度与激情","type":0}
responseResult:
- {"code":0,"message":"success","pos":[
- {"word":"我","tag":"rr"},
- {"word":"明天","tag":"t"},
- {"word":"下午","tag":"t"},{"word":"三点","tag":"t"},{"word":"要","tag":"v"},{"word":"去","tag":"vf"},
- {"word":"江宁万达广场","tag":"n"},{"word":"看","tag":"v"},{"word":"速度","tag":"n"},{"word":"与","tag":"cc"},{"word":"激情","tag":"n"}
- ]}
词性:rr:人称代词,t:时间词,v:动词,vf:趋向动词,n:名词,cc:并列连词
tag词性值就不一一列举了,详情查看
https://developer.harmonyos.com/cn/docs/documentation/doc-guides/ai-pos-tagging-guidelines-0000001050732512
5.3 提取关键词(getKeywords)
关键字提取API提供了一个提取关键字的接口,通过该API可以在大量信息中提取出文本想要表达的核心内容,可以是具有特定意义的实体,如:人名,地点,电影等。也可以是一些基础但是在文本中很关键的词汇。通过该API可以对提取的关键字按照在文本中所占权重由高到低排序。排序越靠前,权重越高,对文本的核心内容的提取越准确。
5.3.1 用法
用法和分词能力类似,提取关键词接口是getKeywords(),requestData输入数据的JSON 格式参数有所变化 {body,number,title}
body:要分析文本,必选,如新闻或email内容或文章;
number:提取关键词个数,必选;title: 内容标题,可选
- ResponseResult responseResult =
- NluClient.getInstance().getKeywords(requestData, NluRequestType.REQUEST_TYPE_LOCAL);
5.3.2 提取关键词结果展示
requestData:
- {"body":"对接各资源服务中心接入卫健、医保、人社、民政等横向单位数据,逐步完善和丰富退役军人健康档案信息","number":5,"title":"退役军人"}
- 1.
- 1.
- 1.
- 1.
responseResult:
- {"keywords":["退役","军人","卫健","医保","对接"],"code":0,"message":"成功"}
5.4 实体识别(getEntity)
实体识别能够从自然语言中提取出具有特定意义的实体,并在此基础上完成搜索等一系列相关操作及功能。
5.4.1 用法
用法和分词能力类似,获取实体识别的接口是getEntity(),requestData输入数据的JSON 格式参数有所变化 {text,module,callPkg,callType,callVersion,callState}
text:分析文本,必选,如新闻或email内容;
module:需要分析的实体,可选,默认所有实体均会分析。
分析某个实体,传实体键值,例如:只需要分析时间实体,传“time”。可传多个,表示分析多个实体,以半角逗号“,”分隔,例如:分析时间和地点,传“time,location”。
取值范围:name、time、location、phoneNum、email、url、movie、tv、anime、league、team、trainNo、flightNo、expressNo、idNo、verificationCode、app、carNo
- ResponseResult responseResult =
- NluClient.getInstance().getEntity(requestData, NluRequestType.REQUEST_TYPE_LOCAL);
5.4.2 分析实体结果展示
requestData:
- {"text":"我明天下午三点要去江宁万达广场看速度与激情"}
responseResult:
- {
- "entity": {
- "movie": [{
- "oriText": "速度与激情",
- "sequence": 1,
- "origin": "1637301307158",
- "heat": 0,
- "standardName": "速度与激情",
- "charOffset": 16,
- "normalValue": "速度与激情",
- "user.extend": false,
- "isCorrected": false
- }],
- "location": [{
- "sequence": 1,
- "origin": "1637301307158",
- "oriText": "江宁万达广场",
- "key": "江宁万达广场",
- "type": "nspHB",
- "coreLocation": {
- "value": "江宁万达广场",
- "location": {
- "value": "江宁万达广场"
- }
- },
- "isAbstract": "0",
- "cost": "29",
- "charOffset": 9,
- "normalValue": "江宁万达广场",
- "user.extend": false,
- "isCorrected": false
- }],
- "time": [{
- "normalTime": {
- "start": {
- "timestamp": 1637391600000,
- "section": "P",
- "standardTime": "2021年11月20日15时00分00秒"
- }
- },
- "oriText": "明天下午三点",
- "sequence": 1,
- "origin": "1637301307158",
- "charOffset": 1,
- "normalValue": "明天下午三点",
- "user.extend": false,
- "isCorrected": false
- }],
- "varietyshow": [{
- "oriText": "速度与激情",
- "sequence": 1,
- "origin": "1637301307158",
- "heat": 0,
- "standardName": "速度与激情",
- "charOffset": 16,
- "normalValue": "速度与激"
- }]
- }
- }
6.思考总结
1.上述的AI能力不需要申请权限
2.这些AI能力使用起来还是非常方便的,开箱即用,可以灵活运用到应用开发中。
文章相关附件可以点击下面的原文链接前往下载
https://harmonyos.51cto.com/resource/1514

相关文章
- 在 Go 里用 CGO?这 7 个问题你要关注!
- 9款优秀的去中心化通讯软件 Matrix 的客户端
- 求职数据分析,项目经验该怎么写
- 在OKR中,我看到了数据驱动业务的未来
- 火山引擎云原生大数据在金融行业的实践
- OpenHarmony富设备移植指南(二)—从postmarketOS获取移植资源
- 《数据成熟度指数》报告:64%的企业领袖认为大多数员工“不懂数据”
- OpenHarmony 小型系统兼容性测试指南
- 肯睿中国(Cloudera):2023年企业数字战略三大趋势预测
- 适用于 Linux 的十大命令行游戏
- GNOME 截图工具的新旧截图方式
- System76 即将推出的 COSMIC 桌面正在酝酿大变化
- 2GB 内存 8GB 存储即可流畅运行,Windows 11 极致精简版系统 Tiny11 发布
- 迎接 ecode:一个即将推出的具有全新图形用户界面框架的现代、轻量级代码编辑器
- loongarch架构介绍(三)—地址翻译
- Go 语言怎么解决编译器错误“err is shadowed during return”?
- 敏捷:可能被开发人员遗忘的部分
- Denodo预测2023年数据管理和分析的未来
- 利用数据推动可持续发展
- 在 Vue3 中实现 React 原生 Hooks(useState、useEffect),深入理解 React Hooks 的