
一日一技:Selenium如何接管已经运行的 Chrome 浏览器?
2023-03-14 11:24:01 时间

在昨天的文章一日一技:爬虫模拟浏览器如何避免重复登录?中,我讲到了如何使用Puppeteer接管已经运行的Chrome。今天我们来讲讲使用Selenium如何实现这个功能。
在正式开始之前,先纠正昨天的一个错误。昨天我讲到,Windows电脑启动Chrome的远程调试模式用到的命令是:
- 文件路径/chrome.exe --remote-debugging-port=9222
这个地方漏掉了一个参数。正确的命令应该是:
- 文件路径/chrome.exe --remote-debugging-port=9222 --user-data-dir="某个存在的文件夹地址"
好了,回到正题。现在无论你使用macOS还是Windows,首先按昨天的文章所说,启动Chrome开放9222端口。然后,在这个Chrome中,手动登录示例网站。
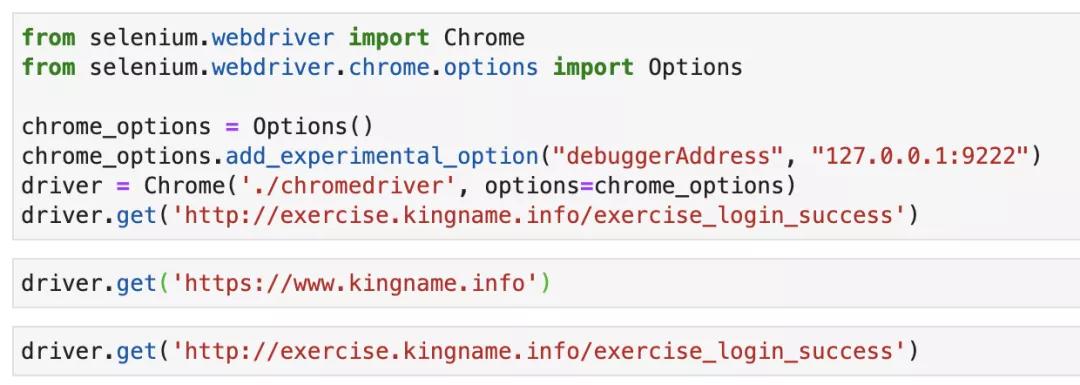
接下来,编写下面这段代码:
- from selenium.webdriver import Chrome
- from selenium.webdriver.chrome.options import Options
- chrome_options = Options()
- chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
- # 注意我把chromedriver文件放到了当前文件夹里面,所以可以这样调用
- # 如果你是windows电脑,你需要使用./chromedriver.exe
- driver = Chrome('./chromedriver', options=chrome_options)
- driver.get('http://exercise.kingname.info/exercise_login_success')
- input('输入任意内容继续')
- driver.get('https://www.kingname.info')
- input('输入任意内容继续')
- driver.get('http://exercise.kingname.info/exercise_login_success')
如下图所示:
由于使用Selenium的时候,始终操作的都是当前标签页,为了证明确实有效,所以我在示例代码里面,先把爬虫暂停,需要你在终端按下任何键以后,再打开我的博客。接下来,等你确认博客已经打开以后,再回到终端按下任意键,Chrome会再次打开登录成功的页面。
你还可以试一试把Python程序终止,再重新运行。你会发现代码依然可以接管这个浏览器窗口。
相关文章
- Centos7 和 Centos8 升级内核
- Keil MDK STM32系列(七) STM32F4基于HAL的PWM和定时器
- Keil MDK STM32系列(六) 基于抽象外设库HAL的ADC模数转换
- STM32F401+nRF24L01无线传输音频(对讲机原型)
- Keil MDK STM32系列(五) 使用STM32CubeMX创建项目基础结构
- Keil MDK STM32系列(四) 基于抽象外设库HAL的STM32F401开发
- Keil MDK STM32系列(三) 基于标准外设库SPL的STM32F407开发
- Keil MDK STM32系列(十) Ubuntu下的PlatformIO开发环境
- nRF24L01基于FIFO TX队列的发送性能优化
- phpBB3在Nginx反向代理中的X-Forwarded-For IP检查
- STC89C52驱动MAX7219LED点阵级联, 文字滚动效果
- STM32F407VET6烧录出现flash download failed target dll has been cancelled
- GCC项目的文件组织和编译步骤分解
- Ubuntu下使用PlatformIO开发STC89/STC12/Arduino
- 51单片机封装库HML_FwLib_STC89/STC11
- 用STM32F401和nRF24L01制作无线调速小车
- 在PWM控制下的直流有刷电机性能优化
- Github开始强制使用PAT(Personal Access Token)了
- STM32F401的PWM输出
- STM32F103和STM32F401的ADC多通道采集DMA输出