
实时处理大数据的分布式系统Druid-IO
2023-03-14 10:15:33 时间
Druid 是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
Druid 具有以下主要特征:
- 为分析而设计——Druid 是为 OLAP 工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——Druid 的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid 已实现每天能够处理数十亿事件和 TB 级数据。
当业务中出现以下情况时,Druid 是一个很好的技术方案选择:
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数 10T 数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
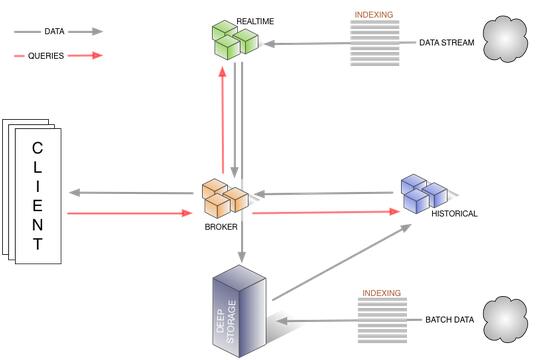
查询操作中数据流和各个节点的关系如下图所示:
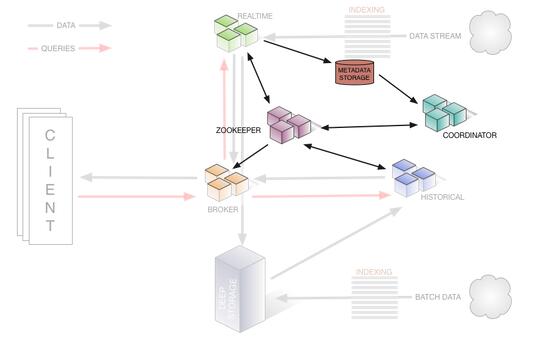
如下图是 Druid 集群的管理层架构,该图展示了相关节点和集群管理所依赖的其他组件(如负责服务发现的ZooKeeper集群)的关系:
相关文章
- 这十五个问题作为IT 技术人不得不考虑
- 大数据杀熟?揭秘争议背后的真问题
- 浅谈程序员接私单那点事及接私单需要注意的问题
- 人工智能与大数据开发的12个注意点
- 正确看待大数据的另一面
- 使用大数据最大限度地减少用户生成内容的风险
- 为什么程序员也能成为伟大的CEO
- 程序员,为什么千万不要重写代码?
- PHP Socket 编程过程详解
- 数据科学家必备的10种机器学习算法
- 最新前端开发面试题
- 平均年薪35W,2018年大数据AI发展趋势分析
- AI、IoT再火,仍然离不开大数据分析
- 挑战这十七项编程 锻炼大脑并且提升能力
- 现代版“围城”:互联网大数据下的“洗脑”
- 2015年最具人气最热门的十大编程语言
- 关于大数据,这里有10个预测
- 人工智能产业快速发展,2020年规模将破1600亿
- 九种方式帮助开发人员重建对互联网的信任
- 企业在采用大数据之前需加强网络安全