
如何使用KNIME进行情感分析 | 中
在现实世界中,知识不仅以传统数据库中的结构化数据的形式出现,还以诸如书籍、研究论文、新闻文章、WEB页面及电子邮件等各种各样的形式出现。面对以这些形式出现的、浩如烟海的信息源,人类的阅读能力、时间精力等等往往不够,需要借助计算机的智能处理技术来帮助人类及时、方便的获取这些数据源中隐藏的有用信息。文本挖掘技术就在这种背景下产生和发展起来的。
文本挖掘的根本价值在于能把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。文本挖掘广泛应用于舆情监测、有害信息过滤、电子邮件和文献分析以及情感分析等领域。
今天我们来聊一聊如何用KNIME构造一个情感分析模型,以便后期对相似的文本进行情感分析。
下图是整个分析过程的概况:
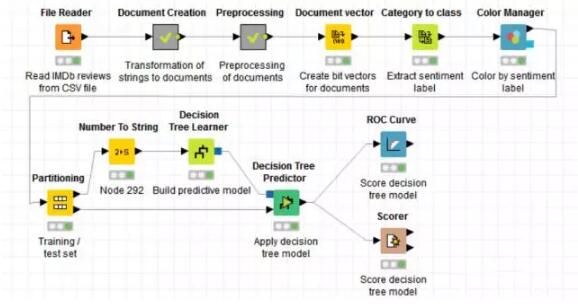
首先,我们从IMDb网站上获取关于《Girlfight》这部影片的2000条评论,储存为.CSV格式的文件,利用File Reader这个节点把文本读入。

现在我们要将文件中的字符串转化成文档,把文件中除了文档的列都过滤掉。
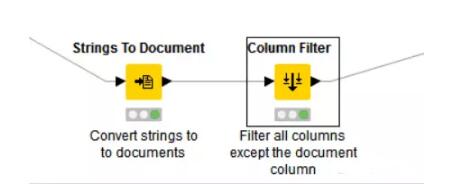
(上图即为Document Creation元节点里面的内容)
接着我们对这个文档进行文本的预处理。先后将标点清除,数字过滤掉,将小于三个词语的文档过滤掉,停用词过滤,将大写转化为小写,***提取词干。

(上图即为Preprocessing元节点里面的内容)
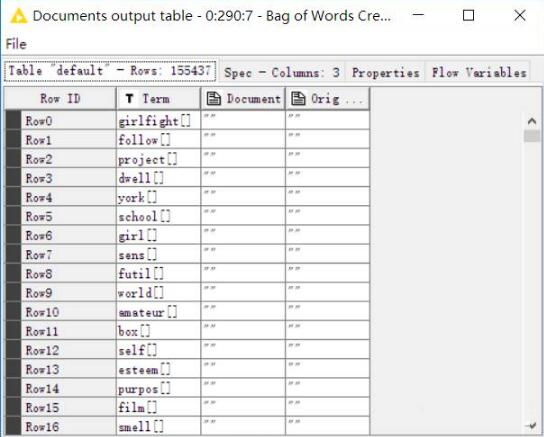
之后我们就可以创建词袋了,即把提取出来的词干扔进一个袋子里,可以看到,在本例中,我们创造的词袋中一共包含155437行数据。
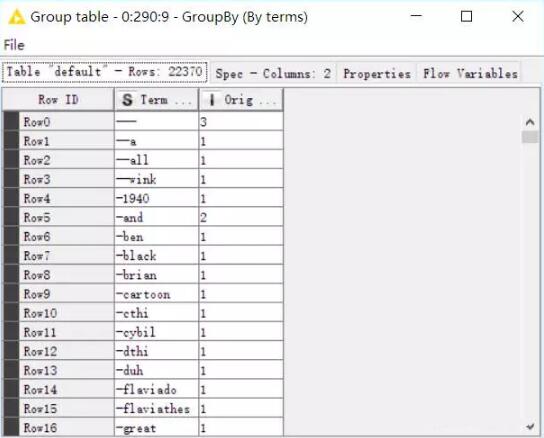
然后把词袋中的词转化为字符串,并根据原评论中词出现的次数分组,可以看到,分组后我们的词袋变成了22370行(这是因为之前的词是有重复的)。
之后我们过滤掉出现次数小于N的词,(注意这个N是由从原文件中提取出的行数经过一段语法计算决定的,在本例中,是用行数除以100)。
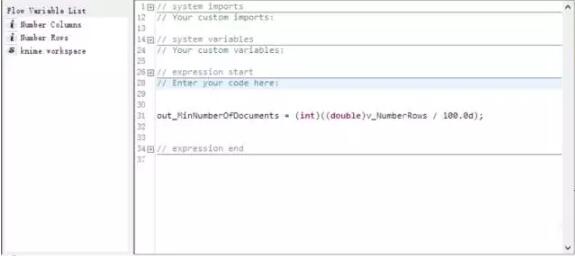
接着,我们以上一步过滤掉的词为参考,在最初创建的词袋中过滤掉它们,过滤后我们可用的词是100728行数据,***计算这些词的词频。
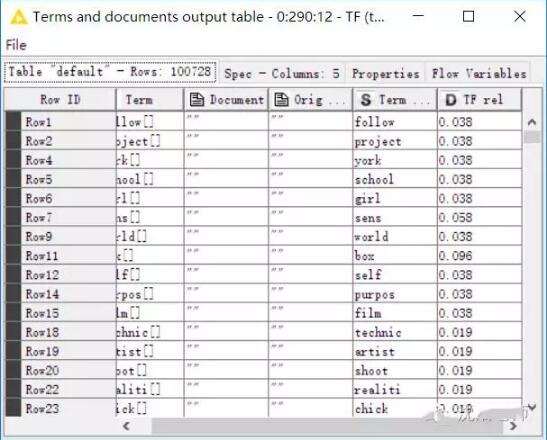
终于我们完成了文本的预处理过程。
现在,我们要为原始的评论创建向量,来观察词袋中的词是否存在于原文本中。之后提取原评论的情感标签,并以颜色分类。
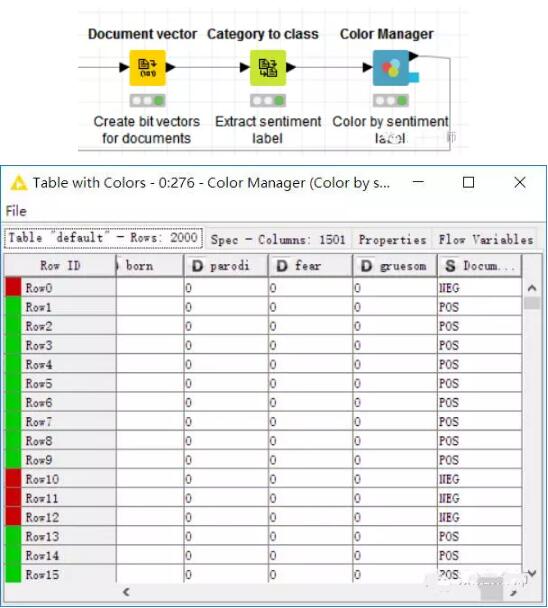
接着我们把2000条评论分成两个部分,本例中将70%用作训练集,来构建决策树模型,另外的30%用来测试决策树模型。
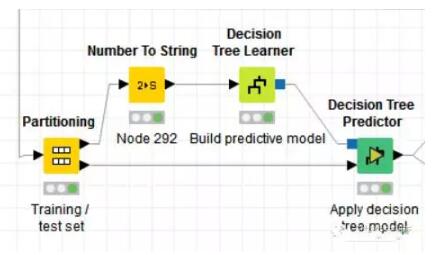
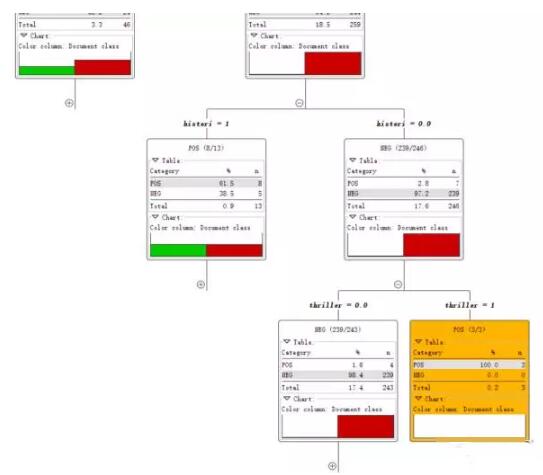
这就是决策树模型,根据一个词是否存在将文本集分为两个部分。
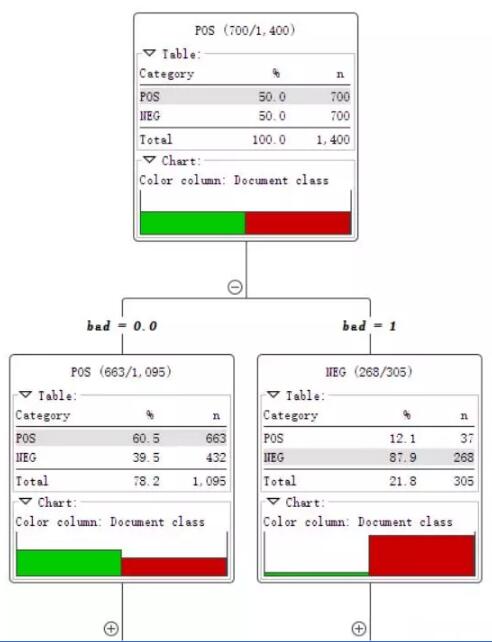
直到所有记录都属于同一类决策树就会停止。
***我们用两种方法来对模型进行评价。
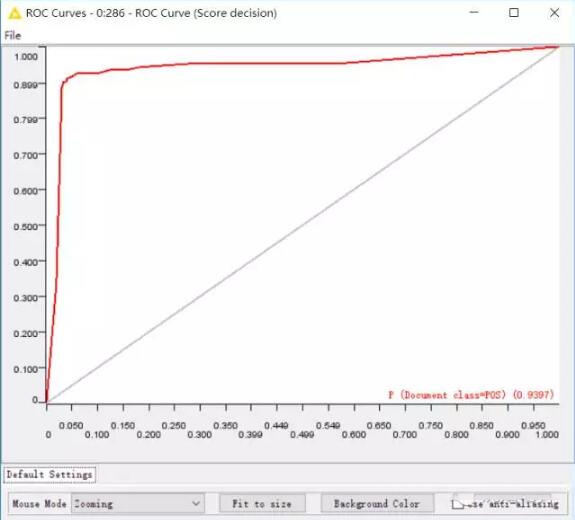
一种是ROC曲线,曲线下方面积达到0.9397,如此可见,模型还是很不错的。
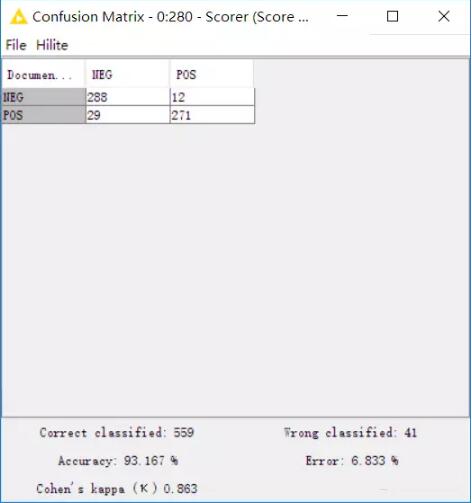
再来看一下矩阵,准确率高达93.167%。
如此看来,我们的模型可以用来进行类似的文本情感分析。比如说网购的商品评论,企业官微下的评论等类似的情况,都可以用来进行情感分析。
点击查看:
相关文章
- 绝了!这个MySQL故障定位方法太好用了
- Redis 高可用篇:Cluster 集群能支撑的数据有多大?
- Websocket库Ws原理分析
- 《吃透 MQ 系列》之打通 Kafka 的任督二脉
- 谷歌这个牛逼的开源数据库,我居然等到它上Github热榜才发现
- 热点推荐:2016年热门技术方向预测
- 一文搞定消息队列(MQ)之生产者-消费者
- 穷人的量子比特:量子计算机太难造了,先试试概率计算机?
- 字节前端都知道的CSS包含块规则
- 第一个世界量子日,量子计算大牛Scott Aaronson获颁ACM计算奖
- 全栈CMS系统服务端启动细节复盘
- Netfileter & Iptables 实现之 Netfilter实现
- 双写兜兜转转,又回到了串行化的方式
- 不停止 MySQL 服务增加从库的两种方式
- 本科作业到Nature子刊:大二学生突破量子计算近20年的纠错码难题
- 压缩版styleGAN,合成高保真图像,参数更少、计算复杂度更低
- 小白学习mysql之高新能索引基础篇
- ASP.NET 跨平台最佳实践
- 2021年程序员必备的9项技能
- 「原理」AB测试-详细过程和原理解读