
Apache Kylin优化–高级设置:聚合组(Aggregation Group)原理解析

“随着维度数目的增加,Cuboid 的数量会爆炸式地增长。为了缓解 Cube 的构建压力,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等。”
众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。
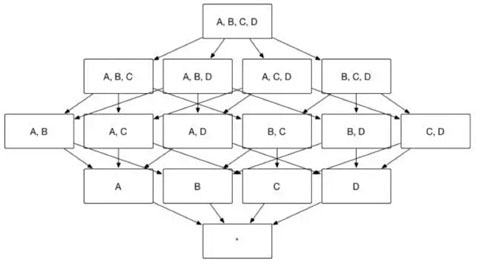
图1
随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等,本系列将深入讲解这些高级设置的含义及其适用的场景。
本文将着重介绍聚合组的实现原理与应用场景实例。
聚合组(Aggregation Group)
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。例如图 1 中展示的 Cube,如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 2 所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。

图2
用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如图 3 所示。

图3
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
应用实例
假设创建一个交易数据的 Cube,它包含了以下一些维度:顾客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和买家所在的城市 city。有时候,分析师需要通过分组聚合 city、cal_dt 和 pay_type 来获知不同消费方式在不同城市的应用情况;有时候,分析师需要通过聚合 city 、cal_dt 和 buyer_id,来查看顾客在不同城市的消费行为。在上述的实例中,推荐建立两个聚合组,包含的维度和方式如图 4 :
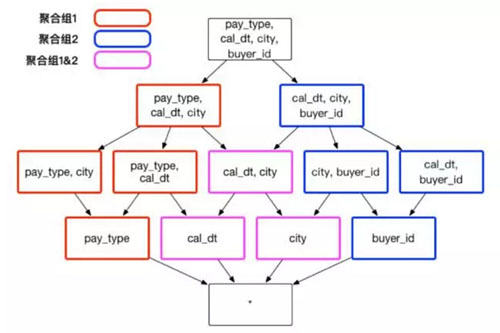
聚合组 1: [cal_dt, city, pay_type]
聚合组 2: [cal_dt, city, buyer_id]
在不考虑其他干扰因素的情况下,这样的聚合组将节省不必要的 3 个 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,节省了存储资源和构建的执行时间。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case3 如果有一条不常用的查询:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 则没有现成的完全匹配的 Cuboid。
此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
小结
Apache Kylin 作为一种多维分析工具,其采用预计算的方法,利用空间换取时间,提高查询效率。本文介绍了 Apache Kylin 的高级设置中聚合组的部分,聚合组适用于当分析师粗粒度地关注某些维度去进行分组聚合的场景。
相关文章
- 比Firebase还好用!神级程序员都在用这个开发工具
- Golang 语言中 kafka 客户端库 Sarama
- 世界级的开源项目:TiDB 如何重新定义下一代关系型数据库
- 用好OnionScan,自己动手制作暗网爬虫
- Java 8 Streams中的数据库CRUD操作
- Java中如何使用嵌入MySQL
- 谷歌发布新编程语言,专治SQL各种“不服”
- JavaEE中遗漏的10个最重要的安全控制
- 如何在O(1)内找到实时序列的最小值?
- Seata 分布式事务 XA 与 AT 全面解析
- 绝了!这个MySQL故障定位方法太好用了
- Redis 高可用篇:Cluster 集群能支撑的数据有多大?
- Websocket库Ws原理分析
- 《吃透 MQ 系列》之打通 Kafka 的任督二脉
- 谷歌这个牛逼的开源数据库,我居然等到它上Github热榜才发现
- 热点推荐:2016年热门技术方向预测
- 一文搞定消息队列(MQ)之生产者-消费者
- 穷人的量子比特:量子计算机太难造了,先试试概率计算机?
- 字节前端都知道的CSS包含块规则
- 第一个世界量子日,量子计算大牛Scott Aaronson获颁ACM计算奖