
如何使用Disruptor(二)从Ringbuffer读取
从上一篇文章中我们都了解了什么是Ring Buffer以及它是如何的特别。但遗憾的是,我还没有讲述如何使用Disruptor向Ring Buffer写数据和从Ring Buffer中读取数据。
ConsumerBarrier与消费者
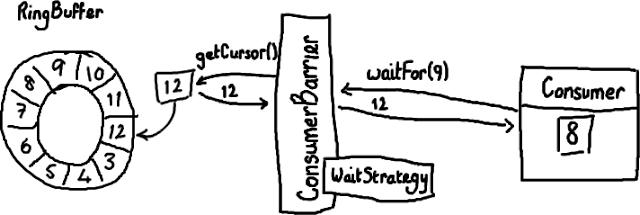
(好,我开始后悔使用Paint/Gimp 了。尽管这是个购买绘图板的好借口,如果我继续写下去的话… UML界的权威们大概也在诅咒我的名字了。)
消费者(Consumer)是一个想从Ring Buffer里读取数据的线程,它可以访问ConsumerBarrier对象——这个对象由RingBuffer创建并且代表消费者与RingBuffer进行交互。就像Ring Buffer显然需要一个序号才能找到下一个可用节点一样,消费者也需要知道它将要处理的序号——每个消费者都需要找到下一个它要访问的序号。在上面的例子中,消费者处理完了Ring Buffer里序号8之前(包括8)的所有数据,那么它期待访问的下一个序号是9。
消费者可以调用ConsumerBarrier对象的waitFor()方法,传递它所需要的下一个序号.
1 |
final long availableSeq = consumerBarrier.waitFor(nextSequence); |
ConsumerBarrier返回RingBuffer的最大可访问序号——在上面的例子中是12。ConsumerBarrier有一个WaitStrategy方法来决定它如何等待这个序号,我现在不会去描述它的细节,代码的注释里已经概括了每一种WaitStrategy的优点和缺点 。
接下来怎么做?
接下来,消费者会一直原地停留,等待更多数据被写入Ring Buffer。并且,一旦数据写入后消费者会收到通知——节点9,10,11和12 已写入。现在序号12到了,消费者可以让ConsumerBarrier去拿这些序号节点里的数据了。
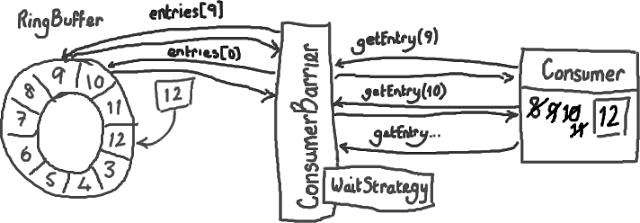
拿到了数据后,消费者(Consumer)会更新自己的标识(cursor)。
你应该已经感觉得到,这样做是怎样有助于平缓延迟的峰值了——以前需要逐个节点地询问“我可以拿下一个数据吗?现在可以了么?现在呢?”,消费者(Consumer)现在只需要简单的说“当你拿到的数字比我这个要大的时候请告诉我”,函数返回值会告诉它有多少个新的节点可以读取数据了。因为这些新的节点的确已经写入了数据(Ring Buffer本身的序号已经更新),而且消费者对这些节点的唯一操作是读而不是写,因此访问不用加锁。这太好了,不仅代码实现起来可以更加安全和简单,而且不用加锁使得速度更快。
另一个好处是——你可以用多个消费者(Consumer)去读同一个RingBuffer ,不需要加锁,也不需要用另外的队列来协调不同的线程(消费者)。这样你可以在Disruptor的协调下实现真正的并发数据处理。
BatchConsumer代码是一个消费者的例子。如果你实现了BatchHandler, 你可以用BatchConsumer来完成上面我提到的复杂工作。它很容易对付那些需要成批处理的节点(例如上文中要处理的9-12节点)而不用单独地去读取每一个节点。
更新:注意Disruptor 2.0版本使用了与本文不一样的命名。如果你对类名感到困惑,请阅读我的变更总结。
原文链接:http://ifeve.com/dissecting-the-disruptor-how-do-i-read-from-the-ring-buffer/
译文链接:http://ifeve.com/dissecting_the_disruptor_how_doi_read_from_the_ring_buffer/
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地