
数据分析图的十大错误,你占了几个?
"数据可视化"是个好帮手,可以帮助用户理解数据。但是,你真的会用它吗?看看这里,数据可视化的十大错误你占了几个?
优秀的数据可视化依赖优异的设计,并非仅仅选择正确的图表模板那么简单。全在于以一种更加有助于理解和引导的方式去表达信息,尽可能减轻用户获取信息的成本。当然并非所有的图表制作者都精于此道。所以我们看到的图表表达中,各种让人啼笑皆非的错误都有,下面就是这些错误当容易纠正的例子:
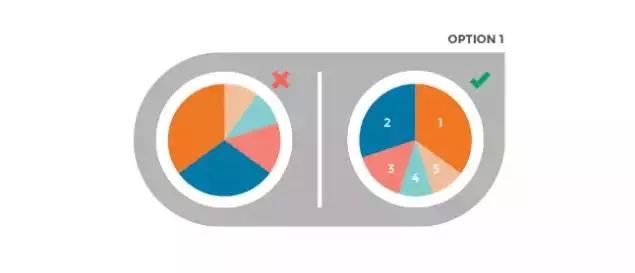
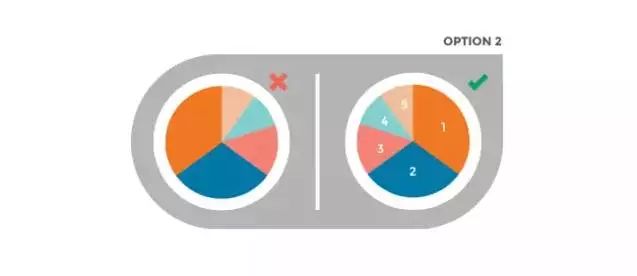
1、饼图顺序不当
饼图是一种非常简单的可视化工具,但他们却常常过于复杂。份额应该直观排序,而且不要超过5个细分。有两种排序方法都可以让你的读者迅速抓取最多的重要信息。
方法一:将份额***的那部分放在12点方向,逆时针放置第二大份额的部分,以此类推。
方法二:***部分放在12点,然后顺时针放置。
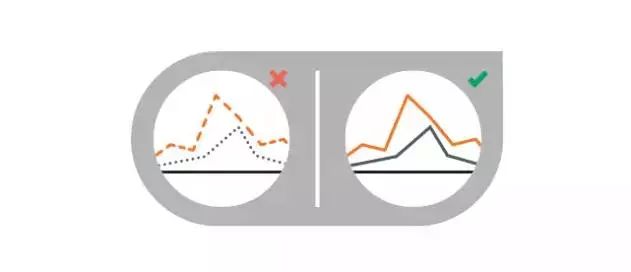
2、在线状图中使用虚线
虚线会让人分心,而是用实线搭配合适的颜色更容易彼此区分。
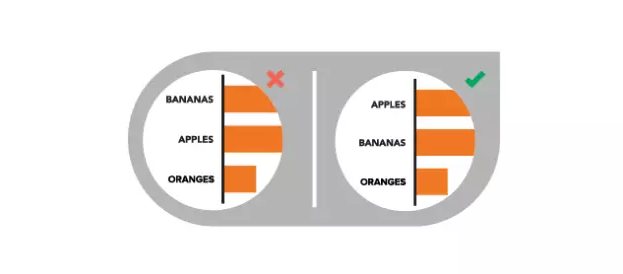
3、数据摆放不直观
你的内容应该符合逻辑并于直观的方式引导读者阅读数据。对类目进行按字母,次数或数值大小进行排序。
4、数据模糊化
确保数据不会因为设计而丢失或被覆盖。例如在面积图中使用透明效果来确保用户可以看到全部数据。
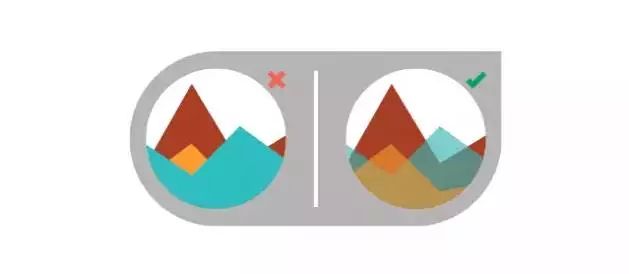
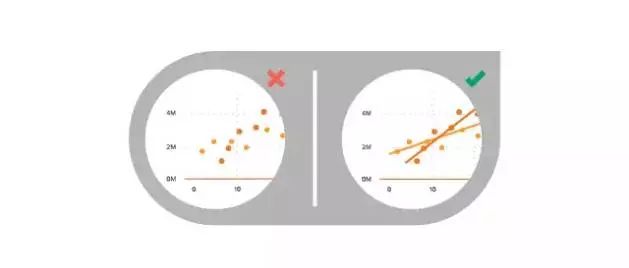
5、耗费读者更多的精力
要通过辅助的图形元素来使数据更易于理解,比如在散点图中增加趋势线。
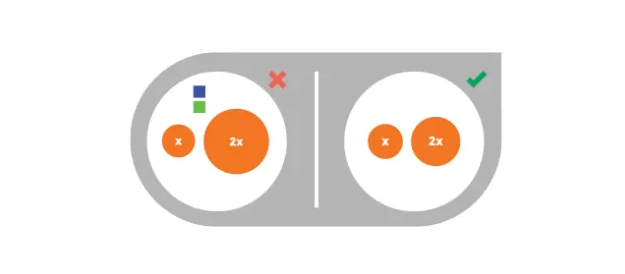
6、错误呈现数据
确保任何呈现都是准确的,比如,气泡图的大小应该跟数值一样,不要随便标注。
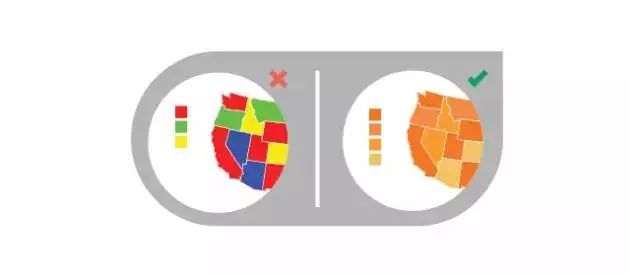
7、在热图中使用不同颜色
一些颜色比其他颜色突出,赋予了数据不必要的重元素。反而你应该使用单一颜色,然后通过颜色的深浅来表达。
8、柱状过宽或过窄
柱子与柱子之间的间隔***调整为宽的1/2。
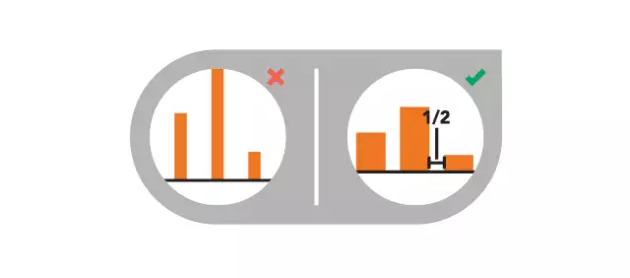
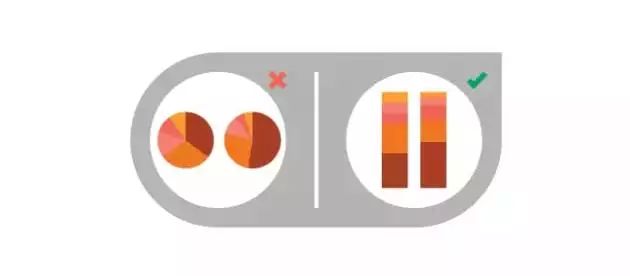
9、数据对比困难
对比是呈现差异的有效方式,但如果你的读者不易对比时,效果就大打折扣了。确保数据的呈现方式一致,可以让你的读者对比。
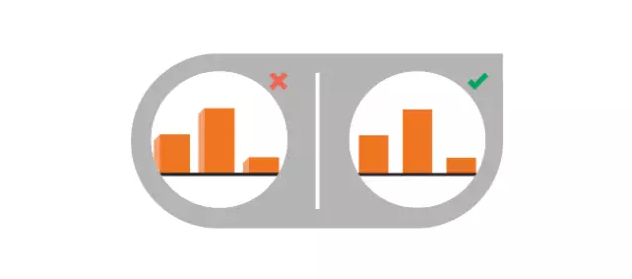
10、使用三维图
尽管这些图看来让人振奋,但3D图也容易分散预期和扰乱数据,坚持2D是王道。
怎么样?看过10个数据可视化的错误之后,是否意识到领导对你的数据分析图表摇头的原因了,快行动起来吧~
相关文章
- Kylin 4 集成 Amazon Glue Catalog!
- 实时数据处理中的AWS lambda (python) 性能优化
- Python enumerate() 函数
- 无需订阅费! 手把手教你如何在Amazon OpenSearch Service中使用跨集群复制功能(Cross-Cluster Replication)
- Amazon MSK Serverless 现已正式推出–无需再为托管式 Kafka 集群进行容量规划
- AWS IoT TwinMaker 现已正式发布
- 利用Amazon Redshift的流式摄取构建实时数仓
- 使用TiDB Data Migration迁移分库分表数据库到Amazon Aurora
- 使用Spline收集Spark数据血缘实践
- 亚马逊云科技2022年3月新服务新功能强势来袭
- 使用 Amazon MSK、Apache Flink 和 Apache Hudi 实现流批一体的数据湖架构
- Amazon Personalize 个性化效果评估,从准确性到多样性、新颖性和偶然性
- 适用于 Oracle 向 Amazon RDS for PostgreSQL 或 Amazon Aurora PostgreSQL 迁移的架构和代码验证器
- Java(2)-Java IO输入输出流
- 在 Kubernetes 中为应用程序部署 Amazon RDS 数据库
- 使用企业微信接收数据库事件通知
- 油气服务行业软件落地“亚马逊云科技中国区域”的技术实践与总结
- 使用 Amazon MSK Connect、Apache Flink 和 Apache Hudi 创建低延迟的源到数据湖管道
- Amazon EMR之EMR和Hadoop的前世今生
- 自动驾驶数据湖(二):图像处理和模型训练