
利用Selenium批量下载100首网易云热歌榜音乐
2023-03-09 22:08:11 时间

本文转载自微信公众号「菜J学Python」,作者游世九黎。转载本文请联系菜J学Python公众号。
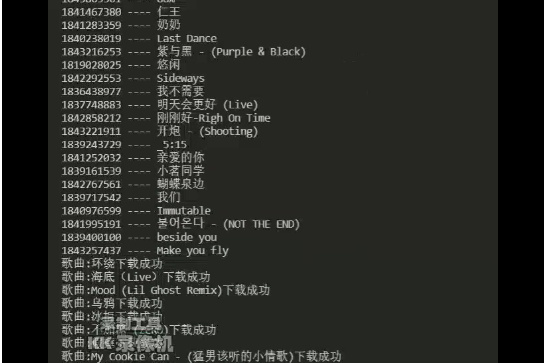
今天的小demo我们使用的是selenium和xpath.函数式编程采集数据.采集到的数据如图所示。

01需求数据
网易云音乐新歌榜数据100首歌曲。
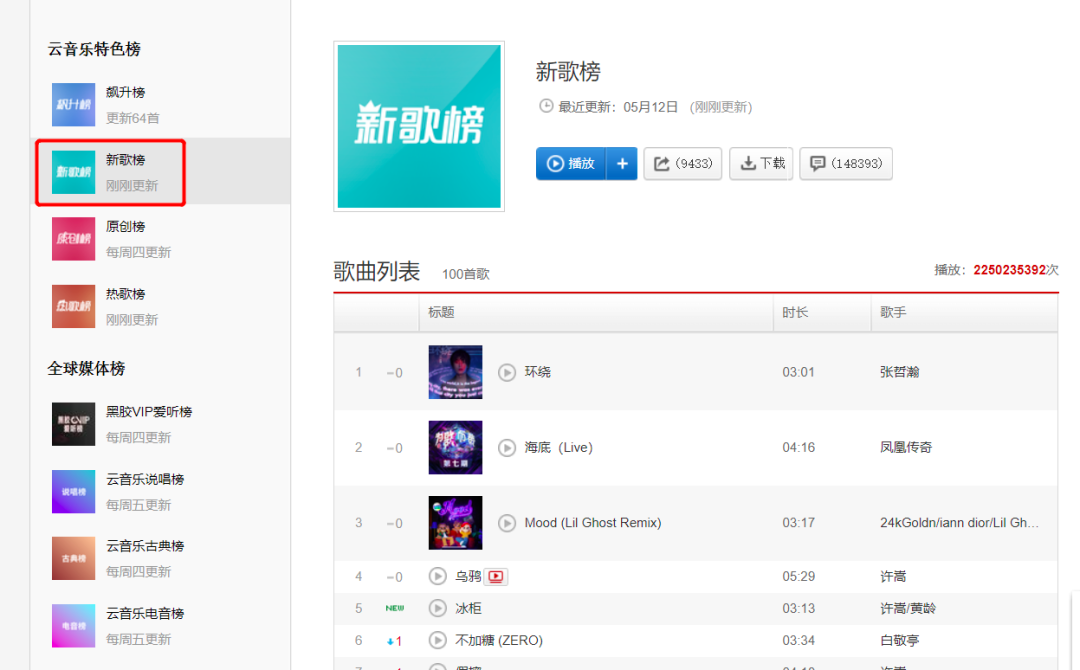
02页面分析
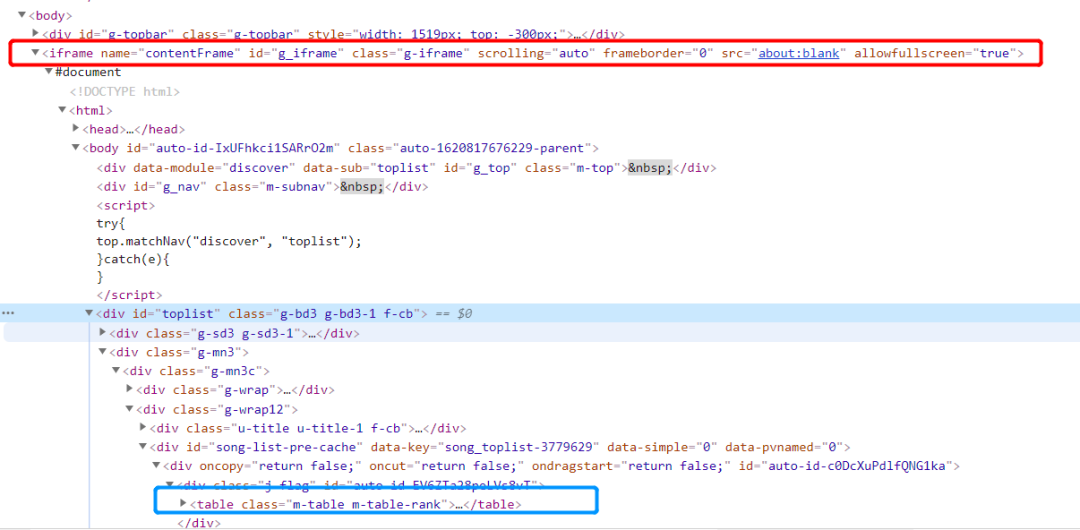
首先这个页面通过reuqests方法是无法获取页面数据的,所以我们这里使用selenium,xpath方法解析数据。
这个table标签装了100首歌曲数据,但是这个页面是嵌在iframe标签中的,所以需要定位iframe标签,获取到里面的的内容。
- url = "https://music.163.com/#/discover/toplist?id=3779629" # 新歌榜
- driver = webdriver.Chrome()
- driver.get(url)
- time.sleep(3)
- _iframe = driver.find_element_by_id('g_iframe') # 找到iframe标签
- driver.switch_to.frame(_iframe)
- time.sleep(1)
- page_text = driver.execute_script("return document.documentElement.outerHTML")
03解析数据
得到了iframe中的元素page_text,我们使用xpath。
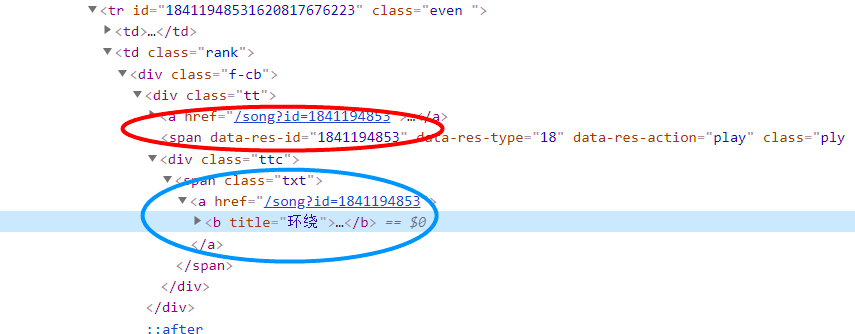
- html = etree.HTML(page_text)
- trs = html.xpath('//tr')
- id_list = []
- song_name_list = []
- singer_list = []
- for tr in trs[1:]:
- id = tr.xpath("./td[2]/div[1]/div[1]/span/@data-res-id")[0][-10:] #
- id_list.append(id)
- song_name = tr.xpath("./td[2]/div/div/div/span/a/b/@title")[0]
- song_name_list.append(song_name)
- print(id,"----",song_name)
04保存数据

- base_url = 'http://music.163.com/song/media/outer/url?id={}.mp3'
- try:
- for index,id in enumerate(id_list):
- if index == 25: # 因为这个26首歌曲名非正常字符,要排除,否则报错
- continue
- file_name = song_name_list[index]
- resp = requests.get(base_url.format(id))
- with open(r'HotMusic/'+ file_name + '.mp3','wb') as f:
- f.write(resp.content)
- print('歌曲:%s下载成功' % file_name)
- except Exception as error:
- print(error)
05运行程序
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地