
Go在酷狗数据库中间件的应用

本次分享主要围绕Go在数据库中间件应用这方面展开;首先会聊一下程序开发的需求,具体会参考Go的特性是否满足这些需求;接下来会介绍一下近期采用Go语言开发的mysql中间件这个项目,整体方案,分表路由、故障切换、平滑扩容,系统运维,主要从以上这五个方面进行展开。
程序开发需求
程序开发对开发语言的要求,简单概括如下几点:
语言特性精炼,容易入门
开发效率高,代码逻辑清晰
运行性能强,节省机器资源
部署维护方便
生态圈完善
Golang的特性
结合Golang与C之间区别,阐述一下Golang的特性:
Go语法简练;没有学习压力
开发效率高;语言描述能力接近于脚本语言
性能高;接近于C/C++,充分利用资源
容易部署;可执行程序,编译时解决上线部署、运行时的依赖
强大的标准库、丰富的第三方库、go test、pprof
自动内存管理;内存泄漏与野指针是C/C++语言开发者的噩梦
Go routine + channel;简单的并发与简易的数据同步
Go开发mysql中间件
- 系统整体方案
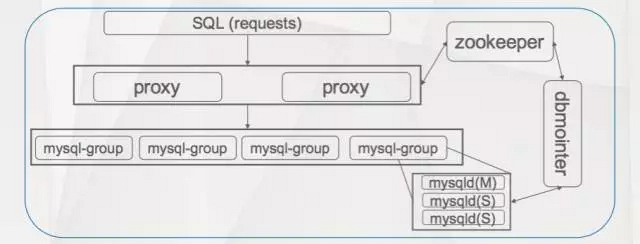
图 1
本系统开发的出发点是:突破mysql的单机、单表容量,解决mysql访问的单点问题。
上图是系统整体框架图,整套系统致力于提供一套 mysql 分布式解决方案,上层应用接入本系统与使用单机mysql一样;系统内部会做一些路由分发、故障切换、读写分离等工作。
proxy接收SQL请求,解析SQL语句、路由分发以及组装返回结果;
mysql-group都是一个“复制集”,可以是主从模式、主主模式;
dbmoniter主要是负责故障切换、数据修复等;
zookeeper上存储相关的配置信息。
- 分表路由逻辑
分表规则遵循哈希分表与分段分表两种;哈希分表是shardkey通过Hash函数分表,分段分表是按照年、月、日或者整形范围进行分表。这两种方式的区别在于因哈希规则不同,导致其数据组织方式上的差异性。
- 故障主备切换
关于MySQL的高可用方案,业内流行的解决方案有MHA。MHA在部署方面还是有点麻烦的,需要在每台机器上都部署一个agent,然后机器之间进行SSH授权。我们采取的策略是通过配置Rsync拉取mysql的binlog日志的方式处理。
故障的几种情形以及对应的处理:
- 当从节点挂掉,可以剔除下线的处理;
- 当主节点挂了,但是机器存活的情况下,可以通过binlog恢复数据,将备节点提升为主节点;
- 当主节点挂了,同时机器不存活的情况下,可以采用relaylog恢复数据,同时将备节点提升为主节点。
我们实现了如下的双主模式主备切换机制,这点是MHA不支持的。
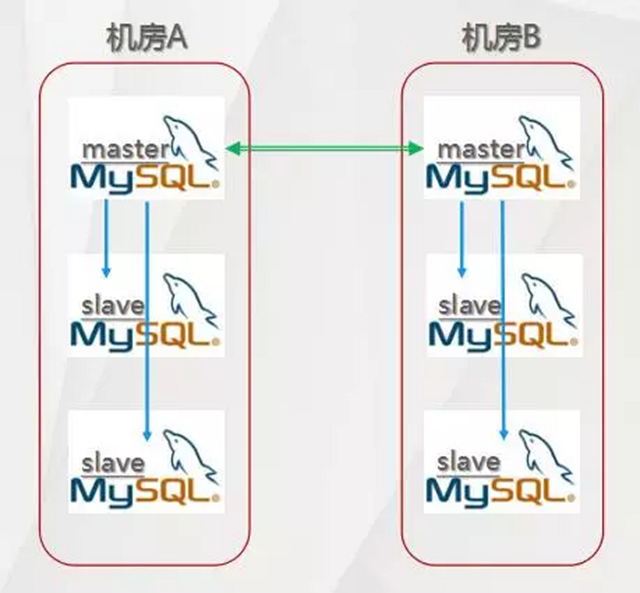
图 2
主备切换数据恢复的过程:Master故障时试图通过Rsync拉取Binlog,最大程度保证数据不丢失;Slave之间的数据差异通过中继日志恢复。

图 3
- 在线平滑扩容
数据迁移的方式分为两种:
- 表迁移,将整张表的数据从一个Mysql迁移到另一个;
- 表拆分,将数据表的部分数据从一个Mysql迁移到另一个数据库的过程。
扩容的工作原理:mysqldump导存量数据 + binlog追增量
扩容工作流程:
首先,导出存量数据;
其次,订阅binlog变更,追增量;
再次,待同步后,修改路由规则;
最后,清理不需要的冗余数据。
这样设计的好处就在于其中任一环节出问题都可以马上进行回滚,对数据操作相对比较安全;下图是扩容时的流程图。
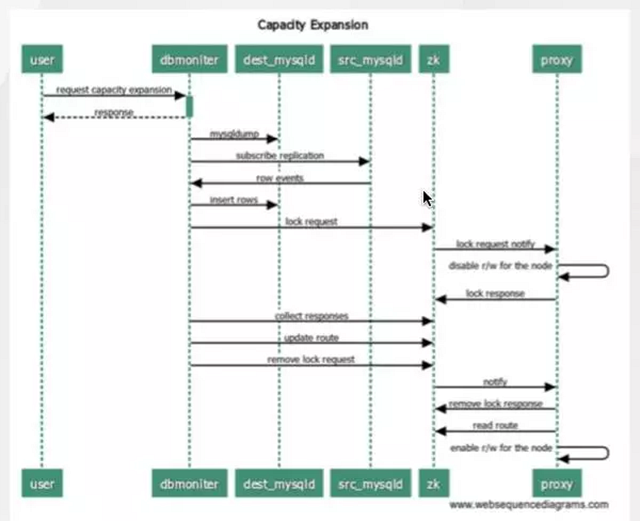
图 4
- 系统管理命令
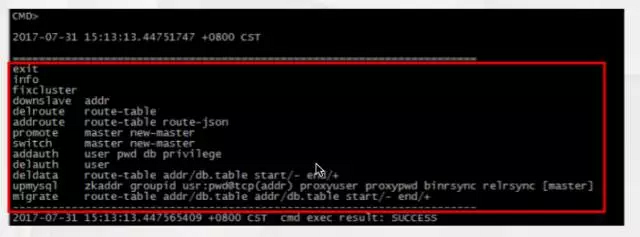
图 5
如图 5 所示是提供了几个主要管理命令,比如上下线MySQL、数据迁移指令、添加路由等。
相关文章
- 利用Kafka设置可靠的高性能分布式消息传递基础架构
- 国内外15大BI数据可视化工具
- 机器学习操作不适用于云计算运维
- 我被“非结构化数据包围了”,请求支援!
- 我们可以不再使用ETL了吗?
- 数据科学中的“帕累托法则”
- 电商数据分析,掌握这些业务的数据指标就够了
- 这些方法解决了数据清洗 80% 的工作量
- 大数据:现代政府廉政建设的利器
- 如何在Flink 1.9中使用 Hive?
- 如何使用TensorFlow和自编码器模型生成手写数字
- 技术人最不该忽视可视化数据分析!
- 云+社区联合快手 深度解读五大热门大数据技术
- 你的隐私被泄露了!大数据时代如何保护信息安全?
- 大数据主导的七大领域,看看你是否身处其中
- 数据处理必看:如何让你的Pandas循环加快71803倍
- 数据科学中的强大思维
- Hive和Spark究竟是凭借什么优势而大获成功?
- 大数据需求使用的六个Hadoop发行版
- 2017年中美数据科学对比报告,Python排名第一,年薪中位数高达11万美金