
Python微博移动端爬虫实例(附代码)
2023-03-09 22:04:49 时间
本文简要讲述用Python爬取微博移动端数据的方法。可以看一下Robots协议。另外尽量不要爬取太快。如果你毫无节制的去爬取别人数据,别人网站当然会反爬越来越严厉。至于为什么不爬PC端,原因是移动端较简单,很适合爬虫新手入门。有时间再写PC端吧!
环境介绍
Python3/Windows-10-64位/微博移动端
网页分析
以获取评论信息为例(你可以以自己的喜好获得其他数据)。如下图:
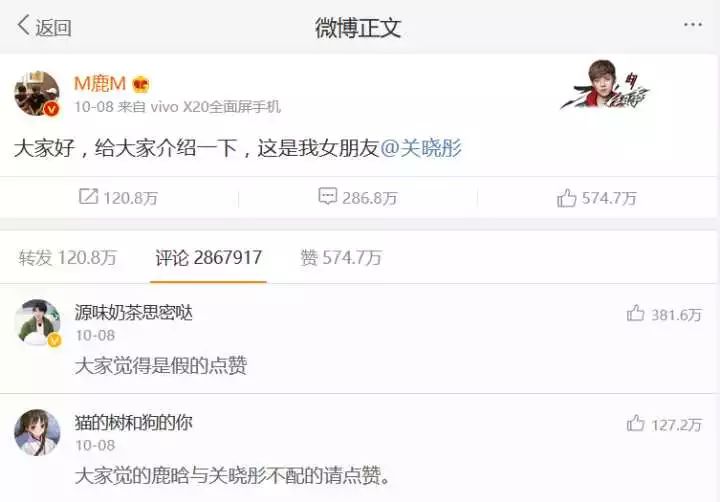
在这里就会涉及到一个动态加载的概念,也就是我们只有向下滑动鼠标滚轮才会加载出更多的评论数据。这也是网页经常使用的方式。接下来就应该找到评论信息的真实网址,找到真实网址的方法就是打开浏览器的开发者工具,火狐/谷歌是F12键。打开如下:
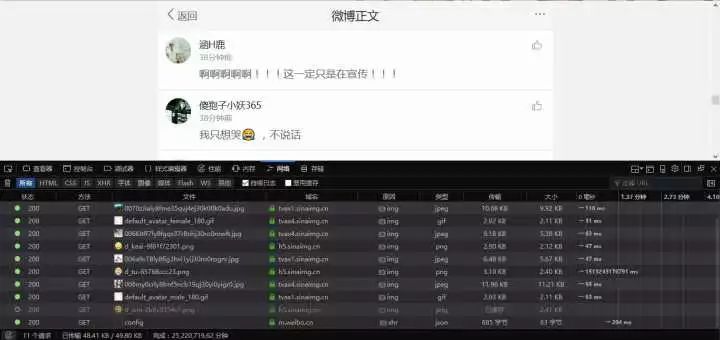
打开以后点击网络,网络用来记录浏览器和服务器交换的信息。接下来将鼠标滚轮缓慢向下滚动,在这个过程中就会弹出类似于上图的信息,也就是评论信息加载出来了。找到评论信息,应该会在***条。如下图:
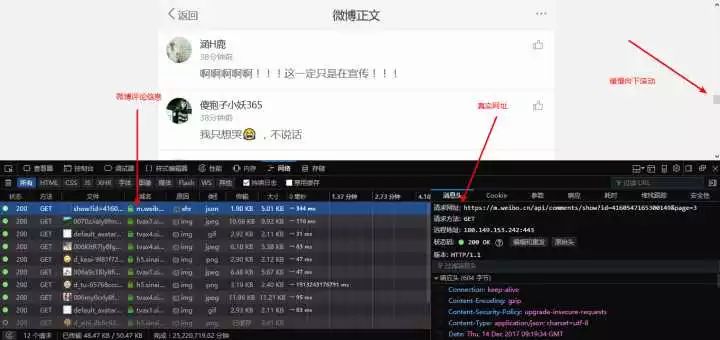
真实网址:https://m.weibo.cn/api/comments/show?id=4160547165300149&page=3
将网址在火狐里面打开如下图:
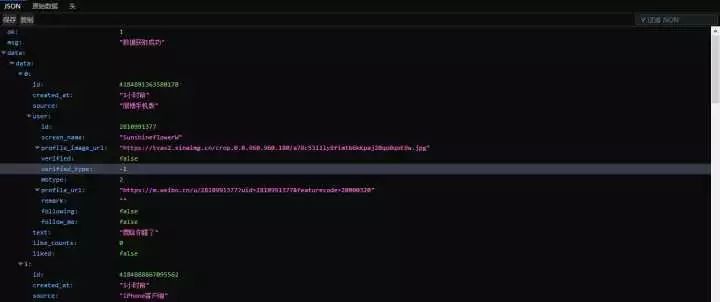
上面的网址其实pages=3就代表第三页,所以只需模拟网址即可,pages=4,5,6。。。。
另外由于是Json文件,所以提取数据非常方便,只需用切片操作即可。
相关文章
- 如何编写一个自己的图片API
- Python字符串和正则表达式的深入学习
- Python字典和集合初窥
- Python函数的学习总结
- C语言 逻辑量、逻辑运算符和逻辑表达式、if语句和switch语句
- 钉钉微应用开发后端 : (实验室绩效管理系统)
- Java servlet中web xml文件内容执行原理
- 为什么我不建议你通过 Python 去找工作?
- Javaweb-servlet中的Filter过滤器使用方法。
- Axios使用方法-实现前后端交互
- Python粉丝数实时播报程序
- 不背锅运维:分享OpenStack API使用套路
- apisix control api的使用
- Python下载文件进度条Demo
- 【代码】利用Python每天自动发新闻到邮箱
- Python 接口测试之处理转义字符的参数和编码问题
- python和netlogo软件模拟病毒传播仿真模型(一)
- aes加密算法python版本
- Win10 环境下安装Tesseract-OCR与Python集成识别
- Selenium IDE 命令使用——断言