
MariaDB Spider:实现MySQL横纵向扩展的小能手
什么是Spider?
当您的数据库不断增长时,您绝对需要考虑其它技术,如数据库分片。Spider是MariaDB内置的一个可插拔用于MariaDB/MySQL数据库分片的存储引擎,充当应用服务器和远程后端DB之间的代理(中间件),它可以轻松实现MySQL的横向和纵向扩展,突破单台MySQL的限制,支持范围分区、列表分区、哈希分区,支持XA分布式事务,支持跨库join。通过Spider,您可以跨多个数据库后端有效访问数据,让您的应用程序一行代码不改,即可轻松实现分库分表!
分库分表架构:
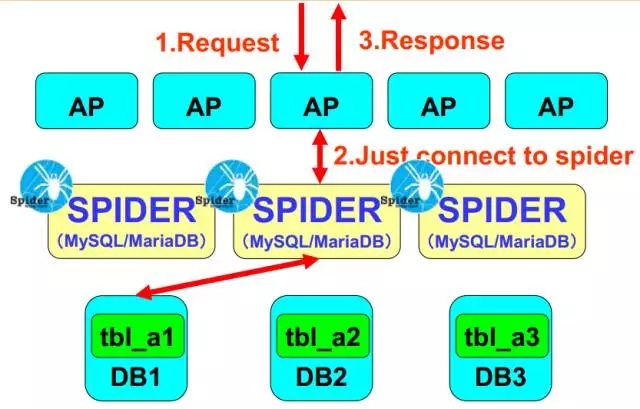
应用程序连接Spider,Spider充当中间件代理,将客户端查询的请求,按照事先定义好的分片规则,分发给后端数据库,之后返回的数据汇总在Spider内存里做聚合,最终返回客户端请求,对于应用程序而言是透明的。
典型案例---腾讯游戏

腾讯游戏的生产环境数据量达到了100TB,用了396个Spider节点做数据拆分,分片后的数据用了2800个MySQL节点存储。
使用场景介绍
下面介绍一下我负责的一个项目,已通过Spider实现了历史表的垂直拆分。
随着业务的增长,单台服务器磁盘空间有限,有些业务上的历史数据,DBA用工具pt-archiver归档后,历史表就没有用了,通常我们会把它单独迁移到备份机,主库上就删除了。但有的时候,BI统计部门来了一个需求,需要临时关联查询这些历史表,那么,DBA就需要从备份机上myloader导入到从库上去,为了降低导数据引起的从库CPU升高、磁盘IO的瞬间增大,可能造成主从复制的延迟。
为了减少这种重复性的体力工作,为了更快速地缩短可用时间,我们可以通过Spider引擎解决,通过它你可以将远程服务器上的表做一个映射,做一个软连接,相当于你操作本地的表一样,简单而便捷,省去了那么多麻烦,临时提供给业务方用,也不用考虑过多的性能问题。
架构图如下:
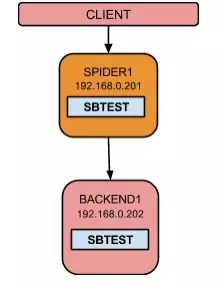
实施这个方案,选择Spider引擎是有优势的:
SQL解析和查询优化是个非常复杂且很难做好的工作,其它替代产品都是自己实现,由于复杂性,这些产品都带来了一些限制,比如不支持存储过程、函数、视图等,给使用和实施带来了困难。而作为一个存储引擎,这些工作都由MariaDB自身完成了,可以方便地将大表做分布式拆分,和Fabric相比,它的好处是对业务方使用是透明的,SQL语法没有任何限制,在不改变现有DB架构的方案中,侵入性最小。
内部原理架构图如下:

我们在一台从库上,安装上Spider引擎,只需两条命令做一个表的“超链接”,分分钟就解决了问题。
注:前提是你的从库使用的是MariaDB10。
下面是官方的垂直拆分压测报告:
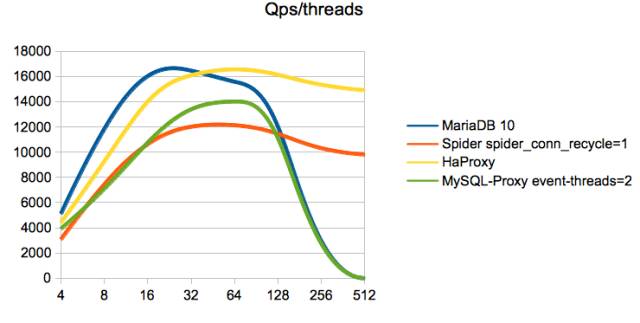
而在我的压测结果上,分库分表的性能会降低70%,垂直拆分性能会降低40%,性能损耗的原因是在分布式场景下,要保证2pc的一致性和可用性,读写的表现就差,另外就是跨多个网络传输这两方面引起的,目前为RC公测版本V3.2.37,固在主库上实现该功能要慎重!
Spider引擎安装
# mysql -uroot -p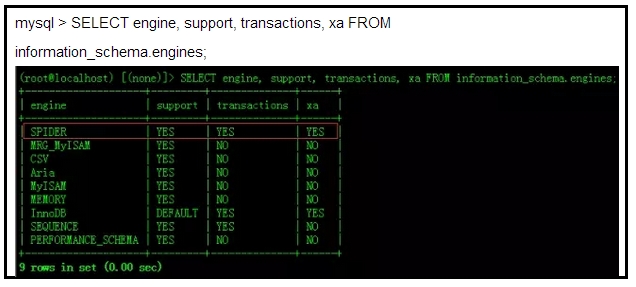
Spider引擎使用
-
垂直拆分
1、定义后端服务器和数据库名字

这里后端服务器的名字为backend1,数据库名字为test,主机IP地址为192.168.143.205,用户名为user_readonly,密码为123456,端口为3306。
注:如配置错误,可直接DROP SERVERbackend1; 重新创建即可。
2、创建表的“超链接”

这里通过设置COMMENT注释来调用后端的表,然后你就可以查看sbtest表了,是不是很简单?
-
分库分表

同上,但区别是分库分表是采用了类似表分区的概念实现。
可调优参数
spider_conn_recycle_mode= 1
连接复用,类似连接池这种功能
optimizer_switch= 'engine_condition_pushdown=on'
引擎下推,查询推送到后端数据库,将查询结果返回给Spider做聚合
负载均衡架构设计
由于Spider自身不保存数据,只保存路由信息,是无状态的,因而可以部署多个Spider做负载均衡,架构图如下:
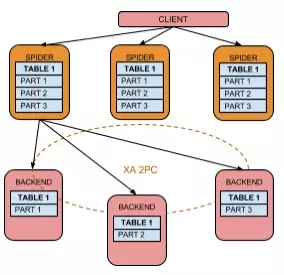
后端MySQL可以结合MHA实现高可用故障切换。
注:在MariaDB10.2版本里,Spider准备GA。
原文发布时间为:2017-04-20
本文来自云栖社区合作伙伴DBAplus
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地