
遇到有这六大缺陷的数据集该怎么办?这有一份数据处理急救包
不要再向你的机器学习模型里喂垃圾了!
在这篇文章中,身兼AI工程师/音乐家/围棋爱好者多职的“斜杠青年”Julien Despois给出了数据科学中需要避免的6大错误。
全文编译整理如下:

简介
身为一名数据科学工作者,你应该听说过一句话:
你的结果会和你的数据一样好。
很多人试图通过提升模型来弥补不太理想的数据集。这等同于你的旧车因为用了廉价汽油性能不好,但你买了一辆豪华跑车。很明显药不对症嘛!
在这篇文章中,我会讲一讲如何通过优化数据集提升模型结果,并将以图像分类任务为例进行说明,但这些tips可被应用在各种各样的数据集中。
今天的正餐,正式开始——
问题一:数据集太小
如果数据集太小,模型将没有足够样例概括可区分特征。这将使数据过拟合,从而出现训练误差(training error)低但测试误差(test error)高的情况。
解决方案1:
去收集更多数据吧~尝试找到更多和原始数据集来源相同的数据,如果图像很相似或者你追求的就是泛化,也可用其他来源的数据。
小贴士:这并非易事,需要你投入时间和经费。在开始之前,你要先分析确定需要多少额外数据。将不同大小的数据集得出的结果做比较,然后思考一下这个问题。
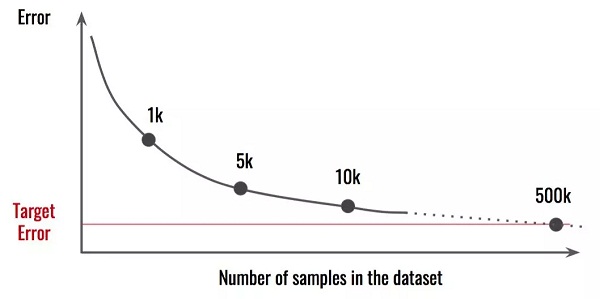
△ 数据集中数据量和错误率的关系
解决方案2:
通过为同一张图像创建多个细微变化的副本来扩充数据,可以让你以非常低的成本创造很多额外的图像。你可以试着裁剪、旋转或缩放图片,也可以添加噪音、模糊、改变图片颜色或遮挡部分内容。

△ 一张图片的各种变化
不管怎么操作吧,只需保证这些数据仍代表相同类就好了。
虽然这种操作很厉害,但仍不如收集更多原始数据效果好。

△ 处理后图像仍被分类为猫
小贴士:这种“扩充术”不适合所有问题,比如如果你想分类黄柠檬和绿柠檬,就不要调颜色了嘛~

数据集太小的问题解决后,第二个问题来了——
问题二:分类质量差
这是个简单但耗时的问题,需要你浏览一遍数据集确认每个样例的标签打得对不对。
除此以外,一定为你的分类选择合适的粒度(granularity)。基于要解决的问题,来增加或减少你的分类。
比如,要识别猫,你可以用全局分类器先确定它是动物,之后再用动物分类器确定它是一只小猫。一个大型的模型能同时做到这两点,但分起类来也更加困难。
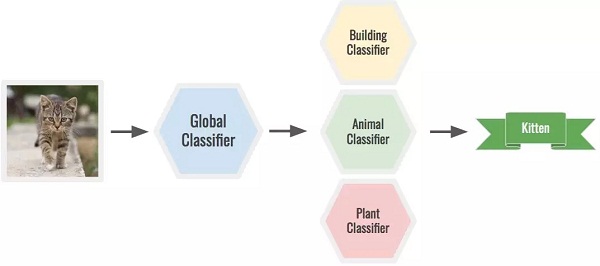
△ 小猫的分类过程
问题三:数据集质量差
就像前言中说的那样,数据质量差会导致结果的质量差。
可能你的数据集中有一些样例离达标真的很远,比如下面这几张图像。

△ 三张不合格的猫咪图像样例
这些图像会干扰模型的正确分类,你需要将这些图像在数据集中剔除。
虽然是个漫长枯燥的过程,但对结果的提升效果很明显。
另一个常见问题是,数据集可能是由与实际应用程序不匹配的数据组成的。如果图像来自完全不同来源,这个问题可能尤为严重。
解决方案:先思考一下这项技术的长期应用,因为它关系到获取生产中的数据。尝试用相同的工具查找/构建一个数据集。
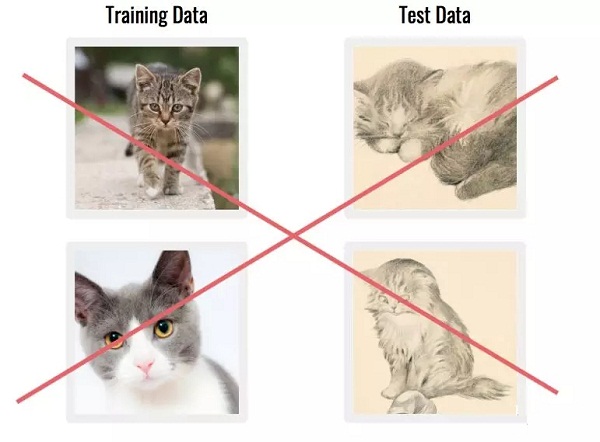
△ 使用与实际应用差别太大的数据训练模型非常不明智
问题四:分类不平衡
如果每个分类的样例数量与其他类别数量差距太大,则模型可能倾向于数量占主导地位的类,因为它会让错误率变低。
解决方案1:
你可以收集更多非代表性的分类。然而这通常需要花费时较多间和金钱,也可能根本不可行。
解决方案2:
对数据进行过采样/降采样处理。这意味着你可能需要从那些比例过多的分类中移除一些样例,也可以在比例较少的类别中进行上面提到过的样例扩充处理。
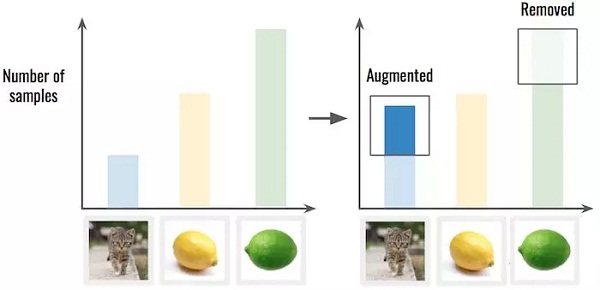
△ 先扩充样例不足的分类(猫咪),这将使类别的分布更平滑
问题五:数据不平衡
如果你的数据没有专门的格式,或者它的值没有在特定的范围,模型处理起来可能很困难。如果图像有特定的纵横比或像素值,得到的结果会更好。
解决方案1:
裁剪或拉伸数据,使其与其他样例的格式相同,如下图所示。

△ 裁剪和拉伸是改善格式的两种方法
解决方案2:
将数据规范化,使每个样例在相同的值范围内。

问题六:没有验证或测试
数据集被清理、扩充并打上标签后,你就需要把它们分个组了。
许多数据研究人员会将这些数据分成两组:80%用于训练,20%用于测试,这将会使发现过拟合变容易。
然而,如果你在同一个测试集上尝试多个模型,情况则有所不同。选择测试精度的***模型,实际上是对测试集进行过拟合处理。
解决方案:
将数据集分为训练、验证和测试三组,这可以保护你的测试集,防止它因为所选的模型而过拟合。那这个过程就变成了:
- 在训练集上训练模型
- 在验证集上测试它们,确保它们没有过拟合
- 选择***模型,并用测试集测试,看看你的模型准确性有多高。

注意:提醒一句,记得经常用整个数据集去训练模型,数据越多,效果越好。
总结
***,送广大数据科学工作者一句N字箴言:
拥有***模型的人不是赢家,拥有***数据的人才是。
相关文章
- Arduino从DHT11读取温湿度数据并显示在1602LCD
- Ubuntu16.04 Arduino开发
- 新路由的回传数据
- 欧拉定理, RSA计算实践
- 二进制的手工计算, 以及计算机的浮点数存储
- MySQL Workbench使用
- Redis常用命令
- MySQL的binlog操作
- MySQL的主从配置和集群配置
- MySQL中分组取第一条, 以及删除多余的重复记录
- Java8 jvm参数
- 配置Tomcat使用Redis作为session管理
- Win7安装Redis
- Centos6 安装 Redis 和集群配置
- Debian 8.2 下安装MySQL5.7.9 Generic Binaries
- MySQL 的乐观并发控制Optimistic concurrency control
- 等额本息计算式的推导
- MySQL迁移[转]
- iptables详细说明
- Oracle相关笔记