
数据挖掘领域十大经典算法之—K-Means算法(超详细附代码)
2023-03-09 22:00:05 时间
k-means算法比较简单。在k-means算法中,用cluster来表示簇;容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
简介
又叫K-均值算法,是非监督学习中的聚类算法。
")
基本思想
k-means算法比较简单。在k-means算法中,用cluster来表示簇;容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster,每个初始cluster只包含一个点);
repeat:
- 对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
- 重新计算k个cluster对应的质心(质心是cluster中样本点的均值);
- until 质心不再发生变化 12345
repeat的次数决定了算法的迭代次数。实际上,k-means的本质是最小化目标函数,目标函数为每个点到其簇质心的距离的平方和:
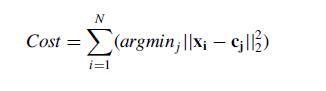
- N是元素个数,x表示元素,c(j)表示第j簇的质心
- 算法复杂度
- 时间复杂度是O(nkt) ,其中n代表元素个数,t代表算法迭代的次数,k代表簇的数目
优缺点
- 优点
- 简单、快速;
- 对大数据集有较高的效率并且是可伸缩性的;
- 时间复杂度近于线性,适合挖掘大规模数据集。
缺点
- k-means是局部***,因而对初始质心的选取敏感;
- 选择能达到目标函数***的k值是非常困难的。
代码
代码已在github上实现,这里也贴出来
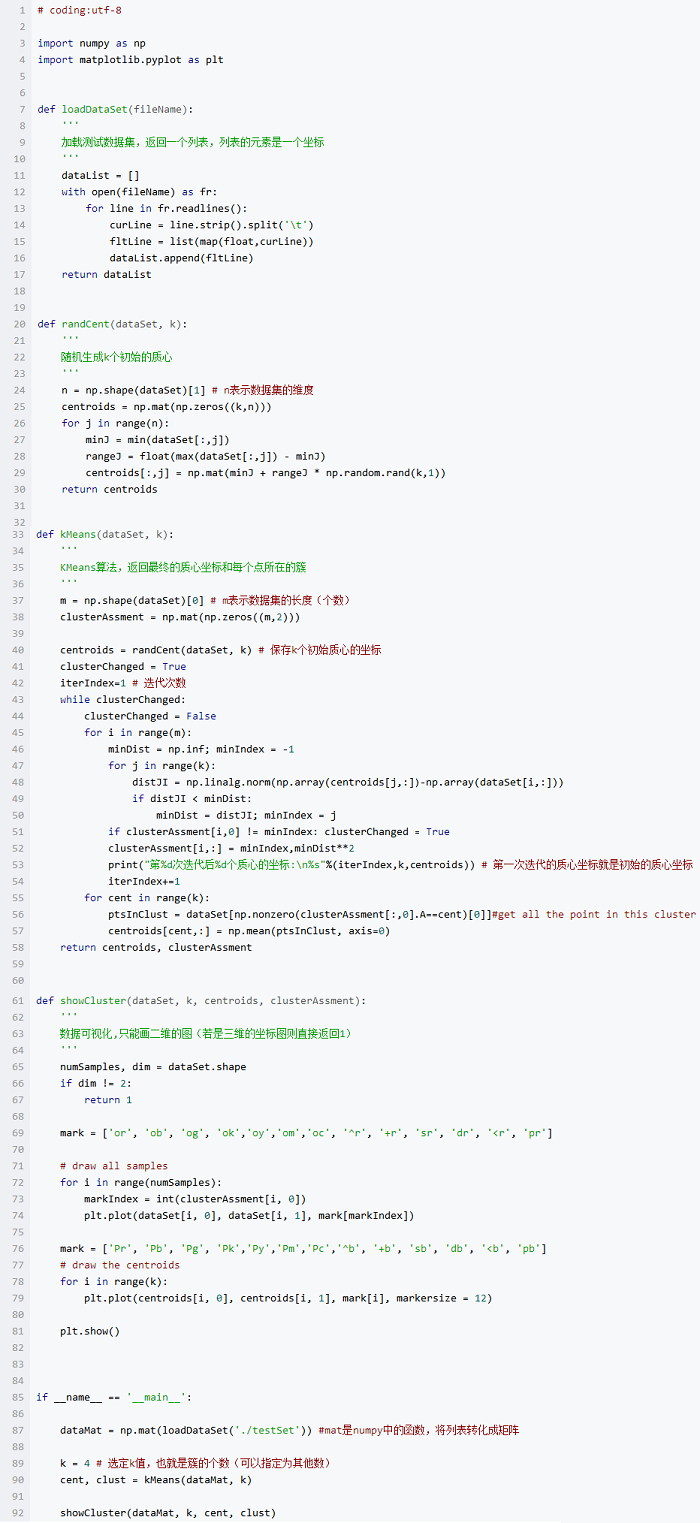
测试数据集获取地址为testSet
相关文章
- requests库常用函数使用——爬虫基础(1)
- 用LearnCloud构建简单app(1)
- keychron K3 键盘和 Windows11 操作系统的笔记本电脑通过蓝牙配对出现问题的解决方案
- FPGA:组合逻辑电路的设计
- 【愚公系列】2023年01月 .NET CORE工具案例-SharpConfig配置文件读取库
- Webpack提取页面公共资源
- 【愚公系列】2023年01月 .NET CORE工具案例- Magick.NET神级图片和视频操作库
- 生信星球day7-毽子
- RealWorldCtf2023-The_cult_of_8_bit详解
- nesbot/carbon 日期时间处理扩展包
- phpoffice/phpexcel 导出Excel表格数据
- Windows 系统 PhpStorm 2020无限试用30天
- 微擎安装模块时提示 Failed to connect to we7.rewlkj.com port 80: Timed out
- Sketch Fashion for mac(服装设计软件) v1.2.5中文版
- vue.js客服系统实时聊天项目开发(四)引入iconfont图标代码
- vue.js客服系统实时聊天项目开发(五)flex布局实现输入框区域
- SSH 公钥免密登录
- TP6.0 自定义日志驱动
- 【虹科新闻】虹科被评为“2022年广东省‘专精特新’中小企业”
- 【好玩儿的Docker项目】10分钟部署一个类似知乎的开源问答平台——Answer