
5个大数据处理/数据分析/分布式工具
1.Hadoop
Hadoop是一个开源框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。它的目的是从单一的服务器到上千台机器的扩展,每一个台机都可以提供本地计算和存储。
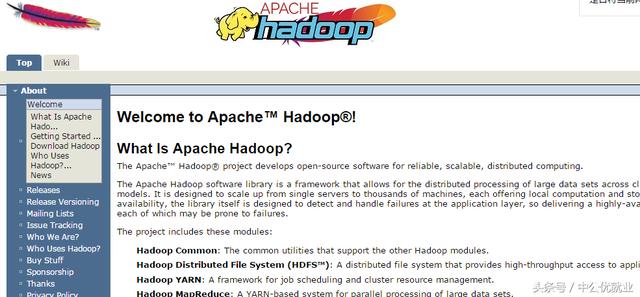
2.Druid
Druid是实时数据分析存储系统,Java语言中***的数据库连接池。Druid能够提供强大的监控和扩展功能。
Druid是一个分布式的、面向列的、实时的分析数据存储库,通常用于为多租户环境中的探索性仪表板供电。
Druid作为一种数据仓库解决方案,擅长于对petabyte大小的数据集进行快速聚合查询。Druid支持各种灵活的过滤器、精确计算、近似算法和其他有用的计算。
Druid可以同时加载流数据和批处理数据,并与Samza、Kafka、Storm、SPark和Hadoop集成。
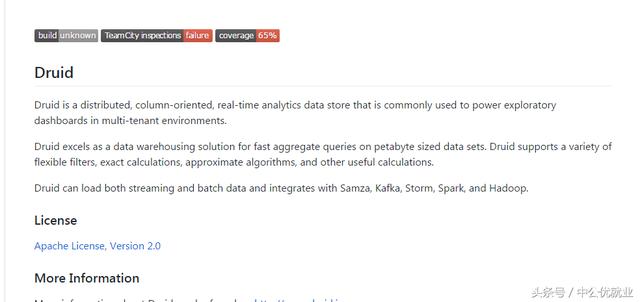
3.Ambari
大数据平台搭建、监控利器;类似的还有CDH
Ambari能够:
提供Hadoop集群
- Ambari为在任意数量的主机上安装Hadoop服务提供了一个逐步向导。
- Ambari处理集群Hadoop服务的配置。
管理Hadoop集群
- Ambari为整个集群提供启动、停止和重新配置Hadoop服务的中央管理。
监视Hadoop集群
- Ambari为监视Hadoop集群的健康状况和状态提供了一个仪表板。
- 安巴里杠杆Ambari度量系统用于度量集合。
- 安巴里杠杆Ambari警报框架用于系统警报,并在需要注意时通知您(例如,节点下降,剩余磁盘空间较低等)。
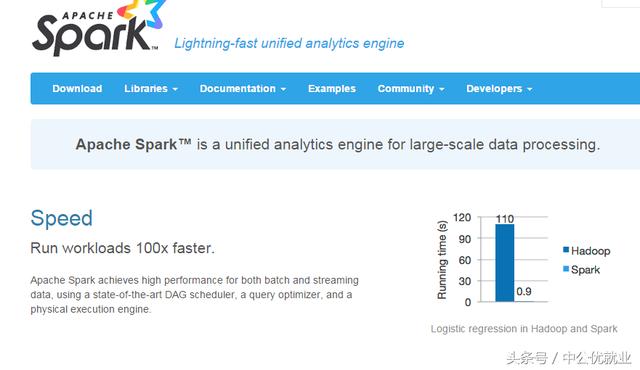
4.Spark
一个快速通用的集群计算系统.它在Java、Scala、Python和R中提供了高级API,并提供了支持通用执行图的优化引擎。大规模数据处理框架(可以应付企业中常见的三种数据处理场景:复杂的批量数据处理(batch data processing);基于历史数据的交互式查询;基于实时数据流的数据处理,Ceph:Linux分布式文件系统。
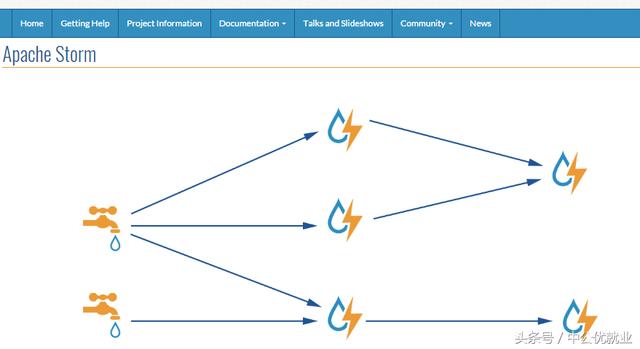
5.Storm
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工具,Storm的性能也是非常出众的。
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地