
S3 成本优化 – Part 1 最佳优化实践
背景
在很多客户使用Amazon S3服务一段时间之后,都可能有成本优化方面的考量。一般在现实状况下,由于多年的数据堆积和后期系统开发等方面因素,并不能很准确定义出存储桶中的数据情况(比如某个文件夹下面有多少文件是30天以内需要访问的,多少文件是30天之外会访问的,多少文件是0KB的文件,多少文件是小于128KB的文件等)。在这种状况下进行S3费用优化,过程中可能会遇到很多问题,甚至不恰当的优化方式不但不会降低成本反而会导致费用的进一步增加。所以不能仅靠粗略估计,而是需要通过更细致的分析进行各种优化方式的优劣对比,找到最合适的优化方案。本文将带大家详细了解一下S3成本优化的最佳实践过程。
S3存储类型概要
S3存储类型分为5种(低冗余存储官方已经不再建议使用,所以排除在外),分别是:1. S3标准2. S3智能分层3. S3-IA (包括one zone)4. S3 Glacier5. S3 Glacier Deep Archive 。 S3并不是只是简单的按照数据用量来收费,不同的类型有不同的价格,并且在数据使用费之外,还有其他费用,例如据请求费和检索费等。从1-5,数据存储费越来越便宜,但是请求和数据检索的费用却越来越贵。所以S3的使用总费用是数据存储费+请求检索费+数据传输费用+存储类型转换费。 下图以1000个文件,总大小1GB在美东1区佛吉尼亚北部的费用为例:

S3成本优化过程
下面我们开始讲解具体的操作步骤 (注意以下提到的内容不涉及到开启了版本控制的桶,对于开启了版本控制的桶虽然逻辑相同,但是一些查询方法会有差别,请酌情参考),以下价格全部以美东1 佛吉尼亚北部为例,具体价格可以参考以下页面:https://aws.amazon.com/s3/pricing/
1.使用生命周期清理未完成的分段上传
分段上传文件,是指一些大文件上传的时候自动分成几个小分段,但是传输过程中某几个分段失败了,留下了其他的不完整文件分段。由于这部分文件是隐藏文件但是也占用空间,因而在做真正的优化之前,除非应用有特别需求,一般情况都建议把这部分文件从桶上删除掉。如果想了解一个桶上有多少multi-upload文件,可以使用CLI – aws s3api list-multipart-uploads –bucket my-bucket 进行查询,或者也可以联系AWS支持中心或您的专属TAM来获取这部分具体信息。对于一些客户,这部分文件的使用量可能达到一个桶的10%,比如20PB的S3桶,2PB都是不必要的未完成传输文件分段。 参考以下文档对整桶配置生命周期根据需要清理这些未完成文件分段,使用生命周期删除文件不会产生额外费用(但是对于Glacier/Glacier Deep Archive/IA有例外情况,详情请参考本系列的下一篇博客文章)
2.开启S3清单
做任何S3成本优化之前,建议开启S3清单(inventory)功能,这样可以借助aws athena服务来查询s3 清单中的内容从而更准确地确认各种存储类型的文件列表以及文件数目等详细信息。
S3 清单价格: 每百万个所列对象 0.0025 USD – 一个桶如果有10亿文件数的话,开一次清单收费2.5$
Athena 查询费用:每 TB 扫描数据 5.00 USD – 一个桶如果有10亿文件数的话,大概清单文件为30-40GB,查询1次价格为0.2$.
可以看到使用这两个功能的价格跟节省成本比较几乎可以忽略不计
请注意,请开启S3清单功能的时候选择CSV格式并且选择每周刷新数据,这样可以减少生成的文件数量,便于查询。
如何开启S3清单: S3 控制台–管理–清单–新增

选择大小,上次修改日期,存储类别,默认选仅限当前版本。如果桶开启了多版本,需要选择“包括所有版本“。

3.对清单文件建立Athena表并查询
在开启 s3清单功能后,可能需要多达48小时才能收到第一份S3清单文件,一般情况下生成清单时间少于24小时。清单文件csv生成之后,请按照下列方式在Athena服务中建立一个清单表,以供查询使用。第一次使用Athena点击“入门”之后可能会需要您设置在S3中的查询结果位置。详情参见文档https://docs.aws.amazon.com/zh_cn/athena/latest/ug/getting-started.html
如何使用语句建立S3清单的Athena table:( 请修改 `inventory_list` 为新表名,并修改’s3://inventory/testinventory/data/hive’为新生成的S3清单地址下的hive前缀)
详细如何查询Athena清单表的语句:
4.查询上一个月的CUR,列出关于某个桶的具体用量信息
如何设置CUR(Cost Usage Report)在本文中就不再复述,请参考文档开启CUR并且建立好Athena表。
https://docs.aws.amazon.com/zh_tw/cur/latest/userguide/cur-ate-setup.html
常用CUR select 语句如下,请替换default.cur_table和bucket_name为您自己环境中的资源名。
查询结果中显示的具体的收费项目 line_item_operation在以下链接中可以找到
https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/dev/aws-usage-report-understand.html
5.根据查询结果,核算不同的方案产生的每个月费用,进行对比
关于常见的数据转换方案和优劣对比,可以参考如下表格。

6.根据核算结果,首先决定是否有数据需要删除,删除不需要的数据
S3删除数据无额外费用,所以如果经过清单分析,发现有一些数据可以删除,建议使用生命周期先对这些数据进行删除。生命周期是通过对特定标签(tag)或者前缀(prefix)进行操作,具体分为两种情况:
(1)如果可以确认某些前缀的文件可以完全删除,那么可以直接用生命周期直接对这个前缀下的文件直接删除处理(设置过期时间为1天)
(2)如果不是某个前缀下所有的文件都可以删除,那么可以选择对特定的标签(tag)操作,不过需要先使用S3批处理功能对需要的文件打标签。(注意,批处理可以替换所有对象标签,如果已有标签也会被替换掉)
然后对生成的CSV清单进行处理,S3批处理使用方式通过: s3控制台界面–批处理操作–创建作业–清单格式csv–替换所有对象标签
当批处理作业完成之后再对整桶的某个标签(tag)做生命周期删除(设置过期时间为1天)
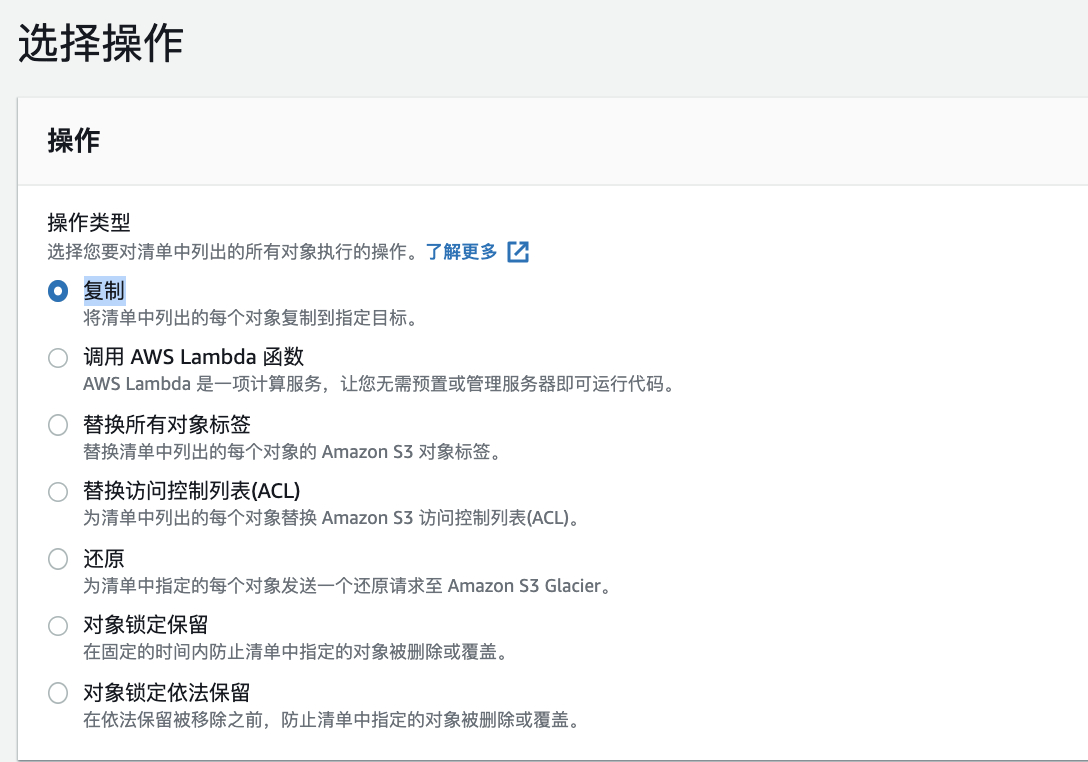
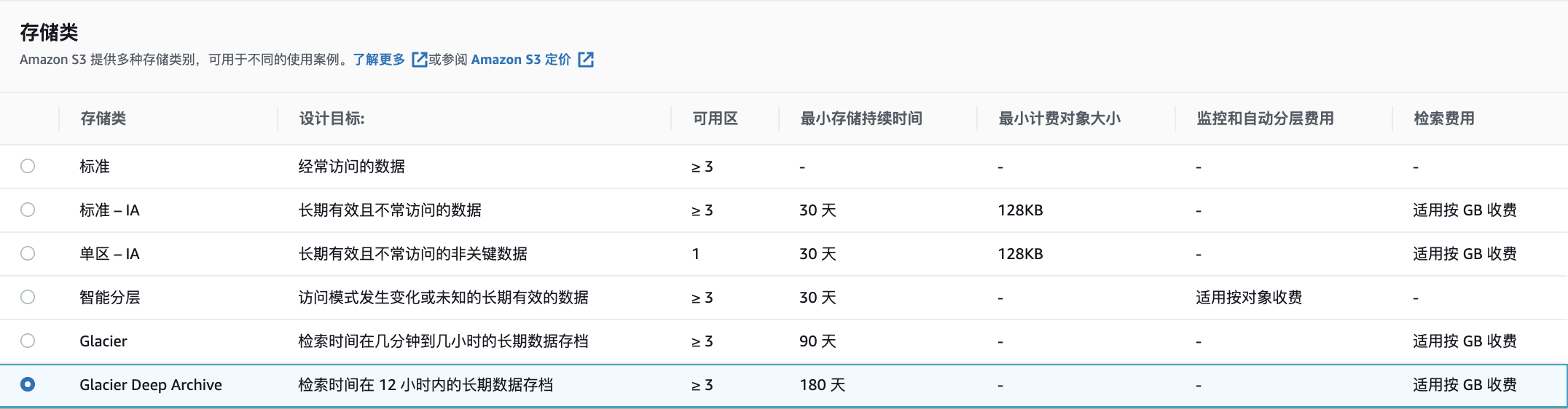
7.针对不能删除的数据,根据核算出的最佳方案,使用生命周期或者S3批处理来进行文件存储类型转换,完成优化。
对于生命周期的使用就不再赘述(参见步骤5中的方案比较)。使用S3批处理转换存储类型通过 : s3控制台界面à批处理操作–创建作业–清单格式csv–复制–选择存储类, 选择以下选项,其他设置请保持默认。

总结
请关注我们系列中的下一篇博客文章,在该文章中,我们会详细列举一下S3优化过程中遇到的常见问题,以及如何解决。
本篇作者
相关文章
- Ceph RocksDB 深度调优
- DanceNN:字节自研千亿级规模文件元数据存储系统概述
- 如何使用 Wireshark 分析 TCP 吞吐瓶颈
- 数据科学家共享代码块的几个新方法
- 如何使用 K8spacket 和 Grafana 对 K8s 的 TCP 数据包流量进行可视化
- Vue.js设计与实现之六-computed计算属性的实现
- Redis常用数据结构介绍和业务应用场景分析
- 快用上PerformanceObserver,别再手动计算首屏时间了
- 搜索引擎分布式系统思考实践
- 解析分布式系统的缓存设计
- Rb(redis blaster),一个为 Redis 实现 non-replicated 分片的 Python 库
- 20款优秀的数据可视化工具 (建议收藏)
- 轻松三步搞定数据统计分析:统计+分析+可视化!
- 实战 | CentOS 7 安装 Oracle 19c
- 一篇带给你索引技术之位图
- 如何判断某网页的 URL 是否存在于包含 100 亿条数据的黑名单上
- 从 React 源码的类型定义中,我学到了什么?
- OpenHarmony3.1特性解析-分布式数据对象源码分析
- 从微服务角度比较Kafka与Chronicle
- 五一去哪里人最少?爬取3000条数据,分析出性价比最好的地方