
探索ClickHouse与Amazon S3结合使用的三种方法
ClickHouse简介
ClickHouse是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yandex公司开发,于2016年开源。ClickHouse作为交互式分析领域的后起之秀,发展速度非常快,目前在GitHub 上已收获 14K Star。
 ClickHouse主打顶尖的极致性能,每台服务器每秒钟可以处理数亿至数十亿多行或者是数十GB的数据。ClickHouse基于列式存储,通过SQL查询海量数据并实时生成分析报告。ClickHouse充分利用了所有可用的硬件优化技术,以尽可能快地处理每个查询。向量化的查询执行引入了SIMD处理器指令和运行时代码生成技术。列式存储的数据会提高CPU缓存的命中率。ClickHouse概览文档中的图片清晰地展示了行式存储与列式存储在OLAP领域中的速度差距。
ClickHouse主打顶尖的极致性能,每台服务器每秒钟可以处理数亿至数十亿多行或者是数十GB的数据。ClickHouse基于列式存储,通过SQL查询海量数据并实时生成分析报告。ClickHouse充分利用了所有可用的硬件优化技术,以尽可能快地处理每个查询。向量化的查询执行引入了SIMD处理器指令和运行时代码生成技术。列式存储的数据会提高CPU缓存的命中率。ClickHouse概览文档中的图片清晰地展示了行式存储与列式存储在OLAP领域中的速度差距。
图1 – 行式存储

图2 – 列式存储
在分布式集群中,副本之间的数据读取会自动保持平衡,以避免增加延迟。同时,ClickHouse支持多主异步复制模式,这种情况下所有节点角色都是相等的,可以避免出现单点故障,单个节点或整个可用区的停机时间并不会影响系统的读写可用性。
在网络和应用分析,广告网络和实时出价,电信,电子商务和金融以及商业智能等领域,ClickHouse都有很好的支持与应用,更多信息请参考ClickHouse官网。
ClickHouse与对象存储
ClickHouse针对数据量和查询场景提供了不同的数据库和数据表引擎,此外它也可以使用多种多样的专用引擎或表函数(例如HDFS,Kafka,S3等)与许多外部系统进行通讯。在现代化的云架构中,对象存储是最重要的存储组成部分。2006 年,AWS 正式推出的第一个云服务也是 Amazon S3(Simple Storage Service),目前Amazon S3 已经成为事实上的云对象存储标准。
使用对象存储可以给数据分析系统带来诸多优势。首先,它可以使用数据湖架构中的原始数据。其次,对象存储可以为数据表数据提供高性价比且高可靠性的存储。针对S3目前ClickHouse已经上述对象存储的这两种用途。
ClickHouse与S3结合的三种方法
1)通过MergeTree表引擎集成S3
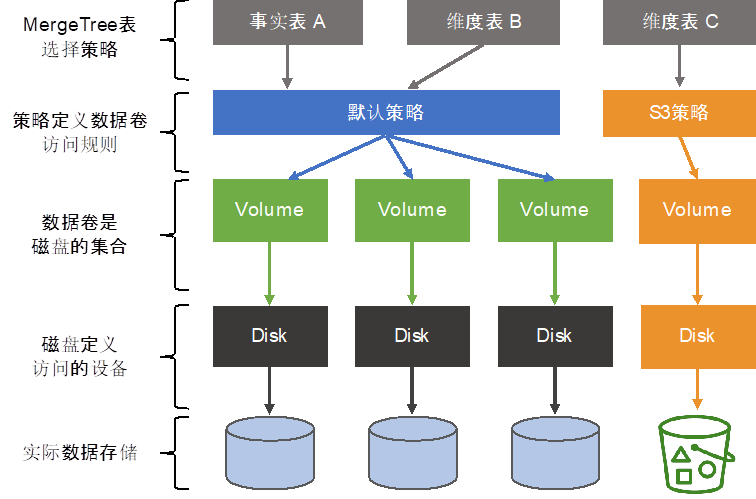
前面提到ClickHouse提供了众多数据库和数据表引擎,这其中最强大的表引擎当属 MergeTree (合并树)引擎及合并树系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入海量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
MergeTree 系列表引擎可以将数据存储在多块设备上。这对某些可以潜在被划分为“冷”“热”的表来说是很有用的。近期数据被定期的查询但只需要比较小的磁盘存储空间。相反,大量的、详尽的历史数据被用到的频率相对较少。ClickHouse可以将S3对象存储用于MergeTree表数据,这样针对“热”的数据,可以放置在快速的磁盘上(比如 NVMe 固态硬盘或内存中),“冷”的数据可以存放在S3对象存储中。在MergeTree 系列表引擎中使用S3的参考架构如下图所示:
2)通过S3表引擎集成
除了MergeTree表引擎,ClickHouse还直接提供了专用的S3表引擎,进一步加强了Amazon S3生态系统的集成,可以充分利用数据湖中已有的各种开放数据格式例如Parquet。通过以下语句就可以进行S3表引擎的创建:
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])
3)通过S3表函数集成
ClickHouse提供表接口的方式对S3中的文件进行SELECT/INSERT操作,这种方式使用起来更加方便,可以快速与ClickHouse中已有的数据进行连接等操作。通过以下语句就可以使用S3表函数:
s3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])
上述方式分别适用于不同的应用场景,可以根据具体情况进行单独或者结合使用。
此外,可以看到这里面还涉及到S3访问权限的安全问题。 在ClickHouse 20.13之前的版本中,必须要在SQL或ClickHouse存储配置中提供AWS的访问密钥(Access Key和Secret Access Key)才能访问,这是既不安全也不方便的模式。但是在20.13版本中,ClickHouse提供了实用IAM Role访问方式,解决了访问S3的安全性问题。
示例参考架构
接下来,我们将演示如何实现上述介绍的ClickHouse与S3结合的三种方法。演示的参考架构如下图所示,我们将ClickHouse环境部署在一个VPC私有子网中,然后通过VPC Enpoints内网的方式来访问S3中的数据。

在示例中,我们将使用纽约出租车数据,该数据分析是Kaggle竞赛的著名赛题之一,也是学习数据分析的经典练习案例,项目数据可以从NYC网站上进行下载,这里选取了2020年6月的Yellow Taxi Trip Records数据。
以下示例的操作环境为AWS 中国(北京)区域。
1)创建S3存储桶
首先,在AWS 中国(北京)区域创建存储数据的S3存储桶,例如clickhouse-shtian。

2)下载数据并上传到S3存储桶中
首先,在NYC网站上将2020年6月Yellow Taxi Trip Records数据下载下来,然后上传到刚刚创建的S3桶中。

3)创建并配置S3的VPC Enpoint
VPC Enpoint的创建和配置请参考VPC文档,确保子网路由表中包含下图中第二条路有条目。

4)部署ClickHouse
示例操作系统为Amazon Linux 2,ClickHouse版本为20.13.1.5591,演示使用单点部署模式,实际使用环境建议部署集群模式,提升高可用的同时也增加性能。需要注意的是在创建EC2实例过程中需要配置IAM角色,可以参考文档适用于 Amazon EC2 的 IAM 角色进行设置,并确保这个角色具有S3桶的读写权限。

SSH登录到EC2实例上,然后下载对应版本的安装包,然后解压并安装。
安装成功后,后看到如下提示:
根据提示使用以下命令启动clickhouse-server服务:
sudo clickhouse start
执行命令clickhouse-client启动客户端,可以看到连接到服务器并
5)配置ClickHouse实现通过MergeTree表引擎集成S3
创建并编辑ClickHouse配置文件,ClickHouse的主配置文件通常在/etc/clickhouse-server/config.xml,其他附加配置我们可以通过在/etc/clickhouse-server/config.d/添加xml文件来设置,也方便配置的扩展。
sudo vim /etc/clickhouse-server/config.d/merge-s3.xml
复制一下内容到文件中,其中use_environment_credentials表示通过IAM的角色、环境变量或者.aws中的安全配置来访问S3。注意替换endpoint部分对应的S3存储桶和路径:
编辑/etc/clickhouse-server/config.xml,修改openSSL中的client配置,添加一行<caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig>,设定SSL/TLS访问的CA证书。如果想使用S3的http端点,则无需配置此选项,但是会存在数据传输安全风险,因此建议使用上面的https的端点并进行如下配置。
此外,根据操作系统不同,caConfig选项可能不需要单独添加。实际测试在使用Ubuntu 18.04的时候,ClickHouse会自动找到CA证书的位置,无需额外配置。但是,在使用Amazon Linux 2操作系统时需要配置上述选项,否则ClickHouse找不到CA证书的位置,并且会报如下证书错误:
重启clickhouse-server使配置文件生效:
sudo clickhouse restart
启动客户端clickhouse-client,创建MergeTree引擎的数据表,并选择定义好的S3存储策略:
插入2行测试数据:
INSERT INTO default.s3mergetree VALUES (1, 'Vendor1') (2, 'Vendor2')
然后查询这个数据表:
SELECT *
FROM default.s3mergetree
返回结果如下,查询成功:

可以看到ClickHouse中磁盘上保留了ClickHouse中数据存储结构,包括数据bin文件、分区信息、索引等内容。

但是实际上数据文件中并没有保存真实的数据,而是存储了S3数据的链接。

查看S3中的数据信息,数据文件是长这个样子的:

尽管原来在块存储中需要硬链接的合并、变异和重命名操作现在是在引用上操作的,S3数据完全没有被触及,但是通过查看上述文件结构发现这会导致另一个问题,就是针对这些数据并没有办法通过其他数据分析工具进行处理,因为ClickHouse本身也是采用的专有数据存储格式,这也是该方案的一个弊端,借助了MergeTree的好处但仅仅是使用S3做为存储。
6)配置ClickHouse实现通过专用表引擎集成S3
创建并编辑ClickHouse配置文件:
sudo vim /etc/clickhouse-server/config.d/table-s3.xml
复制一下内容到文件中:
重启clickhouse-server使配置文件生效:
sudo clickhouse restart
启动客户端clickhouse-client,创建S3引擎的数据表:
然后进行基本的查询:
返回结果如下,查询成功:

需要注意的是,插入数据在这种情况下也是支持的,但是如果表是使用单文件定义的(如本示例),那么插入会覆盖当前文件的内容。如果是使用通配符的方式进行定义(如*.CSV),在插入数据的时候会写到*.CSV,目前已经将问题反馈提交到ClickHouse开源社区。因此,建议目前使用这种方法时,只去查询S3中的数据。
该方案的优势在于对于已有的数据湖中的数据,比如各种开放数据格式CSV、Parquet等,都可以通过ClickHouse进行查询,无需作出额外的改动,趋于LakeHouse这样的新架构。
7)配置ClickHouse实现通过专用表函数集成S3
在步骤6中的配置etc/clickhouse-server/config.d/table-s3.xml对S3专用表函数也是生效的,所以直接在客户端clickhouse-client继续进行查询即可:
返回结果如下,数据查询成功:
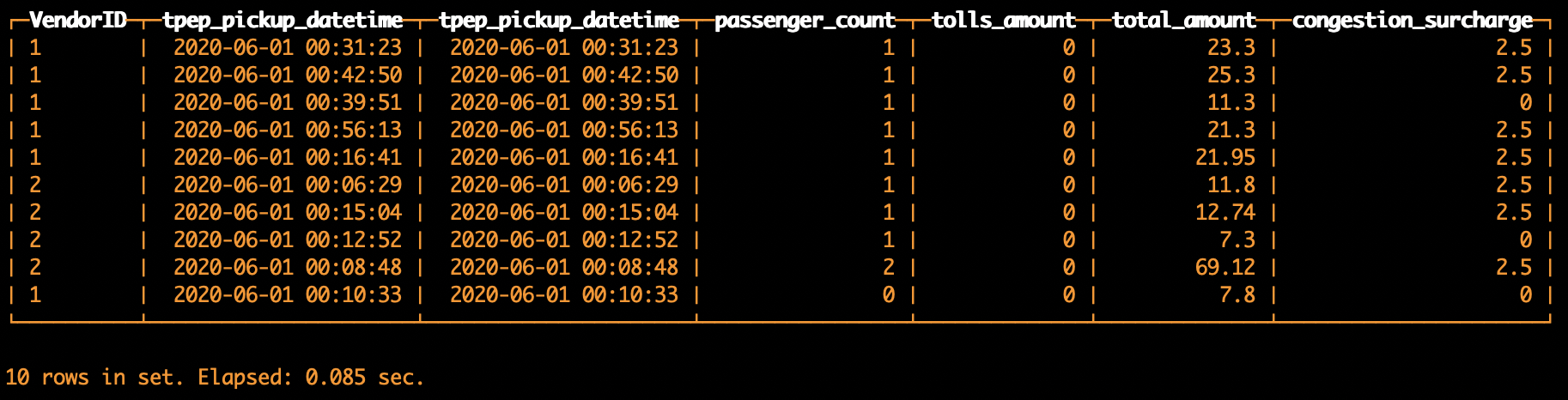
除了单独使用S3表函数,还可以和其他MergeTree表进行连接,例如我们可以使用以下SQL将S3表函数和步骤5中创建的表进行JOIN查询。
返回结果如下,数据查询成功:

该方案同样发挥了数据湖的价值,可以和已有的各种开放数据格式CSV、Parquet等数据进行连接,扩展了数据仓库的使用范围。
通过上述演示,可以基本实现不同应用场景下的ClickHouse和S3结合。由于ClickHouse是开源项目,所以和S3的集成和更丰富的特性还在逐步完善中。
小结
本文首先简单介绍了ClickHouse及其特性和使用场景,然后介绍了通过与Amazon S3存储的结合,可以为数据分析系统带来的优势:成本优化以及数据湖的应用。接下来,我们又介绍了ClickHouse和S3集成的三种方案,并通过具体示例来展示了各方案的具体实现方法和优劣势。
参考资料:
https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage
https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/
https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/
本篇作者
相关文章
- SAP云上自适应跨可用区高可用方案
- 在Amazon Web Services打造端到端语音识别应用之模型训练
- JAVA NIO详解
- 全方位保护您在Amazon S3的数据资产系列I-访问控制详解
- java.sql.SQLSyntaxErrorException
- 在亚马逊云科技上构建智能湖仓
- 新增功能 – 在 AWS Outposts 上创建 Microsoft SQL Server Instances of Amazon RDS
- 新的 Amazon FinSpace 简化了金融服务的数据管理和分析
- 从ELK/EFK到PLG – 在EKS中实现基于Promtail + Loki + Grafana容器日志解决方案
- AWS Backup的优势功能和最佳实践
- Redshift表设计优化 – 优化已有数据表中的列大小
- 使用Amazon RDS for Oracle配合Oracle Active Data Guard建立托管的灾难恢复与只读副本
- 使用Amazon Elasticsearch Service在Amazon DocumentDB (兼容MongoDB)的数据上运行全文搜索查询
- 通过Amazon CloudWatch配合Amazon ElastiCache for Redis遵循监控最佳实践
- 使用面向 Amazon Aurora PostgreSQL 的 Amazon Aurora 全球数据库 进行跨区域灾难恢复
- 亚马逊云科技数据库迁移服务:帮助客户摆脱陈旧数据库的桎梏
- 重要注意事项:如何将Amazon RDS与Amazon Aurora数据库迁移至Graviton2
- 为Amazon DMS数据库迁移任务建立自动化监控机制
- 使用 AWS Cloudformation 在 Amazon EMR 中一分钟配置 JuiceFS
- 快速落地AWS智能工厂解决方案