
金蝶发票云SaaS服务应用现代化改造之旅
ISV在开发和运维SaaS应用时,需要考虑的一个核心问题是如何实现新租户的0摩擦快速部署(Frictionless provision ),并在用户数量和工作负载激增情况下,仍能在保证用户极致体验和降低运营成本。使用传统的虚拟机模式运营SaaS系统,应用的可移植性和可观测性都受到极大限制。由于部署环境的差异,ISV往往需要几天甚至几周的时间才能部署一个新环境;监控指标通常也仅限于虚拟机层面,难以获得对服务的深入洞察,根据服务用量进行合理的容量调整更是无从谈起。
本博客结合金蝶发票云从传统的虚拟机部署迁移至基于ECS的容器化部署的真实案例,分享了发票云在虚拟机环境下运行SaaS应用遇到的挑战,使用Amazon ECS进行平台迁移的原因,以及迁移的过程及问题解决,最后介绍迁移完成后的实际收益。
基于传统虚拟机部署SaaS应用的挑战
金蝶发票云是金蝶子公司,通过SaaS模式为金蝶ERP客户提供完整的发票生命周期管理。对大客户,通常使用单租户垂直方式部署,保证用户对性能和安全的隔离要求;对小微客户,则提供多租户共享模式,体现价格优势。
随着金蝶业务的飞速扩展,发票云作为金蝶ERP的基础组件,承载的客户数量早已超过数万家,每年更有大量大型新增租户不断入住。业务的发展对运维效率、开发敏捷和成本优化方面都提出了更高的要求:
- 运维效率
当前应用是基于Spring cloud开发的微服务,全部部署在ec2上。单租户模式下的新租户部署,涉及到配置修改、IP变化,所有微服务需要单独部署、单元测试、集成测试,入住时间往往长达几周;而多租户模式,切入新用户后,服务容量是否需要调整也缺少准确的指标数据支撑。
服务与基础架构的紧密耦合导致了业务需求与运维的矛盾,难以进行有效的扩容和监控。
- 开发敏捷
新业务在上线前,通常需要运维团队做资源需求评估,并在必要时发起资源申请流程;而对已有业务的功能迭代,一旦涉及到配置修改、依赖库的变更,也需要向运维团队同步相关变更。
服务与配置的紧密耦合增加了开发与运维的沟通成本,难以提升新业务上线效率。
- 成本控制
每个租户对不同服务的使用模式往往难以预测。如何更有效地设置初始配置,并灵活地随需而动,从而在规模部署下不断摊薄成本也是发票云长期关注的问题。
为解决这些问题,发票云抱着开放的态度不断探索企业现代化的应用改造途径,通过将现代基础架构、云原生应用平台和自动化运维结合在一起,以最大程度地提高弹性、工程效率和业务敏捷性,对原有技术应用进行了重新平台化。
SaaS应用的改造策略与整体架构设计
发票云结合自身的业务和技术特点,选择了微服务容器化+容器平台托管化+运维自动化的改造策略推行了自身的应用系统现代化改造:
- 微服务容器化:
对每个Spring boot微服务、相关的配置及依赖库进行镜像打包,提升应用的可移植性和性能隔离。
- 容器平台托管化:
使用Amazon ECS容器编排服务自动实现容器生命周期管理和监控。并引入现代化计算资源serverless、Fargate等无服务器管理模式,避免人工对虚拟机的补丁、更新,进一步降低运维需求。
- 运维自动化
通过DevOps的一体化建设,实现自动化的CI/CD、一键部署及全景化运维,实现运维平台的现代化。
整体的架构图设计如下:
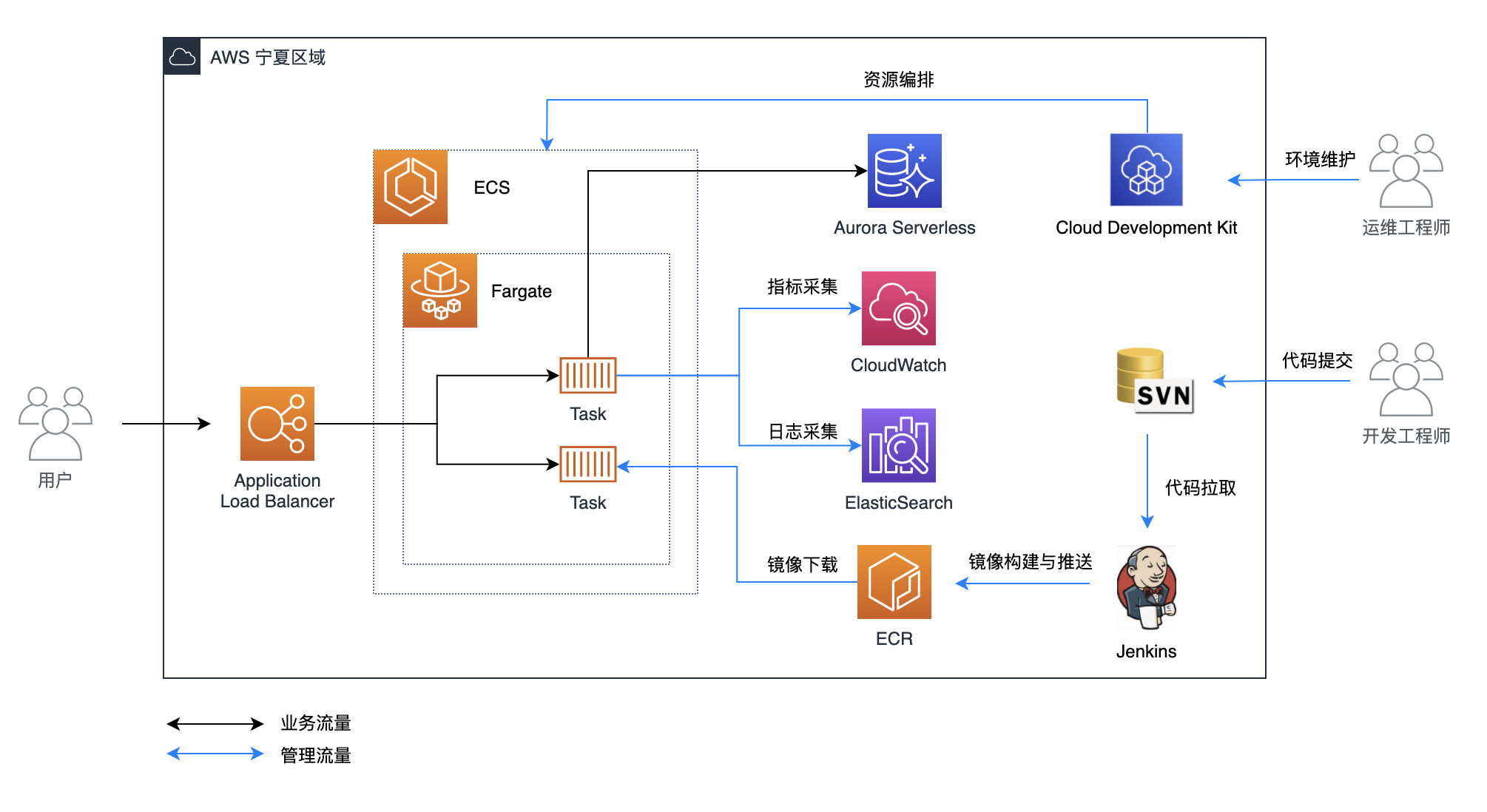
在整体设计上,我们使用了ECS + Fagate作为容器运行的平台。 ECS是AWS提供的原生的容器编排环境,功能丰富而且使用简单,与AWS的其他服务,如容器镜像管理、网络、日志与监控等服务都有开箱即用的集成方式,简化了迁移和后续运维的工作量。同时在计算资源上我们选择了Fargate来运行容器。Fargate是AWS上以无服务器的方式来运行容器的一种方案,用户可以不必管理容器底层的虚拟机,进一步减轻运维工作量。
同时,对于一些相对独立的功能模块,我们也尝试使用AWS Serverless来进行重建,比如说Lambda和API Gateway等,以便更进一步对应用进行现代化改造,提高开发和运维的效率。关于我们在AWS Serverless上的尝试,可以参考这个博客。
接下来我们就从这三个改造策略出发,详细介绍发票云的SaaS服务从Spring Cloud向ECS迁移的应用现代化改造之旅。
1.微服务容器化
迁移过程中,我们本着先迁移再优化的原则,在最大程度保留原有系统框架基础上,将原有的服务网关zuul、微服务应用、注册服务Eureka、配置服务appllo容器化。仅用2周时间就完成了核心应用的容器化改造。
如下以网关服务为例介绍典型的Spring Cloud微服务的容器化方法:
1.1 容器镜像构建
首先我们需要准备一个基础镜像,安装好相应的Java运行环境和必要的工具。基于这个基础镜像我们再分别对不同的微服务打包对应的容器镜像。
因为我们保留了原来使用的 Eureka 作为注册中心,因此需要处理好Eureka的注册问题。Eureka是Spring Cloud提供的一个注册中心,容器启动后微服务需要向 Eureka Server进行服务注册。在EC2环境下 Eureka Client 启动时会正确获取到EC2的IP并进行注册,但在 ECS/Fargate下面,我们需要稍微多做一步,在Client启动时指定正确的容器IP。
在ECS/Fargate环境下,使用 awsvpc网络模式启动的任务对应的容器都会收到预定义地址范围内的一个 IPv4 地址。Fargate提供了任务元数据终端节点(Task Metadata Endpoint) ,以帮助运行在容器内部的程序可以通过访问该终端节点以获取任务相关的信息,包括容器IP。
因此在 Dockerfile 中我们可以通过 ENTRYPOINT 指定容器启动时运行脚本,在该脚本中设定相关的客户端启动参数:
Dockerfile:
entrypoint.sh :
Bash
#!/bin/sh
##从任务元数据获取container的IP地址,结果形如"172.3.0.3"
export ECS_INSTANCE_IP_ADDRESS=$(curl --retry 5 --connect-timeout 3 -s ${ECS_CONTAINER_METADATA_URI_V4} | /jq ".Networks[0].IPv4Addresses[0]")
##去掉IP地址上的引号,保留IP地址值
export IP_ADDRESS=$(echo $ECS_INSTANCE_IP_ADDRESS | sed 's/\"//g')
##启动java进程,并以container的ip地址注册到eureka
exec java -Deureka.instance.ip-address=${IP_ADDRESS} -Deureka.instance.instance-id=${IP_ADDRESS} -jar /demo.jar 1.2 容器镜像存储另外注意到上述启动脚本文件中,Java程序启动时需要在前面指定 exec , 确保 Java 程序启动后可以正常捕获到容器停止的相关信号,并进行优雅退出,以确保及时更新 Eureka 注册信息。相关的细节会在后面关于“滚动升级”的章节进行详细阐述。为实现容器镜像的完全托管,我们使用Amazon ECR作为镜像仓库。这不但免去构建自建镜像仓库的繁琐,同时Amazon ECR 还支持与ECS和Fargate的无缝集成,大大简化了开发到生产的工作流,实现一键式部署。
通过ECR创建repository。本地构建的docker image推到ECR镜像仓库保存。
Bash
#使用具有访问ecr权限的iam用户登录ecr镜像仓库
aws ecr get-login-password --region cn-northwest-1 | docker login --username AWS --password-stdin AccountNo.dkr.ecr.cn-northwest-1.amazonaws.com
#将本地image推送到ECR镜像仓库
docker tag myimge:latest ECR_REPOSITORY_URI:latest
docker push ECR_REPOSITORY_URI:latest
2. 容器平台托管化
我们使用了ECS来做为容器编排工具。ECS是一个完全托管的容器编排服务,可以快速部署、管理和扩展容器化的应用程序。ECS与 AWS 平台上的许多服务都有比较好的集成,包括容器镜像仓库、指标监控、负载均衡和自动伸缩等。
2.1 ECS基本概念介绍
ECS的架构非常简单,上手非常快,这里简要介绍下三个最基本的概念:
- 集群(Cluster)
是一个逻辑的命名空间,里面会有任务或服务
在ECS中,我们可以选择将任务运行在EC2实例或是Fargate上面。为了简化后续的运维工作,我们选择将任务运行在Fargate上面。使用 AWS Fargate,用户就不必再管理虚拟机集群即可运行容器。因此也无需花时间去对服务器类型进行选型,也不需要去管理虚拟机的伸缩,有效减少运维工作量。
- 任务定义(Task Definition)
任务可以包含一个或多个容器,类似于Kubernetes里的Pod。ECS中的任务定义是用于通知ECS如何用EC2或Fargate类型实例化容器
- 服务(Service)
服务用于对任务运行的目标状态进行描述,并负责达到并维护这个目标状态。任务若运行失败,服务会自动启动新的任务来替换。通过服务可以配置负载均衡、弹性伸缩以及任务的滚动升级等
2.2 ECS 集群(Cluster)整体设计
在整体的ECS集群设计上,我们重点对SaaS服务的隔离性进行了设计:
首先,我们通过VPC来对不同的环境进行隔离,即开发、测试与生产分别使用不同的VPC,因而在网络上实现完全隔离,避免由于人为操作的误操作导致生产事故。

其次,我们会通过ECS Cluster来进行租户的隔离:在生产环境中,我们为大客户构建了独立的ECS cluster实现应用的隔离。并且在任务定义中,我们不同的Cluster会使用不同的任务角色,从而来限制不同集群的任务对后端服务的访问权限:

2.3 任务定义(Task Definition)
ECS中我们通过任务定义来描述容器的运行方式,诸如使用的Docker镜像、CPU和内存资源、启动类型和网络模式等等。这里将重点阐述项目涉及的几个重要的设置:
- 健康检查:这是ECS用于检查容器是否健康的方式。缺省情况下容器端口可达即认为健康,也可以通过客户化脚本制定健康检查机制。ECS如果发现容器处于非健康状态,则会自动停止相应的任务并重启,保证服务状态的达成。在项目中,我们判断一个容器是否健康,是通过检查该容器承载的sprint boot应用是否成功注册到Eureka server来确定。具体的健康检查方法请参见4.3滚动升级的问题解决。
- 日志输出:ECS中的容器可以与多种log driver相集成,极大便利了我们原有系统迁移至容器后的日志输出以及与原有的日志分析系统相集成。在项目中,我们使用了 AWS Firelens,利用AWS提供的Fluentbit 镜像,以side car的方式与现在业务容器部署在同一个任务中,实现对日志文件的收集和输出,具体内容请参见2 日志采集与分析。
2.4 服务(Service)
我们通过服务来定义任务的目标状态,ECS负责完成状态的达成和守护,这正是ECS的关键价值所在。下面我们分别通过在任务放置、自动收缩和版本升级几个方面阐述ECS在我们的SaaS应用运维中体现的价值。
2.4.1 任务放置
以前在虚拟机上直接部署应用进程时,我们需要根据自己总结的规则人工选择合适的实例进行进程放置,难以保证任务放置的合理性。而ECS平台则为用户提供了完整的任务放置引擎,用户无需构建、运行和管理自己的调度和放置服务。
如果使用EC2作为资源启动类型,ECS平台按照下图的步骤自动选择EC2实例放置:先过滤掉不满足CPU、内存和端口要求的资源;再根据用户定义的放置约束(如可用区限定、OS类型限定等)过滤掉不满足约束的资源;最后根据用户选择的放置策略对符合条件的实例进行随机放置(random)、根据指定的属性如可用区做均匀放置(spread),或最大限度地密集放置,选择剩余内存或CPU最小的实力进行放置(Binpack)。更多详细内容请参见https://aws.amazon.com/blogs/compute/amazon-ecs-task-placement/

如果使用Fargate作为资源启动类型,则完全不用再有任务放置的困扰。在本次迁移中,我们选择fargate后只需定义每个服务的任务数量和自动伸缩规则,实际任务扩缩由ECS平台自动管理,就很好地解决了以往SaaS应用中负载突增情况下的任务放置的问题。
2.4.2 自动伸缩
ECS中对服务的自动伸缩支持也是ECS平台对应用进行管理的关键价值体现。自动伸缩通过设定任务数的上限、下限和期望值以及扩展策略对伸缩进行管理。而ECS通过与CloudWatch 指标(包括服务的平均 CPU 和内存使用率)以及ALB请求数指标相集成,实现基于关键指标的伸缩。
项目实施中,通过设定服务的autoscaling策略实现多租户模式下任务根据负载变化的自动放缩,很好地解决了新租户切入后资源调整的准确性,同时也提升了运维的效率。

2.4.3 版本升级
ECS提供了两种版本升级策略,分别是滚动升级和蓝绿部署。
- 滚动升级:这是由ECS完全托管的版本更新策略,简单易用。运维人员升级ECS 服务时只需更新容器镜像,ECS会自动启动指定数量的最新版本容器替换旧的容器。替换过程中,ECS通过对新容器做健康检查确保升级成功,再自动停止旧版本,实现无缝升级。我们可以设定服务部署期间允许的最小和最大健康任务数量来控制滚动更新期间从服务中添加或删除的容器数量。
- 蓝绿部署:ECS通过与CodeDeploy集成实现蓝绿部署,该方式的特点是允许新旧版本同时启动,通过逐步切分生产环境流量实现对新版本的功能验证,同时保留蓝色版本以便问题情况下的快速回退。该部署模式为负载均衡器创建两个目标组和两个侦听器端口,分别对应蓝、绿版本的服务,完成测试后可以通过修改侦听器规则最终将流量发送到绿色版本完成升级部署。
目前我们选用了ECS滚动升级方式实现版本更新。该方式简单便捷,完全依托ECS实现新旧版本的自动更替。我们在向ECR提交新版本镜像,并完成ECS任务定义更新后,只需更新并重新启动对应的ECS服务,ECS就会通过滚动升级策略自动完成版本升级。整个升级过程无应用中断时间,可实现无缝升级。
在服务配置部分,我们使用最小正常运行百分比100%,最大百分比200%。使用该配置,当提交新版本时,ECS会先保持旧版本服务全部可用(即旧版本正常运行100%),同时启动同等数量的新版本(即新旧版本加起来为200%)服务。确定新版本服务完全可用后,就删除旧版本服务,实现滚动升级。
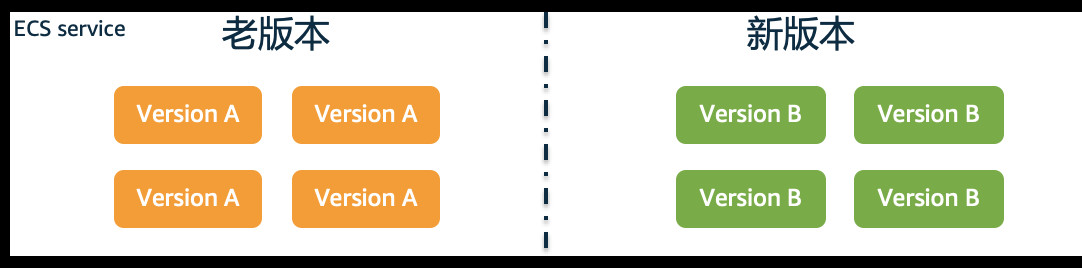
但在配置后进行实际升级过程中,我们发现了一个有趣的问题:
- 旧版本服务正常运行,并在Eureka正常注册。新版本服务执行滚动升级时服务开始启动
- 新版本服务依据service定义成功启动了指定数量的服务
- ECS监测到新版本服务启动,即将旧版本服务删除,但此时,新版本并为完成在Eureka的成功注册,即新版本并未完全Ready。
- 旧版本服务被删除后,服务大约需要等待30s左右才能从Eureka注销。
因为存在如上现象,滚动升级时会存在30s左右的真空期,即Eureka中注册的是旧版本服务,但旧版本服务已被删除;而新服务虽然启动,但新服务尚未在Eureka成功注册。这时应用请求服务时会发生报错。

经过仔细分析这里有两个问题:
1, 旧版本被ECS停止后,不能从Eureka立刻注销的问题:
经检查发现,在构建镜像时我们对jar包应用的启动方式存在问题。 一开始,我们使用如下子进程的方式启动。
对这个问题,我们改正为使用exec启动Eureka client的方式:这样的方式,ECS停止旧版本的container时,其上的子进程无法获得SIG-TERM信号,也就无法主动完成从Eureka的及时注销,而是等到通过心跳超时机制使Eureka感知服务不可达,才会被动注销。因此Eureka的服务注销会存在滞后。
2, 新版本尚未完成注册,ECS就将旧版本服务删除的问题这样服务启动后将替换原有shell主进程,在container被停止时,主进程可获得SIG-TERM,优雅完成从Eureka的及时注销。
经检查发现,缺省情况下,ECS监测到容器的端口可达即为服务已经成功启动。而从应用角度,实际需要服务在Eureka成功注册才能认为启动成功。为了解决这个问题,我们需要在ECS的任务定义中,对container启用客户化的health check,依赖Eureka 的actuator端点获取client的注册状态,新服务注册成功才对老版本服务执行停止。
这里我们再展开讲一下Spring Cloud中,Eureka Server具备的健康检查机制:
缺省情况下,Eureka server通过心跳检查client是否处于up状态。开发者可以使用application.yaml中设置healthcheck.enabled = true,客户化自己的健康检查方法以实现actuator的healthcheck。Eureka client负责根据健康检查方法检测服务状态,然后上报给eureka server。Eureka server提供endpoint为外界提供client是否健康的检查。更多详情可参考https://docs.spring.io/spring-cloud-netflix/docs/current/reference/html/。
在ECS中,我们借助对container的健康检查实现与Eureka server健康检查相结合,实现对Eureka client的的检查。我们构建的健康检查脚本hc.sh如下,这个脚本通过Dockerfile的配置,放置容器的根目录下:
 将如下健康检查命令填写在任务定义的container健康检查部分:
将如下健康检查命令填写在任务定义的container健康检查部分:

通过上述的调整后,版本升级过程出现的两个问题就得到了解决。后续我们计划基于ECS与CodeDeploy的集成来实现蓝绿部署,从而进一步降低新版本的发布风险。通过切分的部分流量验证新版本,并在必要时能及时完成将流量快速回滚到仍在运行的蓝色环境,减少部署错误带来的爆炸半径,进一步降低整体部署风险。
3. 运维平台现代化
微服务进行容器改造后,之前基于虚拟化环境构建的监控、软件发布等相关的运维方案也需要进行相应的现代化改造,以便提高运维效率,切实发挥容器化的优势。因此,发票云在核心应用完成容器化ECS迁移之后,又分别从指标监控、日志采集与分析、持续集成与发持续部署和基础设施即代码等几方面着手进行运维平台现代化。
3.1 指标监控
ECS提供了对资源的基本监控指标,颗粒度从集群、服务到任务,指标覆盖CPU、内存、网络到磁盘读写。ECS的指标与CloudWatch集成,缺省以1分钟为间隔发送达CloudWatch,我们可以通过CloudWatch insigth对指标进行监控,满足日常运维需求。
下图从服务监控的角度展示了CloudWatch insight中对每个服务的资源使用监控。
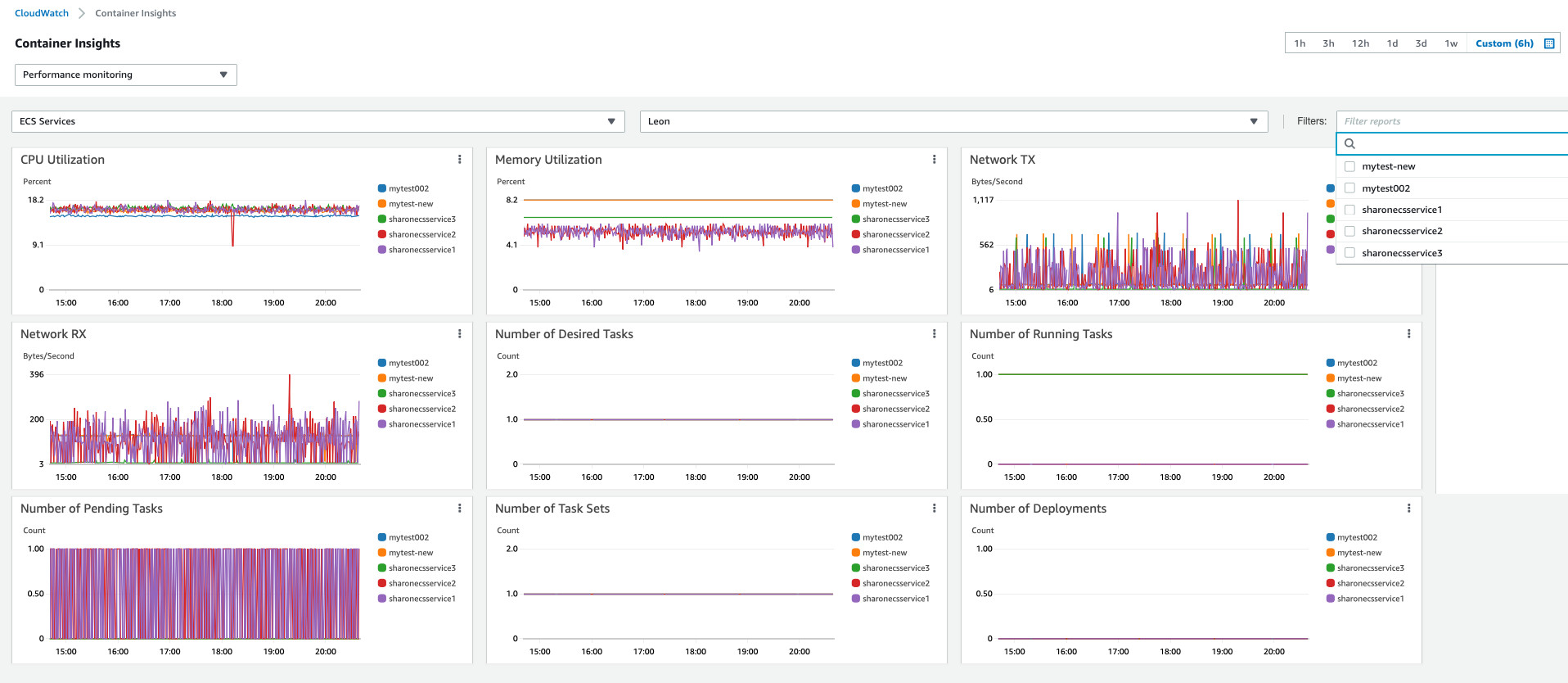
同时,还可以通过容器的拓扑图获得cluster、service与task definition的对应关系。并可以根据cpu/memory使用率较高的服务做高亮显示

这些细粒度、开箱即用的监控指标在以前通过EC2运行进程的方式是很难获得的,方便了我们日常的运维。
3.2 日志采集与分析
在ECS上进行日志采集主要有两种思路,一种是直接使用与ECS集成的Cloudwatch Logs, 在任务定义中可以选择启用 awslogs 这个 log driver, 即可将以stdout或stderr方式输出容器日志打入Cloudwatch,后续可以在Cloudwatch中利用 Logs Insights 进行日志的查询分析。另一种思路是将日志通过 Firelens 打到 ElasticSearch 并在 Kibana中进行分析,由于我们的开发团队一直使用 ElasticSearch 和 Kibana ,为保持原来的使用习惯我们选择了后者。
借助ECS推出的 FireLens工具可以将容器中的日志发出来,实现容器日志与既有日志分析系统的集成,而无需修改应用部署脚本或手动安装额外软件。FireLens 支持与 FluentBit 或 Fluentd 搭配使用,而fluentbit更加轻便。因此,项目中我们使用了FireLens for Fluent Bit 作为 Sidecar ,与应用容器运行在同一个 Amazon ECS 任务中。

如上图所示,应用容器与fluentbit sidercar共享data volume,应用容器将访问日志写入data volume的挂载目录: /data/access.log。
Fluentbit使用AWS提供的镜像,并使用如下日志收集的配置文件以tail的方式收集/data/access.log日志内容,并输出到已创建好的名为fluentbit-access的firehose datasream中。
使用如下docker配置,上传ecr构建fluentbit镜像。因为需要使用自定义的fluentbit config文件,所以需要自定义fluentbit镜像,其中包含本地配置文件extra.conf。
Dockerfile:
Extra.conf
创建名字为data的volume,用于两个container共享,app container将log输出到该volume,fluentbit从该volume读取日志发至firehose创建ecs task definition,选择enable firelens integration,image使用上面创建的fluentbit 镜像

使用json格式,告知fluentbit使用extra.conf作为配置文件:


日志接入firehose后,就可以打入发票云已有的Elastic search中,通过Kibana进行数据分析。
该部分的具体操作可以参考这篇博客https://aws.amazon.com/cn/blogs/china/easy-aws-fargate-container-log-processing-with-aws-firelens/
3.3 持续集成和持续发布
发票云开发团队目前使用SVN作为多套应用的代码管理库。在迁移的初始阶段,为了顺应开发团队的使用习惯,我们沿用现有的SVN+Jenkins方案实现面向ECS的持续集成和发布平台

如何实现Jenkins与SVN集成的相关博客已有很多,这里我们不再赘述。而是重点说明如何使用aws cli命令行与Jenkins pipline集成实现镜像的自动打包上传及部署:
我们以服务代码的SVN版本号Revison作为ECR的TAG用以区分镜像版本,便于自动化部署的版本控制管理。有这点前提,接下来的逻辑则相对简单:
1.利用aws ecr describe-images判断ECR上有没有标签为TAG(SVN Revison)的镜像,如果有对应的镜像,则后续步骤无需再执行docker build和docker push镜像,也就是略过第2步操作,直接跳到第3步。
2.以aws ecr get-login-password –region XXX | docker login –username AWS –password-stdin XXX和docker push命令,将构建好的docker容器镜像以上述的TAG(SVN Revison)打标签后push到AWS ECR上。
3.通过命令aws ecs register-task-definition –cli-input-json file://task.json –region XXX,以定义好的文件task.json的数据注册一个新的task-definition。其中task.json文件里的FAMILY_PREFIX、SERVER_NAME、IMAGE_URL、APOLLO_META、TASK_CPU和TASK_MEMORY是变量,可以通过脚本以sed -i命令根据实际情况替换为具体的数据。
4.最后通过命令aws ecs update-service将上述步骤生成的task-definition更新到对应的service当中,实现新代码的deploy。
通过以上步骤,我们实现了SVN、jenkins与ECR、ECS的集成。
3.4 基础设施即代码通过以上步骤,我们实现了SVN、jenkins与ECR、ECS的集成。
为了提高我们在基础架构运维上的效率,我们进行了基础设施即代码的改造。基于AWS CDK并使用自己熟悉的编程语言来定义AWS云上的资源,使我们尽可能做到一键部署新环境。
我们需要对平台中需要的公共资源、可重复利用资源以及需要新建的资源进行数据结构定义和声明,以便通过程序中完成自动部署。在该程序中,我们将资源定义的数据结构存储在data.json文件中。其中公共资源和可重复利用资源(如VPC,安全组等资源)只需提供资源的ARN,一般可通过资源类的fromXXX方法获取相应的资源对象进而进行后续操作;而需要新建的资源,则需要提供构造这些资源的基础信息。根据发票云现有需求,我们定义了如下图所示的几类资源。

其中ResourcesDefinition与data.json对应,是整个基础设施的数据结构类。代码如下所示,包括对网络、ecs 集群、数据库的定义:
data.json中对database和redis的定义示例:

在程序入口,首先解析了data.json文件,将我们实现定义好的数据转化为Java对象。
1.根据ARN获取公共资源或可重复利用资源,以便后续步骤构建新的资源而后再根据资源依赖关系顺序执行我们以下的业务逻辑:
2.构建ECS Cluster
3.构建配置中心,目前使用apollo
4.构建数据库(一般是从数据库快照restore)
5.构建redis
6.构建data.json定义好的所有service
上述代码具体方法的操作大多数可以参考AWS所提供的SDK文档,按照自己的业务逻辑具体实现即可。在此提供一个较为关键常用且比较有代表性的方法initService做简要介绍。
4. 应用现代化改造收益
到此我们在发票云的现代化应用改造完成了第一轮迭代。通过微服务容器化我们完成了应用与基础架构的解耦,提升了系统的可移植性和性能隔离;容器通过ECS平台托管,实现了计算资源的自动分配和服务级别的可观测性;通过运维平台的现代化,我们进行了基础架构即代码的改造,进一步降低了日常运维的人工介入。

应用改造上线后,一套完整的SaaS环境部署可以从以前的20天缩短为半天时间,使用CDK一键部署平台,运维人员仅需要几分钟就可完成新环境创建,半天内再完成集成测试就可快速上线;新服务的上线由开发人员完成镜像打包,再集成到Jenkins的自动部署流水线,新服务的上线效率从以前的几天减少到现在的几分钟;每周的运维耗时也从之前的天级降为现在的分钟级别。
当新业务上线速度开始提升后,发票云开始审视如何进一步实现微服务之间的解耦,简化服务之间的契约接口,同时学习亚马逊云科技的经验,在组织架构上进行拆分,探索小团队自主负责各自的模块开发,进一步提升开发的敏捷型。
本篇作者
相关文章
- DAPP开发如何做?区块练去中心化应用开发系统搭建
- 一些网站站长的一些可能涉及违法的行为!
- 藏书馆App基于Rainbond实现云原生DevOps的实践
- 数组应用(C): 数据求均值
- 为什么云原生应用需要云原生勒索软件保护
- 西部数码双11大促:小程序3折抢购!
- App自动化测试|adb版本过低的报错提示
- 一起玩转树莓派(18)——MPU6050陀螺仪加速度传感器模块应用
- 【微信小程序】收藏功能的实现(条件渲染、交互反馈)
- 新一代日志型系统在 SOFAJRaft 中的应用
- 如何开发DAPP去中心化应用,智能合约定制系统开发
- 微信PC端多开
- 光纤能取代网线吗?
- 看一眼肉的光泽和脂肪分层就行?日本APP正在用AI给金枪鱼分级
- 霸榜日本热搜一周!这个应用让涂鸦从纸上活过来,还能喂吃的,网友玩儿疯了
- 日本开发戒烟APP!吸烟数据联动医生,认知疗法“辅助”,老烟民了解一下?
- 近10年数据智能团队建设,联想总结了由内而外的发展经验 | 专访联想集团副总裁田日辉
- 移动端车牌识别技术的应用,大大提高路侧停车管理效率
- 轮到微软抄腾讯?小程序技术如何帮助巨头构建超级APP!
- 聚焦2021云栖大会,边缘云专场畅谈技术应用创新