
EKS集群弹性伸缩和不可变基础设施最佳实践
资源的弹性伸缩 (Auto Scaling) 是云计算的本质能力之一,是云上降本增效的重要途径,也是衡量云原生成熟度的关键因素。
依托亚马逊云计算提供的自动化能力,我们可以自动按需启动或者回收资源。在众多场景下,CPU或者内存资源的利用率会根据每天不同时段的请求量波动,当业务请求不断上涨的时候,应该自动启动资源以应对新的请求;同样的,当业务请求量下降,资源处于低利用率的情况下,就处于浪费阶段,这个时候应该自动回收资源来节省费用。
有了弹性伸缩的能力,在云上就可以实施不可变基础设施架构 (immutable infrastructure)。在这种模式中,任何基础设施的实例 (包括服务器、容器等) 在创建后便成为一种只读状态,不可对其进行任何更改。如果需要修改或升级某些实例,唯一的方式就是创建一批新的实例替换。容器天然就具备了不可变基础设施的特点,在云计算集群中我们应该对虚拟机实例也实施不可变基础设施架构。
本文将介绍如何在亚马逊云上实施弹性伸缩和不可变基础设施,并讨论两者带来的益处。在亚马逊云上,计算集群可以是虚拟机、ECS (Elastic Container Service) 节点,也可以是EKS (Elastic Kubernetes Service) 节点。本文以当前应用比较广泛的EKS集群的弹性伸缩为例进行讲解。
容器环境的扩缩容分为容器和Node集群两个层面。容器层面的扩缩容属于K8S的HPA或者VPA资源管理的范畴,在此就不做过多讲解。本文重点讨论Node集群层面的扩缩容。
Node集群层面的弹性伸缩依托Amazon Auto Scaling Group (ASG) 来实现,Node的生命周期管理主要有3个关键因素。如下图所示:
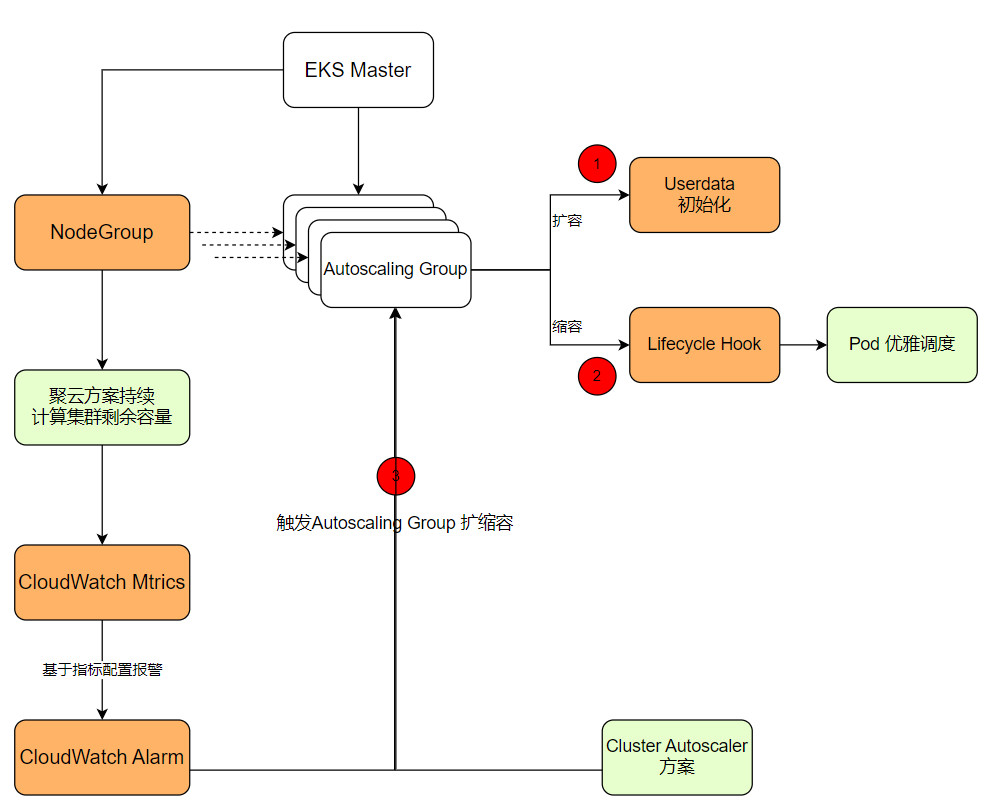
- 扩容时的初始化
Pod包含了应用相关的运行环境、代码、配置文件等所有相关资源,因此Pod扩容之后就自动进行了初始化并且开始接收请求。类似的,也可以通过一个自定义镜像来将Node的环境提前初始化,但是镜像的升级维护过程还是比较繁琐的,因此建议直接采用EKS Optimized AMI,然后通过Userdata执行初始化脚本进行初始化。这就保证同一个ASG下所有Node的配置是一致的。Node扩容相对来讲是安全的操作,不会对业务造成影响。
- 缩容时的容器优雅调度
在Pod缩容引起Node闲置资源变多的时候,Node资源就应该被回收。Node节点的回收过程需要谨慎处理,要避免缩容过程中的业务中断,需要先把节点中运行的Pod优雅调度到其他Node节点,这也是弹性伸缩比较复杂的阶段。这时候需要用到ASG的Lifecycle Hook,在实例被终止之前调用程序对Node节点进行处理:通过K8S API将Node设置为不可调度,并将Pod驱逐到其他Node中。
缩容流程能做的不仅仅是驱逐Pod,还可以通过调用Amazon System Manager的API,在实例内部运行bash脚本,在实例回收之前执行日志备份到Amazon S3等相关的操作。通过对Node外部和系统内部两个层面的调用能力,就能应对各种复杂场景下的自动缩容。
有了自动化的扩容初始化和缩容优雅调度,就实现了不可变基础设施的关键因素:
(1) 同一个ASG下所有节点都通过相同的初始化脚本进行初始化,并且在初始化过程中设置禁止对Node节点的SSH登录,保证配置一致且不被更改。
(2) 在需要对Node节点进行更新的时候,就可以通过ASG的instance refresh功能对节点自动滚动替换升级,或者通过调整ASG下实例的个数手动替换。
缩容过程中对Pod的优雅调度的实现有两种选择:
(1) 通过Lambda部署开源项目amazon-k8s-node-drainer[1]。
(2) 通过K8S deployment部署开源项目aws-node-termination-handler[2]的Queue Processor模式。
- 扩缩容的时机
有了第一和第二阶段,就可以实现半自动的扩缩容。距离自动化弹性扩缩容还有一个关键问题需要解决,它就是扩缩容的时机。
开源项目Cluster Autoscaler (CA) [3]就是用于解决这个问题。Cluster AutoScaler作为一个Pod,在Kubernetes环境中每10秒侦测工作节点的资源用量,然后决定是否扩容或者缩减特定工作节点。当集群中的Pod因为Node资源不足而调度失败时,CA会对集群进行扩容;当集群中的Node持续一段时间处于低利用率水平,同时Node中的Pod可以被调度到其他位置时,会对Node进行缩容。
扩容过程中会通过第1步所示的扩容初始化流程对Node进行初始化。缩容过程中CA会先对指定的工作节点进行Drain,然后透过TerminateInstanceInAutoScalingGroup这个API让ASG对指定的工作结点进行中止,由于指定特定工作节点是由ASG來终止,如果ASG配置了Lifecycle Hook则仍会执行。
而CA因终止特定工作节点,有可能导致不同可用区 (Availability Zone,AZ)中Node数量的不平衡,此时ASG后续可能会进行AZ再平衡,AZ再平衡是ASG的行为,CA并不知道此行为。因此,AZ再平衡需要透过第2步所示的Lifecycle Hook进行。类似的,当手动调整ASG下实例数量时,CA也不会对Node节点进行Drain,也是通过Lifecycle Hook进行的。
或者,选择聚云的弹性伸缩整体解决方案。在该方案中,通过程序持续计算ASG下的Node集群可调度Pod的数量或者Node集群剩余容量的百分比来决定扩缩容时机,并将指标推送到CloudWatch Metrics,然后通过这个指标配置Alarm来触发ASG的扩缩容。在这种情况下,Node和Pod的扩缩容是解耦的,业务可以专注自己Pod的扩缩容配置。Pod的扩缩容会导致Node可调度Pod的数量指标变化,进而触发Node的扩缩容。
例如,一个Node集群中部署了多种业务的Pod,各自业务Pod设置了HPA进行弹性伸缩,程序会持续计算Node集群当前的剩余容量可以容纳的最大配置的Pod数量。当可容纳Pod数量小于4个时触发集群扩容,当可容纳的Pod数量大于10个时触发集群缩容,其中的阈值也是可以自定义的。这种方式带来的好处就是,可以提前预留出一定数量的Node节点,当Pod扩容时直接就可以启动,而不需要等待Node就绪。
而且,这种方案也和亚马逊云灵活的风格相一致,将弹性伸缩的能力像积木一样集成到各个ASG中。
这样,我们就实现了集群的弹性伸缩和不可变基础设施,进而可以享受两者带来的好处。
- 高效利用资源
首先,开发人员为了应对流量高峰往往会提前准备过多的机器,使得服务器日常的利用率普遍低于15%。当集群具备了弹性,就可以将日常使用的机器缩减到原来的1/2,甚至更少,同时将CPU利用率提升到一个比较高的水平。
其次,如下图所示,业务请求会在每天白天和晚上有波动,Pod就可以在业务低峰期的时候进行缩容,Pod缩容使Node集群的可调度资源增加进而触发Node缩容。反之,在业务高峰期会触发Pod以及Node的自动扩容。这样,就可以在每天业务低峰期再节省数量可观的机器。

- 配置一致性
不可变基础设施使得集群下所有Node都是相同的配置,并且始终保持在最初的良好状态。这就使得集群的维护更加简单。如下图所示,如果将管理单个虚拟机比作养宠物,那么对于每一台服务器都要精心维护,避免出现问题,一旦出现问题就要紧急修复。而不可变基础设施的实例集群就像一群牛,我们对所有实例都是一视同仁,某一台实例出现问题,并不会对整体集群造成影响。

- 故障自动恢复
有了自动化作为基础,当某个实例因为物理或者软件故障导致问题时,集群会自动停掉故障实例,同时启动新的实例替代。
- NO SSH
在容器环境中,Node只是提供了Pod的运行环境,和业务无关。因此,可以在初始化的过程中禁止掉SSH登录,从而增加系统的安全性,并避免对系统的手动变更。
- 自动滚动升级
在使用EKS的过程中经常会对Master集群升级,相应的Node集群也要使用新版本的EKS Optimized AMI进行升级。如果没有自动化,那么整个过程将是非常繁琐的。有了自动化,就可以通过ASG的滚动更新功能自动替换集群的实例。下图就是ASG滚动更新功能的截图。

综上所述,弹性伸缩和不可变基础设施减少的不仅仅是资源成本,同时也降低了运维成本。本文就弹性伸缩和不可变基础设施的实现和优势提供了一点思路。资源利用率的提升是复杂的过程,而当企业经历了上云初期的业务迅猛增长之后必然进入平稳运行阶段,这时候就要对最初粗犷的云资源管理方式进行优化,提升自动化水平,减少人力维护成本以及资源浪费。这项工作做得越早获得的收益就越多。当然,更理想的情况是,从最开始上云的时候就按照云原生架构来设计,最大化利用云计算的优势。
参考文献
- https://github.com/aws-samples/amazon-k8s-node-drainer
- https://github.com/aws/aws-node-termination-handler
- https://github.com/kubernetes/autoscaler
本篇作者
相关文章
- C/C++ Qt 选择夹TabWidget组件应用
- C/C++ Qt ToolBar 菜单栏组件应用
- C/C++ Qt 基础通用组件的应用
- C/C++ Qt QChart 绘图组件应用
- C/C++ Qt QThread 线程组件应用
- C/C++ Qt 基本文件读写方法
- git指令速查
- Linux 命令(228)—— shopt 命令(builtin)
- Linux 命令(229)—— readonly 命令(builtin)
- Linux 命令(230)—— set 命令(builtin)
- 嵌入式:交换指令之SWP,MRS,MSR
- [gitlab] 分支删除触发 gitlab CI
- golang 使用 Context 实现 IoC 容器
- golang gin 使用 context 实现 ioc
- go1.17 泛型尝鲜
- golang 中的时间处理
- golang 声明变量中的下划线是什么意思
- 同一个 gitlab-ci 文件能使用多个 runner 吗?
- [golang] 环境变量操纵与踩过的坑
- golang 括号用法总结