
使用 Amazon Glue、Amazon Neptune 和 Spline 为数据湖构建数据沿袭
数据沿袭是数据湖数据治理策略中最关键的组成部分之一。数据沿袭有助于确保使用准确、完整和值得信赖的数据来推动业务决策。虽然数据目录提供了元数据管理功能和搜索功能,但数据沿袭可以更详细地捕获数据源之间的真实关系、数据来源以及数据的转换和汇集方法,从而显示数据的完整上下文。数据湖工作中涉及的不同角色可受益于数据沿袭:
- 对于数据科学家来说,在数据从源流动到目标的过程中查看和跟踪数据流的功能,有助于轻松地了解特定指标或数据集的质量和来源
- 数据平台工程师可以更深入地了解数据管道以及数据集之间的相互依赖关系
- 数据管道中的更改更易于应用和验证,因为工程师可以识别作业的上游依赖关系和下游使用情况,从而正确评估服务影响
随着数据环境复杂性的增加,客户在以经济高效且一致的方式捕获沿袭时,面临着巨大的可管理性挑战。在这篇文章中,我们将向您介绍为数据湖构建端到端的自动化数据沿袭解决方案的三个步骤:沿袭捕获、建模和存储,最后是可视化。
在此解决方案中,我们捕获粗粒度和细粒度数据沿袭。粗粒度数据沿袭通常以业务用户为目标,侧重于捕获高级业务流程和整体数据工作流。通常,它可以捕获并直观显示数据集之间的关系及其在存储层之间的传播方式,包括提取、转换和加载(ETL, Extract, Transform, and Load)作业及操作信息。细粒度数据沿袭则可用于查看列级别的沿袭以及处理和分析管道中的数据转换步骤。
解决方案概览
Apache Spark 是在数据湖中进行大规模数据处理的最流行的引擎之一。我们的解决方案使用 Spline 代理从 Spark 作业中捕获运行时沿袭信息,由 AWS Glue 提供支持。我们使用 Amazon Neptune 对沿袭数据建模以便进行分析和可视化,这是专为存储和查询高度关联的数据集而优化的专用图数据库。
下图展示了该解决方案的架构。我们使用 AWS Glue Spark ETL 作业来执行数据摄入、转换和加载。每个 AWS Glue 作业中都配置了 Spline 代理,用于捕获沿袭和运行指标,并将此类数据发送到沿袭 REST API。该后端由生产者和使用者终端节点组成,由 Amazon API Gateway 和 AWS Lambda 函数提供支持。在将传入的沿袭对象存储到 Neptune 数据库之前,生产者终端节点会对其进行处理。我们通过使用者终端节点提取特定的沿袭图,用于前端应用程序中的不同可视化。我们通过 Neptune 笔记本对图表进行临时交互式分析。
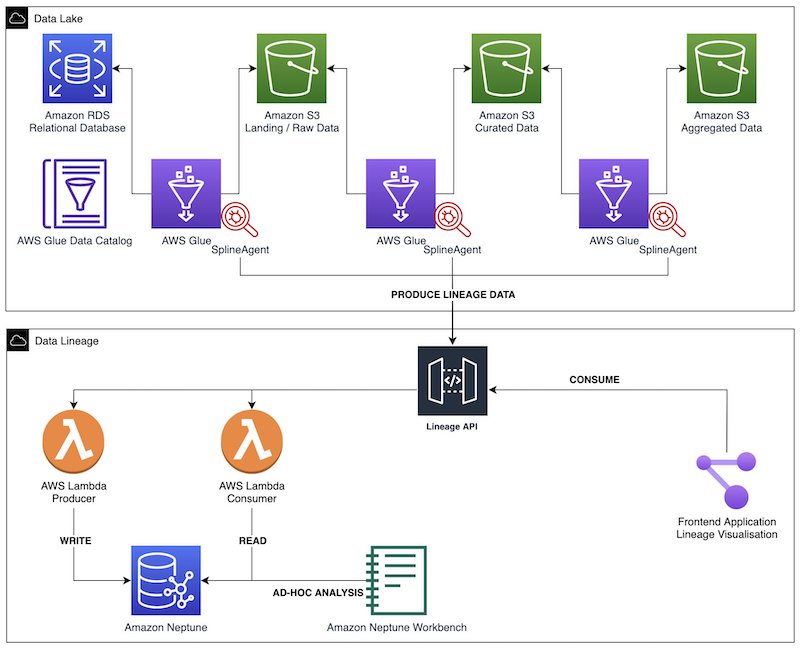
我们在 GitHub 上提供了示例代码和 Terraform 部署脚本,可用于将此解决方案快速部署到 AWS 云。
数据沿袭捕获
Spline 代理是一个开源项目,可以在运行时自动从 Spark 作业中获取数据沿袭,而无需修改现有 ETL 代码。它监听 Spark 的查询运行事件,从作业运行计划中提取沿袭对象,并将它们发送到预配置的后端(例如 HTTP 终端节点)。代理还会自动收集作业运行指标,例如输出行数。截至撰写本文时,Spline 代理仅适用于 Spark SQL(DataSet/DataFrame API),而不适用于 RDDs/DynamicFrames。
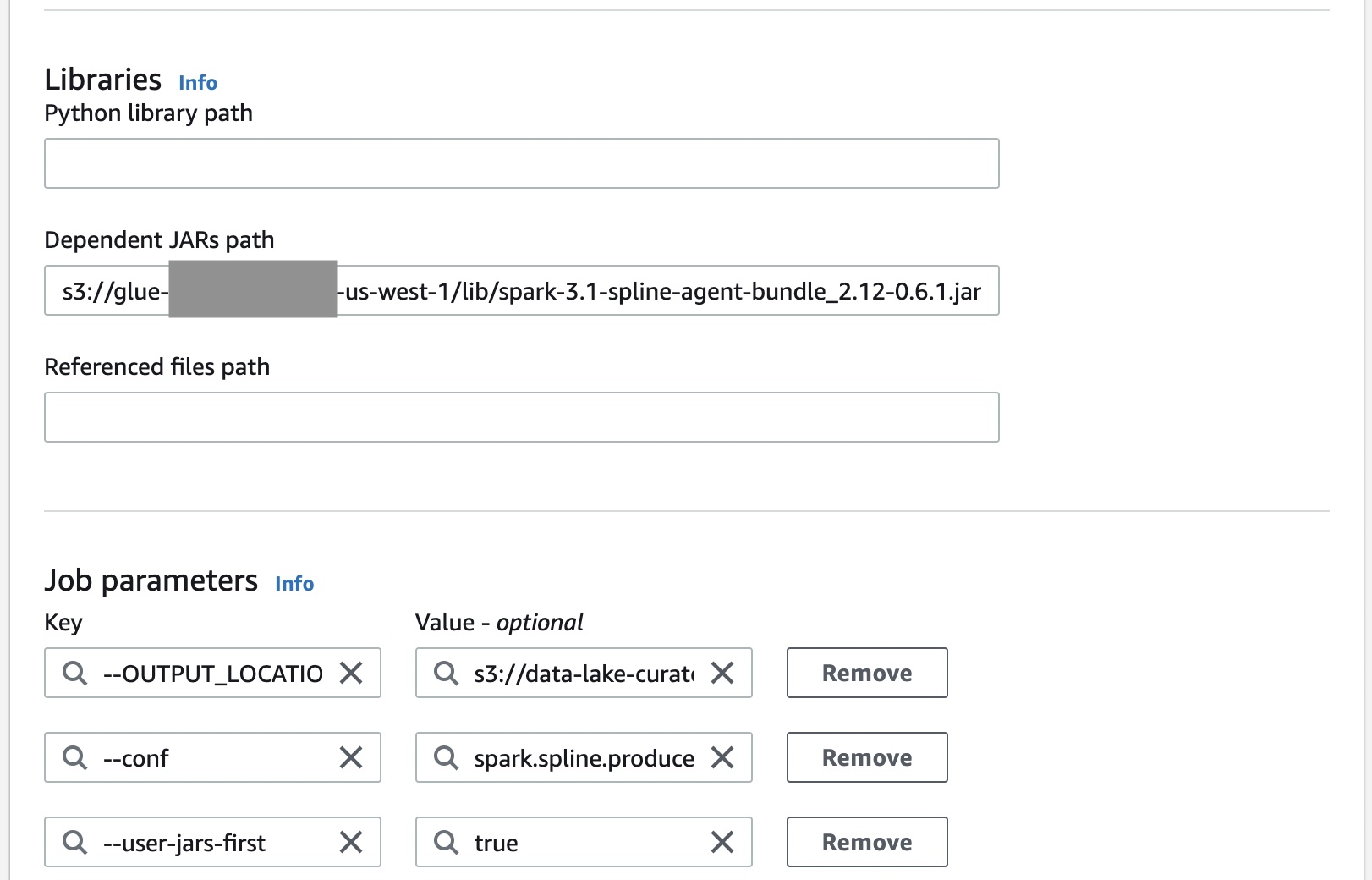
以下屏幕截图显示了如何将 Spline 代理与 AWS Glue Spark 作业集成。Spline 代理是一个需要添加到 Java 类路径中的 uber JAR。设置 Spline 代理需要以下配置:
spark.sql.queryExecutionListeners配置用于在 Spline 侦听器初始化期间注册它。spark.spline.producer.url指定 Spline 代理应向其发送沿袭数据的 HTTP 服务器的地址。
我们构建了一个与 Spline 代理兼容的数据沿袭 API。此 API 可协助将沿袭数据插入到 Neptune 数据库,以及进行图形提取用于可视化。Spline 代理需要三个 HTTP 终端节点:
- /status – 用于运行状况检查
- /execution-plans – 用于在提交作业供运行后发送捕获的 Spark 执行计划
- /execution-events – 用于在作业完成时发送作业的运行指标
我们还创建了其他终端节点来管理数据湖中的各种元数据,例如存储层的名称和数据集分类。
运行 Spark SQL 语句或调用 DataFrame 操作时,Spark 的优化引擎(即 Catalyst)会生成不同的查询计划:逻辑计划、优化的逻辑计划和物理计划,可以使用 EXPLAIN 语句对其进行检查。在作业运行中,Spline 代理解析已分析的逻辑计划,用于构建 JSON 沿袭对象。该对象由以下部分组成:
- 唯一的作业运行 ID
- 引用架构(属性名称和数据类型)
- 操作列表
- 其他系统元数据,例如 Spark 版本和 Spline 代理版本
运行计划指定 Spark 作业执行的步骤,从读取数据源、应用不同的转换到最终将作业的输出保留到存储位置。
总而言之,Spline 代理不仅捕获作业的元数据(例如作业名称以及运行日期和时间)、输入和输出表(例如数据格式、物理位置和架构),还捕获有关业务逻辑的详细信息(作业执行的类 SQL 操作,例如联接、筛选、预测和聚合)。
数据建模和存储
数据建模始于业务需求和使用场景,然后将这些需求映射到用于存储和组织数据的结构中。在数据湖的数据沿袭中,数据资产(作业、表和列)之间的关系与这些资产的元数据同样重要。因此,图数据库适合对这种高度关联的实体进行建模,从而可以高效地理解数据中复杂而深入的关系网络。
Neptune 是一项快速可靠的完全托管式图数据库服务,可帮助您轻松构建和运行具有高度互连数据集的应用程序。您可使用 Neptune 创建复杂的交互式图形应用程序,在几毫秒内查询数十亿个关系。Neptune 支持三种流行的图形查询语言:用于属性图的 Apache TinkerPop Gremlin 和 openCypher,以及用于 W3C 的 RDF 数据模型的 SPARQL。在此解决方案中,我们使用属性图的基元(包括顶点、边、标注和属性)来建模对象,并使用 gremlinpython 库与图形进行交互。
数据模型的目标是为数据资产及其在数据湖中的关系提供抽象概念。在生产者 Lambda 函数中,我们首先解析 JSON 沿袭对象,用于构造作业、表和操作之类的逻辑实体,然后在 Neptune 中构建最终的图表。

下图显示了此解决方案中使用的示例数据模型。

如前所述,通过这种数据模型,我们能够轻松地遍历图形,提取粗粒度和细粒度的数据沿袭。
数据沿袭可视化
您可以使用由 Lambda 函数支持的使用者终端节点,从 Neptune 中提取沿袭图的特定视图。沿袭在不同级别的分层视图使得最终用户可以轻松地分析信息。
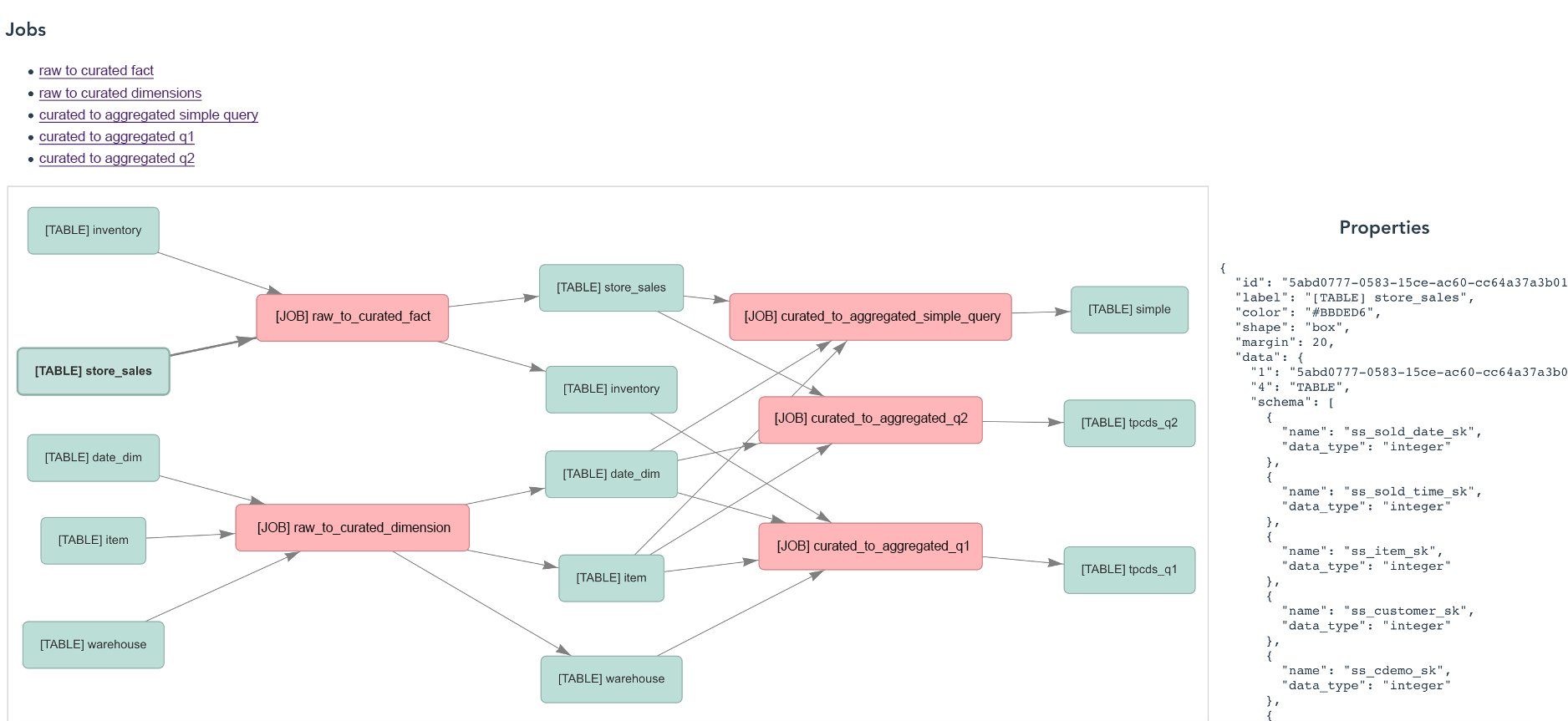
以下屏幕截图显示了所有作业和表的数据沿袭视图。
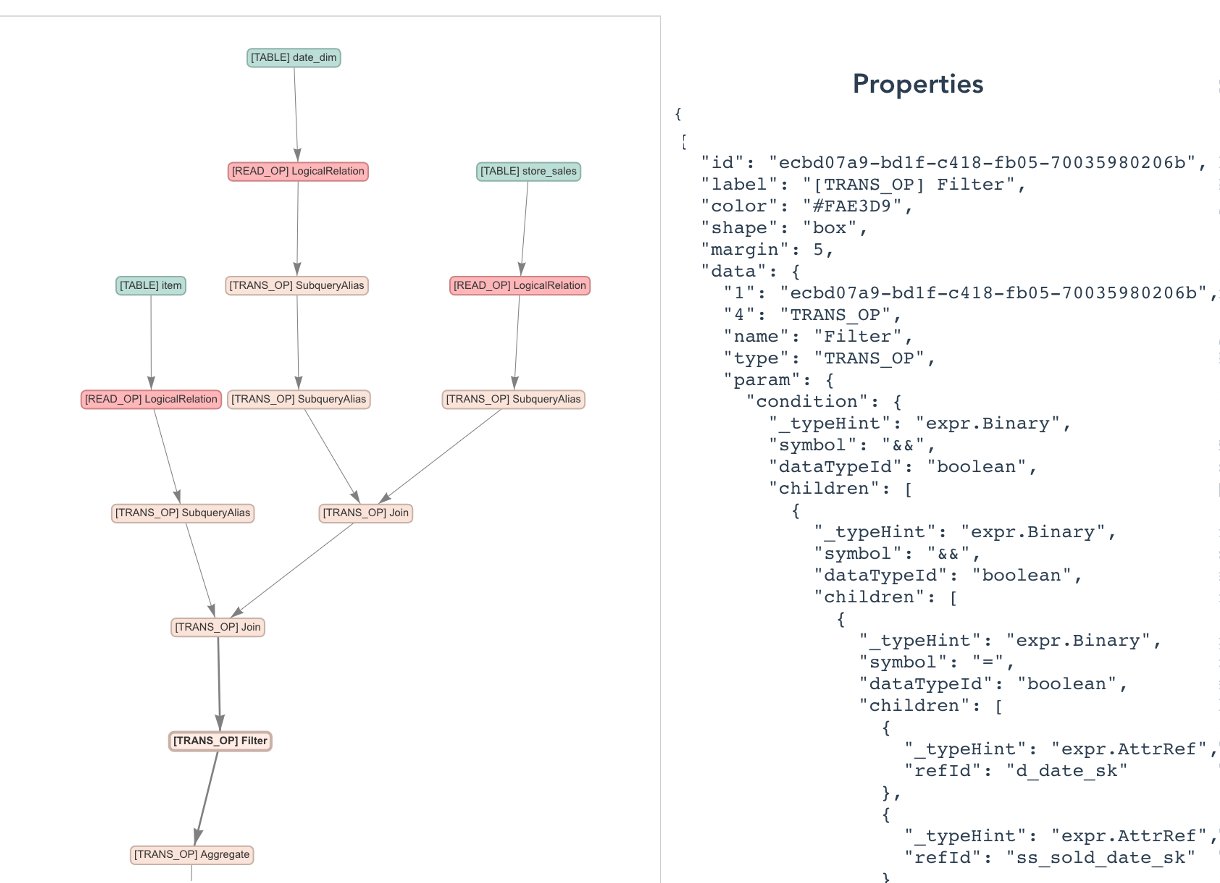
以下屏幕截图显示了特定作业计划的视图。

以下屏幕截图详细显示了作业所执行的操作。
这些图表使用 vis.js 网络开源项目进行可视化。您可以与图形元素交互,以了解有关实体属性的更多信息,例如数据架构。
结论
在这篇文章中,我们向您展示了架构设计选项,利用这些选项可以在多账户 AWS 环境中,使用 Neptune 和 Spline 代理,跨数据湖自动收集 AWS Glue Spark ETL 作业的端到端数据沿袭。这种方法实现了对元数据的搜索,有助于获取洞察并更好地了解整个组织的数据沿袭状况。建议的解决方案使用 AWS 托管和无服务器服务,这些服务具有扩展能力且可配置,可实现高可用性和高性能。
有关此解决方案的更多信息,请参阅 Github。您可以修改代码以扩展数据模型和 API。
本篇作者
相关文章
- 【地铁上的Redis与C#】数据类型(一):为什么常用的数据类型是五种
- 【愚公系列】2023年01月 .NET CORE工具案例-DeveloperSharp的使用(数据库)
- 《数据科学的数学必修课》第1讲 数学基础
- Laravel 迁移文件migrations 和 数据填充seeders
- [koreader]statistics 插件数据库连接
- MySQL5.7 中使用 group by 报错 this is incompatible with sql_mode=only_full_group_by
- 用于年度复盘与计划的数据分析报告怎么写
- 计算机和网络(三) 数据链路层
- 大数据NiFi(三):NiFi关键特性
- 微擎应用:安装、更新、卸载 - 变更数据表
- Laravel 数据库交互 - 查询构造器
- Laravel 数据库交互 - 原生 SQL
- 【地铁上的Redis与C#】数据类型(二)--string 基本操作
- 不停机更换数据库解决方案
- 如何手动通过增强的方式,给 SAP ABAP 数据库表增添新的字段试读版
- 秒杀场景下如何保证数据一致性?就这个问题我给出了最详细的方案
- 坦白局,TCP粘包:我只是犯了每个数据包都会犯的错
- 聊聊业务项目如何主动感知mysql是否存活
- CSRF漏洞中以form形式用POST方法提交json数据的POC
- 代码审计原理与实践分析-SQL篇(一)