
前端开发者也可以懂的基础 System Design
大家好,我是小智,今天带来 Kyle Mo 大佬的一篇关于 System Design 好文,希望对大家有所帮助,早期成为大神。PS:文文已经过授权。
前阵子在与朋友一起筹划的后端开发线上分享会 BESG 有成员分享了 TinyURL 的系统设计 (System Design),刚好也看到了知名 YouTuber Terry 关于 Google 系统设计面试的影片,了解到在美国的资讯业,不论你是前端、后端、资料工程师还是 DevOps,System Design 系统设计几乎都是面试时的必考题。
有人可能会觉得,反正那是国外的状况,我在国内找前端的工作,不需要会系统设计也可以录取吧?是没错,以目前国内的前端业界来看,面试大多是不会考系统设计的,但是其实学习系统设计并不仅是为了应付面试,更是学习如何应付复杂系统的能力,也是从 Junior 开发者过渡到 Senior 开发者的关键。就算身为前端开发者,也会需要面对越来越复杂的系统,学会基本的系统设计思维除了能让你更了解系统的整体架构外,同时也加强在开发时和其他角色沟通与协作的能力。
我是一个刚要进入社会,准备开始自己第一份正职的菜鸟工程师,主要 focus 在 Web 前端技术,但也热衷于学习后端开发与云端技术。我想透过这篇文章,以自己是前端开发者的角度出发,去介绍我认为前端开发者也该拥有的基本系统设计思维,也就是说主要会介绍系统设计最表层的元素,而不会去深入探讨每一个技术的深入实作,目标在广而不在深。
要知道系统设计是一门非常非常非常複杂的技术(说了三次,应该了解到底多複杂了?),绝对不是我这样的菜鸡可以精通的,因此这篇文应该会蛮入门也蛮浅的,主要目的是希望和我一样刚入行的前端开发者在看完文章后,也能拥有最基本的系统设计思维,除了处理 UI 画面与浏览器相关的眉眉角角外,应该也要理解一个合格的系统在背后是怎麽运作的。
本篇文章的流程会是这样的,首先我会把我认为系统设计的重要元素列出来,并对每个元素进行更近一步的介绍,等读者有了大概的认知后,再分享我认为在面对系统设计时可以採用的思维走向,最后再以一个实际的系统设计范例按照先前介绍的思维走向来解决问题。
以分散式系统为设计目标
虽然我们知道分散式相对于单机来说复杂许多,在单机都处理不好的状况下去碰分散式系统几乎是死路一条,不过单机的 Vertical Scaling 是有侷限性的,并且 Single Point Of Failure 的问题也让系统充满风险,要建立一个“可靠的大型系统”,採用分散式架构似乎是无法避免了。况且在遇到系统设计面试问题时,通常都会预设要设计的系统是高流量的,毕竟设计一个只能承受低流量的系统是毫无意义的,因此本篇文章讨论的系统设计都会以分散式系统为出发点。
我们希望设计出来的系统能拥有哪些特性?
Scalability 可扩展性
当系统遇到的流量渐渐变大时,我们会希望系统的服务器或储存空间也能够跟著扩展,来避免无法负荷的状况。
用白话一点的方式来比喻的话,想像今天你跟 4 个朋友约好要出去玩,你们租了 Toyota 的四人座 Vios,不过另外 2 个人看到你们要出去玩,就坚持要你们带上他们,当然现在 6 个人是塞不下小小的 Vios 的,你们只好换租可以载 6 人的 Luxgen U6。
这就很像是系统设计垂直扩展(Vertical Scaling) 的概念,藉由提升单机 CPU 或内存来提升效能。然而这样的提升是有限制的,想像越来越多朋友想跟你们一起出去玩,你说到了 30 个人,你还可以换包游览车,那 300 个呢?(别跟我说包火车)这时可能就得放弃全部人都挤一台车的方式,改为租用多台游览车来载运所有人。这在系统设计上称作水平扩展(Horizontal Scaling),用多台机器来分流处理单机可能无法负荷的流量,达到系统的可扩展性。
Reliability 可靠性
可靠性代表一个系统在它开始执行之后到某个时间点,系统正常执行的机率,也就是系统无故障执行的概率。
Availability 可用性
可用性是一个容易跟可靠性搞混的指标,它的定义为系统在面对各种异常时可以正确提供服务的能力,更严谨的定义为“系统服务不中断运行时间占实际运行时间的比例。””如果以公式来看:
Availability % = (available time / total time) *100
因此可用性跟容错性是相关联的,在单机架构下,机器炸了,使用者也 access 不到服务了,而分散式的状况下即使有机器 shutdown,也会由其他机器马上递补上,对用户来说服务一直是可用的,这也是为什麽说分散式系统可以提升可用性的原因。
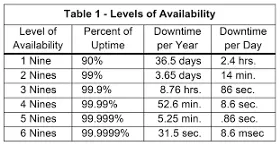
Reliability 与 Availability 这两个指标常常让人搞混,一个 reliable 的系统通常也会是一个 available 的系统,Availability 虽然可以透过分散式系统的冗馀电脑 (redundant) 来达成,但却不能保证这个系统是 reliable 的。
Efficiency 高效率
代表这个系统的效率如何,一般常见的指标有系统的延迟(Latency)与吞吐量(Throughput).
Latency 延迟:执行一个操作要花费的“时间长度”。以我自己较熟悉的 web 领域来说,Latency 指的是使用者发出请求后,等待 server 接收请求,进行处理后回传给使用者的总花费时间。
Throughput 吞吐量:以一个时间区间作为单位,单位时间内可以执行“几次”操作,或运算的“次数”。同样以 web 来举例,Throughput 指的是单位时间内服务器可以接收的请求量。
要建构一个高效率的系统,我们会希望系统可以达到 **Low Latency **与 High Throughput。
Manageability 可管理性
故名思义,代表一个系统是不是方便管理,是不是能快速迭代新功能?是不是能够快速追踪 bug?或是能不能把 infrastructure 抽象化,让应用工程师可以专注在程式逻辑的开发。
System Design Common Components & Topics
无论是面对系统设计的题目或是自己在思考系统的架构,有些技术是建构分散式系统时非常重要的元素,了解这些元素将会使我们对于分散式系统更加了解,在系统设计时也更得心应手,这些常见的元素有:
Load Balancer Web Server Database (SQL vs NoSQL) Schema Design Caching Replication Partitions Sharding Read/Write Splitting Algorithm Queue Consistent Hashing Proxy CAP Theorem
如果要每个技术或概念都介绍的话应该得花不少篇幅,因此这边如果读者对某些概念不熟悉,就麻烦自行研究囉!
面对系统设计时的思维走向
系统设计是一个开放式的问题,没有所谓一定正确且标准的解法,不管哪种方法几乎都会带来 trade off,所以我接下来提供的思维走向也许不是最好最标准的,也不一定适用于所有的情形,但我认为它可以帮助我们快速建构出系统的基本雏形与软硬体需求,如果你对系统设计毫无想法,不妨试试看参考这个思维走向,再根据自己的需求去做细部的调整。
Step.1 弄清系统需求
这是最基本却也是最重要的一步,弄清系统的需求后,你才知道自己到底要设计什麽,如果是在系统设计的面试,这也是应该要尽早跟面试官确定的事。系统需求一般来说可以分为两种类型:
- Functional Requirements
- Non-Functional Requirements
Functional Requirements 代表系统该要有的功能,以 YouTube 系统举例,使用者可以创建自己的频道,也可以去订阅别人的频道,在订阅频道发布新影片时会收到通知…等等你想得到的各种功能,都算在 Functional Requirements 的范畴裡。
Non-Functional Requirements 顾名思义是一些跟系统功能较无直接关连的需求,例如系统需要有高可用性、系统延迟需要非常低、需要严格的资料一致性…等等。
Step.2 关于系统流量、容量、网络带宽等指标的粗略计算
对系统的流量、储存空间、网络做初步的估算,对于后面要考虑 scaling、caching、load balancing 时是有帮助的,再者对这些指标进行评估,也让我们可以更好的掌握系统的资源成本。
同样以设计 YouTube 来举例, 我们可以先估算系统大约会有多少使用者,其中又有多少 DAU (Daily Activated User),估算一天大约会有几部影片上传,影片建立跟读取的比例是多少…等等,这是比较偏向系统流量的考量。
下一步可以估算系统的储存容量,例如每年储存影片的总容量大约是多少?储存的资料会存活多久?如果系统有实作 Caching,Memory 的用量又大概是多少?
而最后网络贷款也是我们可以事先预估的指标。
如果读者不知道怎麽计算这些指标也不要担心,在下一个章节会以设计 Instagram 为范例跑一次系统设计流程,到时候会示范估算这些指标的方式。
Step.3 定义 System Interface
当我们釐清系统的需求后,就可以按照需求来粗略规划系统的 API,这也可以让我们确认先前订出的系统需求并没有定义错误。这时可以先思考系统要採用哪种 API 架构,例如 REST APIs、SOAP、GraphQL,再来可以简单定义出有哪些 API endpoints,以 YouTube 来举例:
uploadVideo(user_id, video_content, video_location, user_location, ……) addVideoToFavorite(user_id, video_id, timestamp, …….)
Step.4 定义 Data Model | DB Schema
在 System Design 的前段及早定义出 DB Schema 将帮助我们更清楚系统的资料流,我们应该清楚不同 Entities 之间是怎麽互动与沟通的,以 YouTube 为例,Data Model 可能是这样子:
User: UserID, Name, Email, DoB, CreationDate, LastLogin, …. Video: VideoID,VideoLink, VideoLocation, NumberOfLikes, TimeStamp, … .….
在这个阶段也可以先思考究竟系统适合哪种资料库?RDBMS 还是 NoSQL ? 还有使用者上传的影片与图片,又适合储存在哪呢?
Step.5 High-level design
这步骤是系统的 High-level 设计,可以在一张图表画出系统大概由哪些 Components 组成,因为先前步骤已经确定了系统需求,也对流量做了初步估算,所以在这个步骤我们可以设计系统需不需要做分流、读写分离,以 YouTube 的例子来说,我们可能还需要一个分散式的档案储存系统来存放影片。
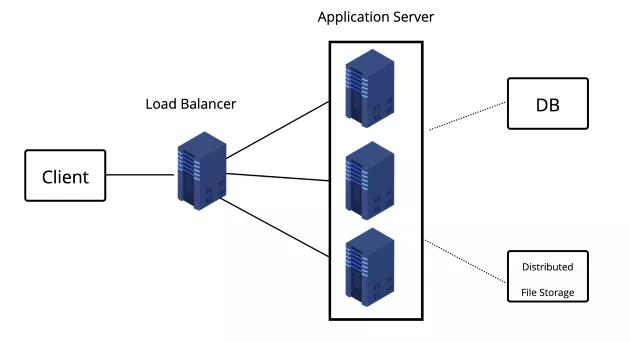
Step.6 System Detailed design
先完成 high-level 的系统设计,接下来才进入系统的 detailed design,如果是面对系统面试,在时间有限的状况下,可以针对前面 high-level design 画出的架构图裡挑出两三个 components 来说明就好,而这边建议可以跟著面试官的引导走。(如果不是在面试,当然你就有大把时间可以好好对每个环节做 detailed 的设计了)
针对特定的 component 或 topic,我们可以提供两三种可行的方法,并思考它们各自的优缺点,这也是个开放性的问题,重要的是你要能清楚每种方式的 trade off,并找出最“适合”自己系统的做法。
- 在需要存取大量资料的情况下,我们该怎麽把资料做 partition 并且存到不同资料库伺服器裡 ?
- 我们应该在系统的哪些 layer 加入快取服务 ?
- 系统中哪些部分比较需要做 load balancing ?
Step.7 找到系统可能瓶颈或 trade off 并尝试给出解决方案
如果是在系统设计的面试中,在做完系统架构设计之后,可以针对自己设计的系统提出一些可能的瓶颈,毕竟没有所谓完美的系统架构,能够讲出自己所设计的系统有哪些缺陷或瓶颈,代表你对系统整体的掌握度是高的,也许在面试官的眼中是加分的行为(不过这边可能得注意挖坑给自己跳的状况)。
尝试设计一个 Instagram 吧!
虽然知道了面对系统设计可以採取的思路,但我相信各位读者看到这裡还是觉得十分抽象吧?那不如我们就按照前面的思考步骤实际设计一个 IG 系统体会看看吧!(下面代称这个系统为“Fake IG”好了?)
(大家应该都知道 IG 是什麽吧!??)
Step.1 理清系统需求
前面有提到可以针对“Functional Requirements”与 “Non-Functional Requirements”来区分系统需求
Functional Requirements:
- 使用者可以上传照片、影片,另外也可以读取与下载
- 使用者可以追踪其他使用者以观看最新贴文
- 使用者可以根据 tags 来搜寻文章
- 当使用者刷新页面后,系统会根据使用者追踪的人显示该些用户的最新贴文
Non-Functional Requirements:
- Fake IG 系统需要具有高可用性(high availability)
- 刷新页面看最新贴文时可以允许短暂的延迟
- 在某些状况下,系统的一致性可以牺牲,例如使用者贴文的爱心数量(每个使用者看到的数量即使不一样,也不会造成什麽影响)
- 系统希望可以拥有高可靠性(high reliability),使用者上传的照片、影片不能够遗失
我们都知道实际上 IG 的功能绝对比上面列出来的还要多,例如在照片上标记其他使用者、限时动态…等等,这些较进阶的功能可以自己思考要不要列出。(设计出基本功能比较重要)
Step.2 关于系统流量、容量、网络带宽等指标的粗略计算
关于系统的流量,我们可以先假设高一点,毕竟设计能面对高流量的系统才有意思。假设我们的 Fake IG 系统的使用者总人数有 5000 万人,当然裡面不乏许多早就没在使用的幽灵用户,所以这边假设每天仍然活跃的用户(daily active users, DAU)有 100 万人。
接下来我们先忽略使用者可以上传影片这个行为,先限定使用者只能够上传照片,不然要考虑的因素实在太多了。假设一天大约有 150 万张照片会被上传,平均一张照片的档案大小为 250 KB,那麽储存一天中新上传的照片总共需要的容量为
1.5M * 250KB ~= 375GB
如果将时间拉远来看,10 年下来存放照片需要的容量为
375GB * 365(days) * 10 ~= 1368.75TB
当你在后面的步骤定义好 DB Schema 后,也可以再回过头来用同样的方式估算资料库要储存的资料总大小,例如我们的系统一定会有储存用户资讯的 User Table ,而它的栏位与空间如下
UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + Birthday (4 bytes) + CreationDate (4 bytes) = 64 bytes
先前有假设 Fake IG 的使用者总人数有 5000 万人,因此储存用户资讯的 total storage 约为:
50M 64 ~=3.2GB*
其他的 DB Schema 与上传图片使用的 Network Bandwidth 也可以採用类似的方法估算需要的容量。
Step.3 定义 System Interface
规划系统 API 的步骤,因为是一个十分开放式的问题,答案也不太会影响接下来的步骤因此这边就不多花篇幅说明。
Step.4 定义 Data Model | DB Schema
定义出 Data Model 可以让我们清楚数据的关联与数据的流动,在未来要做 data sharding 或 partitioning 时也会比较容易。在 Fake IG 系统中,我们先假设只需要先考虑使用者与用户上传的照片就好(不然我这边会写不完,还请高抬贵手),在学生时期十分认真修资料库课程的你可能会马上画出以下的数据库关联图
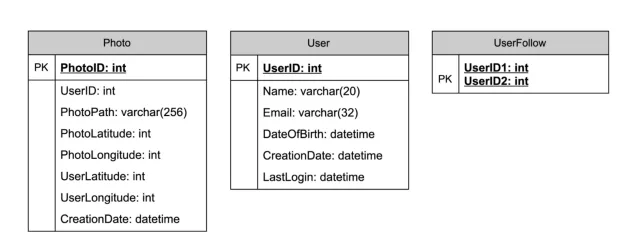
画完图后你可能会觉得这个 use case 还蛮适合使用如 MySQL 的 RDBMS 的,毕竟数据是有 join 的需求的。不过 RDBMS 在 Scaling 上是非常非常複杂且困难的,例如数据一致性的处理方式也与单机时大不相同。而使用 NoSQL 其实也是可行的,虽然可能需要一些额外的 table 来储存数据的关联 (例如 UserPhoto),不过在 Scaling 上却较为简单。我也没办法告诉你,使用 RDBMS 还是 NoSQL 好,它们各有各的优缺点也有各自适用的时机,因此这个问题也算是开放式的,应该在多深入了解后再做出选择。
另外像照片影片这种资源,一般会需要像是 AWS S3 这样的 Distributed File Storage,而在我们的数据库中则只存图片或影片在 file storage 的 link 还有其他的 meatdata。
Step.5 High-level design
当然我们也不一定要画出整个系统的架构图,尤其是在面试的话,我们得在有限的时间内尽量 focus 在系统的重点部分,以 Fake IG 来说我们先试着设计使用者上传照片与读取照片的功能。
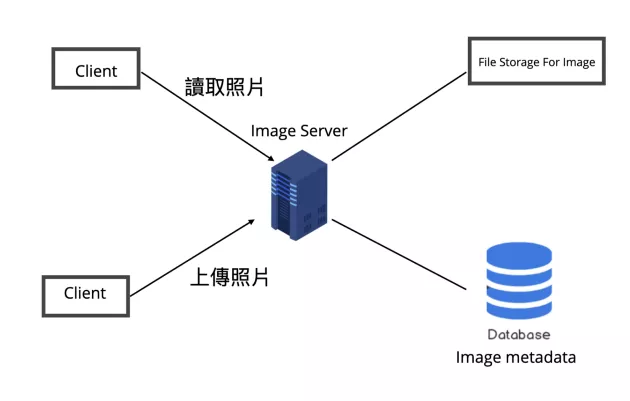
以 high-level 的角度来看 Fake IG 的照片系统,大致上会有两种情境,也就是用户上传照片与读取照片,所以我们会需要一台 application server 来处理使用者的读写 requests,另外会需要一个如 AWS S3 一样的分散式 file Storage 来储存照片,另外也会再开一个 database 来储存照片相关的 metadata。
Step.6 System Detailed design
不过仔细思考就会知道上传照片相比读取照片所耗费的时间会多出更多,因为上传照片可能涉及了硬盘的写入,也不像读取一样可以加一层快照层。通常 web server 是有连线数量的限制的,如果上传照片的过程太耗时,可能会占用 web server 的连线请求,导致要读取照片的 request 被卡住,造成响应的延迟。要处理这个 bottleneck 的其中一种方式就是将读取与上传拆成两个独立的 server 来分别处理请求,而负责上传照片的 server 还能搭配 message queue 来消化请求。这样的做法还有一个好处就是两个服务可以依照需求各自 Scale 与 Opimize。
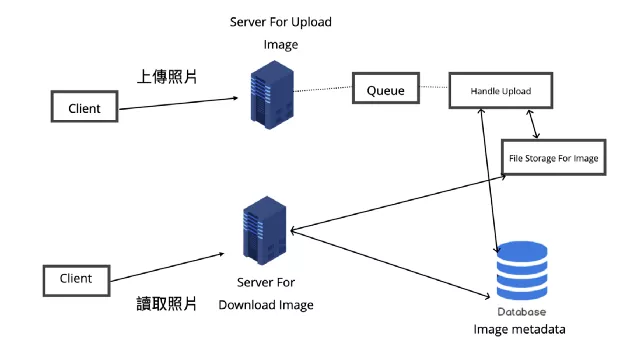
对于 Availability 与 Reliability,也可以考虑为系统的各个 component 加入 replica service,这样 horizontal scaling 的结果是可以避免 single point of failure,在其中一个服务节点挂掉时仍能保持系统可用性,搭配 Load Balancer 也可以做到流量的分流,降低系统的延迟。
提到 Load Balancer,它的目的是达成 horizontal scaling,不过它也可能会有 single point of failure 的风险,因此 replica 也可以应用在它上面。就算是只需要一个 instance 来运作的服务,也可以为其建立 redundant secondary copy,这个 copy 不会 serve 任何的流量,却可以当作备胎,在主服务挂掉时立即取代它的工作成为 master node。
同样的 Scaling 思维也适用于储存服务例如 Fake IG 使用的 File Storage 与 Database,毕竟我们不希望系统出现档案或资料遗失的状况,因此可以为 Database 与 File Storage 加 backup server,让数据也可以避免单点失效后遗失的问题。
不过还是得呼吁一下,加 replica services 未必能改善所有性能或其他的瓶颈,再来成本也是需要考量的一个元素,因此还是得依照需求谨慎评估是否需要 scaling,需要的话也要谨慎评估 scaling 的程度。
更进一步可以思考 database 数据是不是需要 Partitioning 或 Sharding,前者是在同一个数据库中将 table 拆成数个小 table,后者则是将 table 放到数个数据库中。
Partitioning 的 table 与 schema 可能会改变,Sharding 的 schema 则是相同,但分散在不同数据库中,Partitioning 是为了分散单表的压力,Sharding 则是分散单库的压力,实际上还是要依照需求找出适合当前系统的方式。
以 Fake IG 来说,如果真要选择我可能会选择比较容易扩展的 Sharding,不过 Sharding 也带来相当多的问题例如横跨不同 shards 的 transaction、rollback、schema change、join、每个 shard db 还要另外去做 backup……等等。
如果选择了 Sharding 的方式,那麽 Shard 时依赖的 key 就很重要了,一般来说可以分为 Range-based 与 Hash 两种方式(如果完全不知道 Sharding 的读者可以参考我之前的笔记文章),假设我们以 userId 来作为 shard 的 key,那可能会出现 hot user 造成某一个数据库 loading 过重的问题(想想那些在 IG 上追踪人数破亿的全球巨星,一天不知道会有多少使用者去浏览他们的文章呢,那麽存取这些明星数据的数据库可能流量就会比其他 instance 还要大很多)。
总之我觉得 Sharding 的複杂度还有坑真的是挺多的,也许在一开始得先考虑清楚系统是不是真的需要 Sharding,如果在面试提出要做 Sharding 或 Partitioning,也要做好万全准备,以免只是挖更多坑给自己跳。
当然 Caching 也是一个必定要考虑的机制,因为 Fake IG 会产生许多图片,而这些资源非常适合暂存在离 end users 更接近的 CDN 裡。除了 CDN Cache,也可以在数据库前加一个例如 Memcache 的快照服务器,用来暂存一些较常被抓取的资料。
关于到底要存哪些数据到快照这个问题,我们不可能把所数据都放到快照裡,根据“80–20 Rule”,80% 的流量可能都来自于 20% 的 hot data,因此我们可以找出较常被 user 存取的 20% photo 与 metadata 数据存到缓存中。
而快照是需要一些清除策略(cache eviction policy)的,不然无限增长的状况下很容易就没有快照空间了。在 Fake IG 系统中,我觉得 LRU Cache (Least Recently Used Cache)就还蛮适合的,当要清除快取空间时,可以先从近期最少被存取的数据开始移除。
总结
虽然说身为前端开发者,在求职过程甚至是整个职涯都有可能不会碰到系统设计相关的问题,不过因为我将自己定义为杂食性的软体工程师,遇到有兴趣、有挑战性的技术我都想学,再加上自己一直有个不切实际的硅谷梦,所以依然深信自己未来某一天也会遇到系统设计的挑战。而自己也的确在接触这些内容后对整个系统应用架构有了更进一步的了解,所以我非常推荐前端开发者也可以尝试了解最基础的系统设计。
作者:HannahLin 来源:medium
原文:https://medium.com/starbugs/%E5%89%8D%E7%AB%AF%E9%96%8B%E7%99%BC%E8%80%85%E4%B9%9F%E5%8F%AF%E4%BB%A5%E6%87%82%E7%9A%84%E5%9F%BA%E7%A4%8E-system-design-5468e0f43033

相关文章
- Jgit的使用笔记
- 利用Github Action实现Tornadofx/JavaFx打包
- 叹息!GitHub Trending 即将成为历史!
- 微软软了?开源社区讨论炸锅,GitHub CEO 亲自来答
- GitHub Trending 列表频现重复项,前后端都没去重?
- Photoshop Elements 2021版本软件安装教程(mac+windows全版本都有)
- (ps全版本)Photoshop 2020的安装与破解教程(mac+windows全版本都有)
- (ps全版本)Photoshop cc2018的安装与破解教程(mac+windows全版本,包括2023
- 环境搭建:Oracle GoldenGate 大数据迁移到 Redshift/Flat file/Flume/Kafka测试流程
- 每个开发人员都要掌握的:最小 Linux 基础课
- 来撸羊毛了!Windows 环境下 Hexo 博客搭建,并部署到 GitHub Pages
- 超实用!手把手入门 MongoDB:这些坑点请一定远离
- 【GitHub日报】22-10-09 zustand、neovim、webtorrent、express 等4款App今日上新
- 【GitHub日报】22-10-10 brew、minio、vite、seaweedfs、dbeaver 等8款App今日上新
- 【GitHub日报】22-10-11 cobra、grafana、vue、ToolJet、redwood 等13款App今日上新
- Photoshop 2018 下载及安装教程(mac+windows全版本都有,包括最新的2023)
- Photoshop 2017 下载及安装教程(mac+windows全版本都有,包括最新的2023)
- Photoshop 2020 下载及安装教程(mac+windows全版本都有,包括最新的2023)
- Photoshop 2023 资源免费下载(mac+windows全版本都有,包括最新的2023)
- 最新版本Photoshop CC2018软件安装教程(mac+windows全版本都有,包括2023