
服务出现明显的变慢,该如何诊断处理?
2023-02-25 18:05:16 时间
在日常工作中,应用出现性能问题是不可避免的,绝大部分公司都没有专门的性能团队,出现问题还是需要我们自己去排查处理,所以掌握基本的性能知识和技能就显得很有必要,也是开发工程师进阶的必要条件,能否快准狠的定位解决问题,也是对知识、技能和能力的检验。
今天我们来讨论的问题是,服务出现明显的变慢,该如何诊断处理?
首先我们要确定服务是突然变慢还运行一段时间后观察到变慢?类似的变慢是经常出现还是偶发的?还有对慢的定义是什么?是否可以理解为系统对其他方面的请求的延时变长?
在理清楚问题的症状后,更有利于分析问题的具体原因,大概有以下思路:
- 检查应用本身的错误日志,看是否在系统变慢的时候存在大量错误日志,来判断是否出现意外的程序错误。对于分布式系统,很多公司都会有日志、性能监控系统,使用一些Java诊断工具也可以用于诊断,监控应用是否大量出现某种类型的异常。
- 监控Java服务本身,查看GC日志里面是否观察到频繁的Full GC等,可以利用jstat等工具获取内存使用的统计信息,利用jstack等工具检查是否出现死锁等。
- 如果还不能定位问题,可以使用性能检测工具Profiling,因为它对系统是有侵入性的,非必要,不建议在生产系统进行。
- 定位到问题,采取相应的补救措施,然后验证是否解决,如果没有解决,重复上面的操作。
接下来我们来了解一下业内广泛的性能分析方法论。方法论总结为两类:
- 自上而下。从应用顶层,逐步深入到具体的不同模块,或者更近一步的技术细节单元,找到可能的问题和解决方法,这也是最常见的性能分析方法,也是大部分人的选择。
- 自下而上。从类似CPU的这种硬件底层,判断类似Cache-Miss之类的问题和调优机会,出发点是指令级别优化。这往往门槛比较高,需要掌握专业的技能,还得专业的工具配合,一般出现在新平台移植或者追求极致性能的时候才会进行。
我们重点看第一种,自上而下。各个阶段的思路以及使用的工具等。
分析系统的性能,我们常从CPU、内存和IO等入手,这几点是重点关注项。对于CPU,如果是Linux环境,可以先用top命令查看负载情况:
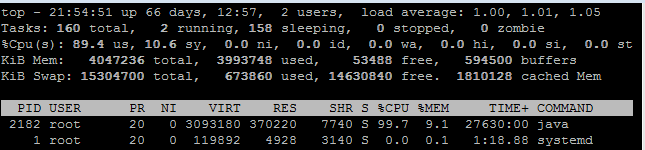
可以看到,平均负载的三个值并不高,也没有升高的迹象,可以先不特别关注,接下来分析最耗费CPU的Java线程,步骤如下:
利用top命令获取相应的pid,-H代表thread模式,也可以配合grep命令更精确定位。
top -H然后转换成16进制。
printf "%x" your_pid最后利用jstack获取的线程栈,对比相应的ID即可。也可以用vmstat,查看上下文切换的数量,比如指定时间间隔为1,收集20次
vmstat -1 -20
如果上下文切换非常高,并且系统中高很多,就表明可能存在不合理的线程调度导致的,可以用pidstat进一步分析定位。
除了CPU,内存和IO也有很多注意事项:
- 利用free之类查看内存的使用情况。
- 进一步判断 swap 使用情况,top命令输出中Virt作为虚拟内存使用量,就是物理内存(Res)和 swap 求和,所以可以反推 swap 使用。显然,JVM 是不希望发生大量的 swap 使用的。
- 对于 IO 问题,既可能发生在磁盘IO,也可能是网络IO。例如,利用iostat等命令有助于判断磁盘的健康状况。
相关文章
- 详解在 Ubuntu 从外部存储库安装软件包
- 谷歌结构化-调研与实践
- 跟着小白一起学鸿蒙—简析OpenHarmony软总线能力
- 优秀 Linux 远程桌面客户端
- 如何在 Silverblue 上变基到 Fedora Linux 37
- 使用 WinSCP 将文件和文件夹从 Windows 传输到 Linux
- 系统管理员喜欢 Systemd 的五个理由
- 如何在 Arch Linux 中安装 elementary OS 的 Pantheon 桌面
- Halodoc的数据平台转型之Lakehouse架构
- 为什么说数据治理的下一站是DataOps?
- 五个 htop 替代:增强你的 Linux 系统监控体验
- Bash 初学者系列 1:创建并运行第一个 bash shell 脚本
- 聊聊操作系统的内存管理
- 大数据安全面临的挑战与解决方案
- 导致域控制器卡死 / 重启,微软承认 11 月更新导致 Windows Server 出现 LSASS 内存泄露
- 用Bpftrace去透视Linux内核
- 新来个技术总监,把 RabbitMQ 讲的那叫一个透彻,佩服!
- 为何大厂选择减人而不是降薪?
- 跟着小白一起学鸿蒙—编写一个蓝牙性能Stage HAP
- 照猫画虎把SpringBoot搬到K8s,居然翻船咧,体验到了Go在云原生的两个优势