
java并发文字总结
1.进程是包含线程的,每个进程内部的线程之间是贡献堆和方法资源区的,但是每个线程的程序计数器,虚拟机栈和本地方法栈是不同的.所以在各个线程之间切换的代价是比较小的.
2.java程序天生就是多线程程序.一个 Java 程序的运行是 main 线程和多个其他线程同时运行
3.请简要描述线程与进程的关系,区别及优缺点?
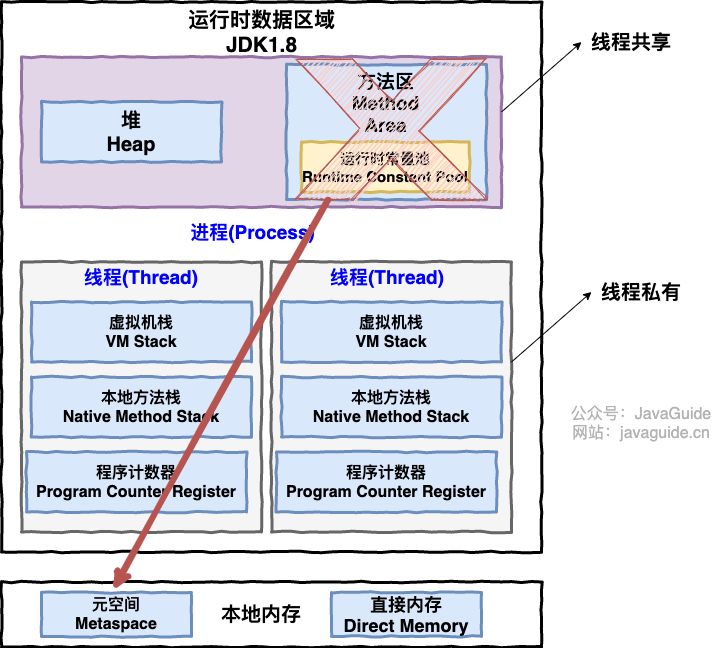
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
总结: 线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
3.1程序计数器为什么是私有的?
程序计数器主要有下面两个作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
所以,程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。
3.2 虚拟机栈和本地方法栈为什么是私有的?
- 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
- 本地方法栈: 和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
为了保证局部变量不被其他线程访问,所以虚拟机栈和本地方法是线程私有的
3.3 简单区别堆和方法区:
堆:是最大的一块内存,主要存放的是所有线程的共享资源和新创建的对象
方法区: 主要用于存放已被加载的类信息,常量,静态变量.
4.为什么要使用多线程
- 从计算机底层来说: 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
- 从当代互联网发展趋势来说: 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
再深入到计算机底层来探讨:
- 单核时代: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
- 多核时代: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
5.说说线程的生命周期和状态?
1.初始状态,线程被创建出来但是没有被start()
2.运行状态: 线程被调用了start()等待运行的状态
3.阻塞状态: 当线程进入 synchronized 方法/块或者调用 wait 后(被 notify)重新进入 synchronized 方法/块,但是锁被其它线程占有,这个时候线程就会进入 BLOCKED(阻塞) 状态。
4.等待状态:表示该线程需要等待其他线程作出一些特定动作.(主动的,在同步代码之内)进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态。
5.超时等待状态: 可以在指定的时间后自己返回而不是一直傻傻等待,像第4步,当超时时间结束后,线程将会返回到 RUNNABLE 状态。
6.终止状态; 表示该线程已经运行完毕

6.上下文切换
在线程执行的过程中,会有自己的状态和运行条件,比如程序计数器,栈等信息,当出现如下的情况的时候,线程会从CPU占用的状态退出
- 主动让出CPU,比如调用了sleep,wait
- 时间片用完了,操作系会在时间片结束的时候主动结束线程
- 调用了阻塞类型的系统中断,比如io
- 被终止或者结束运行
前三种会发生线程切换,所以会保存当前线程的上下文,留待线程下次占用CPU得时候恢复现场.
7 什么是线程死锁?如何避免死锁?
1什么是线程死锁
线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
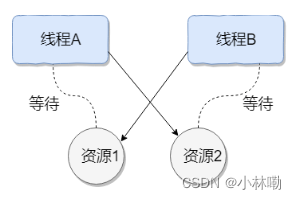
上面的例子符合产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
2.避免死锁
1.破坏请求与保持条件,一次性申请所有资源
2.破坏不不剥夺条件: 占用部分资源的线程进一步申请其他资源时,则释放自己的资源
3.破坏循环等待条件: 依靠按序申请资源来预防.按照某一顺序来申请资源,释放资源的顺序与之相反.
8.sleep() 方法和 wait() 方法对比
sleep()方法没有释放锁,而wait()方法释放了锁 。wait()通常被用于线程间交互/通信,sleep()通常被用于暂停执行。wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法。sleep()方法执行完成后,线程会自动苏醒,或者也可以使用wait(long timeout)超时后线程会自动苏醒。sleep()是Thread类的静态本地方法,wait()则是Object类的本地方法。为什么这样设计呢?
9.为什么 wait() 方法不定义在 Thread 中?
wait() 是让获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁。每个对象(Object)都拥有对象锁,既然要释放当前线程占有的对象锁并让其进入 WAITING 状态,自然是要操作对应的对象(Object)而非当前的线程(Thread)。
类似的问题:为什么 sleep() 方法定义在 Thread 中?
因为 sleep() 是让当前线程暂停执行,不涉及到对象类,也不需要获得对象锁
10.可以直接调用 Thread 类的 run 方法吗
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start() 方法方可启动线程并使线程进入就绪状态,直接执行 run() 方法的话不会以多线程的方式执行。
11.volatile 关键字
保证变量的可见性,如果变量被声明为volatile那么就告诉jvm这个变量共享,且不稳定,每次使用都要到主存中去读取.volatile只能保证数据的可见性,并不能保证原子性,但是synchronized关键字二者都可以保证.同时volatile关键字还能禁止指令重排序,具体做法是添加内存屏障.
12 乐观锁和悲观锁
悲观锁: 总是假设最坏的情况会发生,所以共享资源只给一个线程使用,其他线程被阻塞,用完后在把资源转让给其他线程.,比如synchronized和ReentrantLock等独占锁.
乐观锁:总是假设最好的情况,认为资源每次被访问的时候是不会出现问题的,所以线程是不必加锁的,可以无需等待,不停的执行,只是在提交修改的时候去验证对应的资源是否被其他的线程修改了.(CAS或者是版本号)
悲观锁:多用于写比较多的情况,避免频繁的写失败和重试影响性能
乐观锁:通常用于写比较少的情况,避免频繁加锁影响性能,大大提升了系统的吞吐量.
12.2 CAS: 比较与交换算法:
用一个预期值和要更新的值比较,如果相等,则更新.
CAS是一个原子操作,底层是依赖于一条CPU原子指令.涉及到三个操作数:
V:要更新的变量值(var) E:预期值(expect) N:拟写入的值(new)
当且仅当V值== E值时间,CAS才会更新值,假设不存在ABA问题
举一个简单的例子 :线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
- i 与 1 进行比较,如果相等, 则说明没被其他线程修改,可以被设置为 6 。
- i 与 1 进行比较,如果不相等,则说明被其他线程修改,当前线程放弃更新,CAS 操作失败。
多个线程同时使用一个,只会有一个执行成功,但是其他的失败线程不会被挂起,而是仅告知失败,并且允许再次尝试.
12.3 乐观锁的问题
ABA问题:
如果一个变量V在初次读取的时候获得的值是1,并且在他准备复制的时候检查到的值仍然是1,那么可以说V没被其他线程修改过么,当然是不能的,因为整个的操作是不具备锁的,所以一旦在初次读取到二次确认的中间有其他线程来进行了数值的修改,而后又改为1,那么CAS操作就会误认为V从来没被修改过.
解决: 加版本号或者时间戳 eg:首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
循环时间长,开销大:
CAS经常用到自旋操作进行重试,就是不成功就一直尝试,知道成功的方式,但是如果长时间不成功,就会给CPU带来巨大的执行开销.
只能保证一个共享变量的原子操作
CAS只对单个共享变量有效(可以看做一种特殊的复制的操作/在操作系统中就是这么规定的),当涉及到操纵多个跨共享变量时,CAS无效,但是从JDK1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作,所以我们可以用锁或者AtomincReference把多个共享变量合并成一个共享变量来操作.
相关文章
- Java开发操作系统内核:实现进程的优先级切换
- 谈谈Java调用SQL Server分页存储过程
- 挨踢部落故事汇(23):一路前行,兴趣所至
- 如何用Java操作MongoDB
- 挨踢部落故事汇(13):扬长避短入行Oracle开发
- 高并发挑战带来的思考 看阿里如何带业务方玩转交易平台
- Oracle修补Java中存在十年的bug
- 体验纯Java数据库——Derby
- 分析Sun没落原因:高层重硬件轻软件
- 如何建立JSP操作用以提高数据库访问效率
- Java访问ACCESS数据库的方法
- java数据库设计中的14个技巧
- Java技巧:Java连接数据库技巧全攻略
- Oracle收购Sun周年纪实:毁灭还是挽救?
- 盘点2010年Oracle大事记 MySQL 5.5发布居首
- 常用的Java开发工具比较
- HarmonyOS编程跨设备跳转 | Java注释版
- 从理论到实践,基于Java的开源大数据工具
- Google开源C/C++版MapReduce框架
- 运维中常见关键指标参数