
基于深度信念神经网络DBN的回归分析
目录
背影
DBN神经网络的原理
DBN神经网络的定义
受限玻尔兹曼机(RBM)
dbn神经神经网络的回归分析
基本结构
主要参数
MATALB代码
结果图
展望
背影
回归分析是常见的数学问题,很多回归分析因为太复杂,不容易用公式表达,本文用DBN进行黑箱回归分析,实现回归分析的准确预测
DBN神经网络的原理
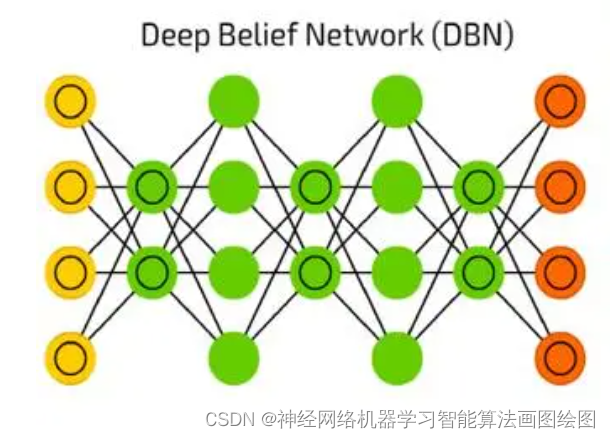
深度信念神经网络DBN的定义
深度信念网络,DBN,Deep Belief Nets,神经网络的一种。既可以用于非监督学习,类似于一个自编码机;也可以用于监督学习,作为分类器来使用。
从非监督学习来讲,其目的是尽可能地保留原始特征的特点,同时降低特征的维度。从监督学习来讲,其目的在于使得分类错误率尽可能地小。而不论是监督学习还是非监督学习,DBN的本质都是Feature Learning的过程,即如何得到更好的特征表达。
作为神经网络,神经元自然是其必不可少的组成部分。DBN由若干层神经元构成,组成元件是受限玻尔兹曼机(RBM)。
受限玻尔兹曼机(RBM)
RBM是一种神经感知器,由一个显层和一个隐层构成,显层与隐层的神经元之间为双向全连接,在RBM中,任意两个相连的神经元之间有一个权值w表示其连接强度,每个神经元自身有一个偏置系数b(对显层神经元)和c(对隐层神经元)来表示其自身权重。
这样,就可以用下面函数表示一个RBM的能量:

在一个RBM中,隐层神经元 被激活的概率:
p(v/h) = sum(p(vi/h))
由于是双向连接,显层神经元同样能被隐层神经元激活:

其中, 为 Sigmoid 函数,也可以设定为其他函数。
值得注意的是,当 为线性函数时,DBN和PCA(主成分分析)是等价的。
同一层神经元之间具有独立性,所以概率密度亦然满足独立性,故得到下式:
基于dbn的回归分析
基本模型
创建经典的四层的DBN神经网络
神经网络参数
maxepoch=1000;%训练rbm的次数
numhid=130; numpen=200; numpen2=10;%dbn隐含层的节点数
disp(‘构建一个3层的深度置信网络DBN用于特征提取’);
数据

MATLAB编程代码
tic;%计时开始
clear all
close all
clc
format compact
%% 加载数据
% num1 = xlsread(‘a.xlsx’,1,‘A4:C68’);
% num2 = xlsread(‘a.xlsx’,1,‘D4:F21’);
% num3 = [num1(:,1:2);num2(:,1:2)];
% num4 = [num1(:,3);num2(:,3)];
num = xlsread(‘数据2.xls’);
num2 = [];
for ii = 14500:15000
num2 = [num2;num(ii:ii+191,3)‘];
end
num3 = num2(:,1:96);
num4 = num2(:,97:192);
%% 归一化
[input,inputps]=mapminmax(num3’,0,1);
[output,outputns]=mapminmax(num4’,0,1);
input=input’;
output=output’;
%% 划分数据集
% n = randperm(81);
n =1:200;
P=input((1:end-1)😅; %训练输入
T=output((1:end-1)😅;
P_test=input(end,:);%测试输入
T_test=output(end,:);
clear data m n input output
%% 训练样本构造,分块,批量
numcases=5;%每块数据集的样本个数
numdims=size(P,2);%单个样本的大小
numbatches=9;%将1000组训练样本,分成250批,每一批5组
% 训练数据
for i=1:numbatches
train=P((i-1)numcases+1:inumcases,:);
batchdata(:,:,i)=train;
end%将分好的10组数据都放在batchdata中
%% 2.训练RBM
%% rbm参数
maxepoch=1000;%训练rbm的次数
numhid=130; numpen=200; numpen2=10;%dbn隐含层的节点数
disp(‘构建一个3层的深度置信网络DBN用于特征提取’);
%% 无监督预训练
fprintf(1,'Pretraining Layer 1 with RBM: %d-%d ',numdims,numhid);
restart=1;
rbm1;%使用cd-k训练rbm,注意此rbm的可视层不是二值的,而隐含层是二值的
vishid1=vishid;hidrecbiases=hidbiases;
fprintf(1,'
Pretraining Layer 2 with RBM: %d-%d ',numhid,numpen);
batchdata=batchposhidprobs;%将第一个RBM的隐含层的输出作为第二个RBM 的输入
numhid=numpen;%将numpen的值赋给numhid,作为第二个rbm隐含层的节点数
restart=1;
rbm1;
hidpen=vishid; penrecbiases=hidbiases; hidgenbiases=visbiases;
fprintf(1,'
Pretraining Layer 3 with RBM: %d-%d
',numpen,numpen2);%200-100
batchdata=batchposhidprobs;%显然,将第二哥RBM的输出作为第三个RBM的输入
numhid=numpen2;%第三个隐含层的节点数
restart=1;
rbm1;
hidpen2=vishid; penrecbiases2=hidbiases; hidgenbiases2=visbiases;
%%%% 将预训练好的RBM用于初始化DBN权重%%%%%%%%%
w1=[vishid1; hidrecbiases]; %
w2=[hidpen; penrecbiases]; %
w3=[hidpen2; penrecbiases2];%
%% 有监督回归层训练
%=训练过程===========%
%DBN无监督用于提取特征,需要加上有监督的回归层========%
%由于含有偏执,所以实际数据应该包含一列全为1的数,即w0x0+w1x1+…+wnxn 其中x0为1的向量 w0为偏置b
N1 = size(P,1);
digitdata = [P ones(N1,1)];
w1probs = 1./(1 + exp(-digitdataw1));
w1probs = [w1probs ones(N1,1)];
w2probs = 1./(1 + exp(-w1probsw2));
w2probs = [w2probs ones(N1,1)];
w3probs = 1./(1 + exp(-w2probs*w1));
H = w3probs’;
nn=size(T,2);
T=T’;
lamda=inf;%正则化系数
OutputWeight=pinv(H’+1/lamda) *T’;%加入正则化系数lamda,lamda=inf就是没有正则化
Y=(H’ * OutputWeight)';
%%%%%%%%%% 计算训练误差,不重要,看看图就行
% 反归一化
T=(mapminmax(‘reverse’,T,outputns));
Y=(mapminmax(‘reverse’,Y,outputns));
figure
plot(T’,‘-*’)
hold on
plot(Y’,‘o-’)
legend(‘期望输出’,‘实际输出’)
firstline = ‘训练阶段’;
secondline = ‘实际输出与理想输出的结果对照’;
title({firstline;secondline},‘Fontsize’,12);
xlabel(‘训练样本数’)
%=测试过程===========%
%=======================================================================%
N2 = size(P_test,1);
w1=[vishid1; hidrecbiases];
w2=[hidpen; penrecbiases];
w3=[hidpen2; penrecbiases2];
test = [P_test ones(N2,1)];
%激活函数是常用的sigmoid时,也可以换成其他函数,甚至每层的都可以不一样
w1probs = 1./(1 + exp(-testw1));
w1probs = [w1probs ones(N2,1)];
w2probs = 1./(1 + exp(-w1probsw2));
w2probs = [w2probs ones(N2,1)];
w3probs = 1./(1 + exp(-w2probs*w3));
H1 = w3probs’;
TY=(H1’ * OutputWeight)‘; % TY: the actual output of the testing data
% 反归一化
T_test=(mapminmax(‘reverse’,T_test’,outputns));
TY=(mapminmax(‘reverse’,TY,outputns));
%%%%%%%%%% 计算测试结果
result=[TY;T_test];
error=TY-T_test;
fprintf(‘测试集输出结果分析
’);
fprintf(‘均方误差MSE
’);
MSE=mse(error)
fprintf(‘平均绝对误差MAE
’);
% MAE=mean(abs(TY-mean(T_test)))
% fprintf(‘平均相对误差MRE
’);
% MRE=mean(abs(TY-mean(T_test))./T_test); %不能计算平均相对误差,因为相对误差=绝对误差/真实值,而你真实值里面有0
% fprintf(‘不能计算平均相对误差,因为相对误差=绝对误差/真实值,而你真实值里面有0
’);
fprintf(‘相关系数
’);
a=corrcoef(TY,T_test);%皮尔逊相关系数
corrcoeff=a(1,2)
t=toc %计时结束
figure
plot(T_test,‘r-*’)
hold on
plot(TY,‘bo-’)
firstline = ‘DBN深度信念网络测试阶段’;
secondline = ‘实际输出与理想输出的结果对照’;
title({firstline;secondline},‘Fontsize’,12);
xlabel(‘样本’)
ylabel(‘’)
legend(‘期望输出’,‘验证输出’)
效果图

结果分析
从效果图上看,深度信念网络DBN回归分析效果很多,预测比较均衡平滑
展望
DBN是一种深度信念网络,优点在可以处理大输入数据,能训练中自动降维,训练的过程就是降维的过程,缺点是拟合逼近能力不强,收敛面比较平滑,基于这些,可以和其他拟合能力强的神经网络结合,比如极限学习机,RBF等,结合后的神经网络,即可处理大输入数据,又具有无限逼近的能力,有需要扩展的欢迎扫描文章下面的二维码
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!