
BEVDET论文与代码解读
一、前言
虽然自己主要精力在做单目3D检测,但基于多摄融合BEV视角的3D检测也是热度比较高的方向,因此学习补充这方面的知识很有必要,自己也将对论文和代码的一些理解也分享出来。
二、BEV
随着车载传感器类型和数量的不断增多,研究者们期望找到一个统一的表征空间,将多传感器感知统一表达,较为常用的方法是感知后融合方式,这类后融合方式方法较为复杂,且很多融合都需要先验知识和手工设计,鲁棒性不高。2021年的特斯拉AI Day提出了基于BEV的自动驾驶方案,之后国内各大车企也开始探索这一方向。
三、BEVDET
BEVDET也是比较早提出的论文,该论文较为工程化,没有花里胡哨的东西,主要是结合一些现有的方法,实现了在BEV视角的3D检测。
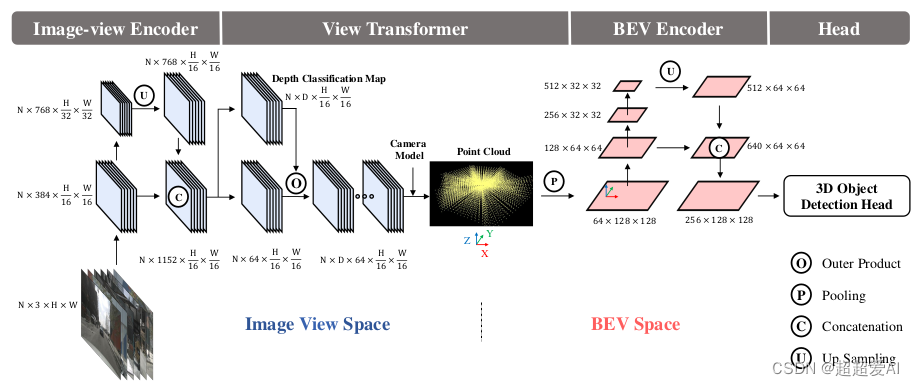
从上图中可以看到作者将其划分为Image View Space 和 BEV Space,分别表示透视视角空间和鸟瞰图视角空间。
Image View Space:在透视视角空间,主要做的是对多摄图像的特征提取,这里的backbone可以选择resnet、swin-transformer等等,然后经过FPN_LSS进行简单的层级特征融合,输出16倍下采样的特征图。
View Transformer:是连接Image View Space和BEV Space的桥梁,将Image View Space的图像特征投影到BEV Space。作者采用的是LSS中的方法进行特征投射,该方法可参考我上一篇博客LSS-lift splat shoot论文与代码解读_超超爱AI的博客-CSDN博客。
BEV Space:BEV的特征提取和整理,作者提出经过View Transformer的特征对于较为简单的任务,如语义分割是直接可以接head头的,但是3D检测在加入BEV encoder进行特征提取和整理能够有效的提升检测效果。
Head:任务输出设计,因为在View Transformer中有特征信息的丢失,一些目标的细节特征不如基于Image View Base 方法,也就是单目的方法。因此在 头部设计中会根据目标尺寸划分分类目标,再到相似尺度内进行细分类和回归。除了分类任务外,回归任务包含中心点位置(2个量化偏移量,1个高度),尺寸(长宽高),旋转角,速度。也是参考centerpoint的头部,在雷达数据中证明头部的两阶段方式有利于提升检测效果,但在图像数据中head的两阶段设计并为证实有效性,因此作者head部分依然采用高效的单阶段方式。
四、贡献点
一、作者也在论文中大方的承认了主要是做了整合的工作,将现有的各类方法进行结合使用,实现了BEV 3D检测的任务。
二、作者认为nuscenes的数据相对来说还是数据量不大,因此数据增广十分有必要,且View Transformer会使得两个空间独立起来,在Image View Space的仿射变换等数据增广(ida)并不能改变BEV Space的特征分布,且Image View Space有多个图像,BEV Space才对应一个特征图输入。因此作者也在BEV空间作了数据增强(bda)。
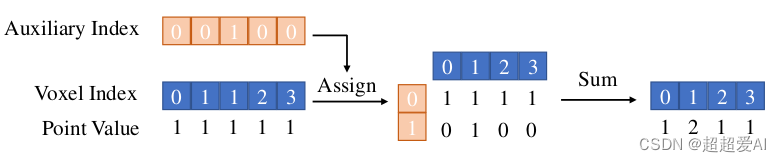
三、作者认为LSS中的一些rank计算可以放到init里面,不用在训练中一直重复计算,因为内外参、BEV空间设计和仿射变换矩阵啥都是知道的,能够很有效的提升训练和推理速度。
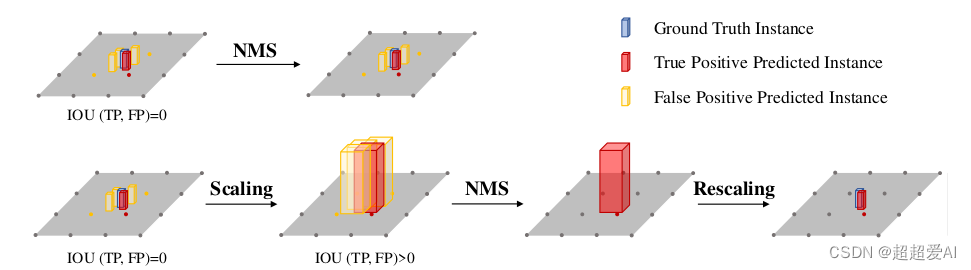
四、作者觉得BEV空间太紧凑了,一些目标的中心点在BEV上挨的很近,因此用了一个系数scale进行放缩,将nms替换成了scale nms,这个scale也是根据目标类别尺寸统计得到的,比较手工的方法。对小目标的检测效果提升有益。
五、总结
本来也想对应代码讲讲,但是截图太麻烦,而且已经手打了这么多字了,很良心了。代码其实也比较简单,理解论文了看一遍就懂了。
这里也说说BEV的一些优势和劣势:
优势:1、截断和遮挡目标。 2、统一的表征空间 。
劣势:1、视角转化时候的信息丢失。 2、部署对硬件和算力要求高。
相关文章
- 学习ASP.NET Core Blazor编程系列二十三——登录(2)
- C#零基础小白快速入门指导
- 论文翻译:2022_腾讯DNS 1th TEA-PSE: Tencent-ethereal-audio-lab personalized speech enhancement system for ICASSP 2022 DNS CHALLENGE
- Spring学习笔记 - 第二章 - 注解开发、配置管理第三方Bean、注解管理第三方Bean、Spring 整合 MyBatis 和 Junit 案例
- 微软外服工作札记②——聊聊微软的知识管理服务平台和一些编程风格
- 微软外服工作札记③——窗口函数的介绍
- ASP.NET Core RESTful学习理解
- 一文带你入门图机器学习
- 迁移学习(ADDA)《Adversarial Discriminative Domain Adaptation》【已复现迁移】
- 迁移学习(DIFEX)《Domain-invariant Feature Exploration for Domain Generalization》【已复现迁移】
- 【学习笔记】Kruskal 重构树
- 探究:初学者编程语言的选择
- 写了一年的博客,我收获了什么
- SpringBoot源码学习3——SpringBoot启动流程
- Spring源码学习笔记12——总结篇,IOC,Bean的生命周期,三大扩展点
- ING国际银行基于Volcano的大数据分析平台应用实践
- STM32 学习方法
- 迁移学习(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》
- 你知道,前端工程部署有哪些方式嘛?
- 腾讯出品小程序自动化测试框架【Minium】系列(一)环境搭建之第一个测试程序