
目标检测算法——YOLOv5/YOLOv7改进之结合NAMAttention(提升涨点)
2023-04-18 16:38:17 时间

>>>深度学习Tricks,第一时间送达<<<
目录
NAMAttention,一种新的注意力计算方式,无需额外的参数!
(二)YOLOv5/YOLOv7改进之结合NAMAttention
NAMAttention,一种新的注意力计算方式,无需额外的参数!
(一)前沿介绍
论文题目:NAM: Normalization-based Attention Module
论文地址:https://arxiv.org/abs/2111.12419
代码地址:https://github.com/Christian-lyc/NAM

作者提出了一种基于归一化的注意力模块(NAMAttention),可以降低不太显著的特征的权重,这种方式在注意力模块上应用了稀疏的权重惩罚,这使得这些权重在计算上更加高效,同时能够保持同样的性能。在ResNet和MobileNet上和其他的注意力方式进行了对比,该方法可以达到更高的准确率。
1.NAM结构图
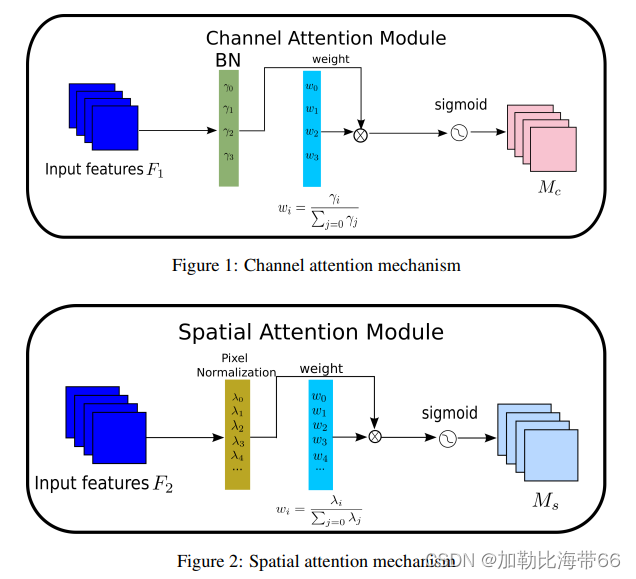
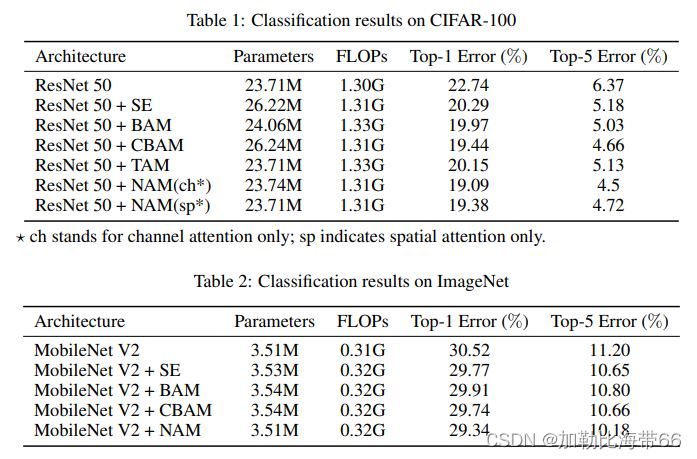
2.相关实验结果
作者将NAM和SE,BAM,CBAM,TAM在ResNet和MobileNet上,在CIFAR100数据集和ImageNet数据集上进行了对比,对每种注意力机制都使用了同样的预处理和训练方式,对比结果表示,在CIFAR100上,单独使用NAM的通道注意力或者空间注意力就可以达到超越其他方式的效果。在ImageNet上,同时使用NAM的通道注意力和空间注意力可以达到超越其他方法的效果。
(二)YOLOv5/YOLOv7改进之结合NAMAttention
改进方法和其他注意力机制一样,分三步走:
1.配置common.py文件
加入NAM代码。
#NAM
class NAM(nn.Module):
def __init__(self, channels, t=16):
super(NAM, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x2.配置yolo.py文件
加入NAM模块。
3.配置yolov5_NAM.yaml文件
添加方法灵活多变,Backbone或者Neck都可。
关于算法改进及论文投稿可关注并留言博主的CSDN/QQ
>>>一起交流!互相学习!共同进步!<<<
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击