
初入datawork生态圈的架构
前文:
越来越多小公司上云了,这个是大势所趋。现在主流是阿里云和腾讯云,此文通过分享这两个下来的感受让大家接触云平台开发。
一、背景
相比自建机房,大部分公司上云省时省力,具体上哪个云取决于公司的业务发展,毕竟拉通带宽蛮贵的,腾讯云成本比阿里云便宜一半,但阿里的组件生态圈选择性比较多(其实也没多少预算可以选择...) 如果选择上云,那么你有两种选择,平台开发/EMR模式,取决于人员配置/业务发展,一个人才成本高/一个组件成本高。因为是新建团队,为了响应需求,目前是选择了平台开发快速交付。
二、架构
2.1 主要架构
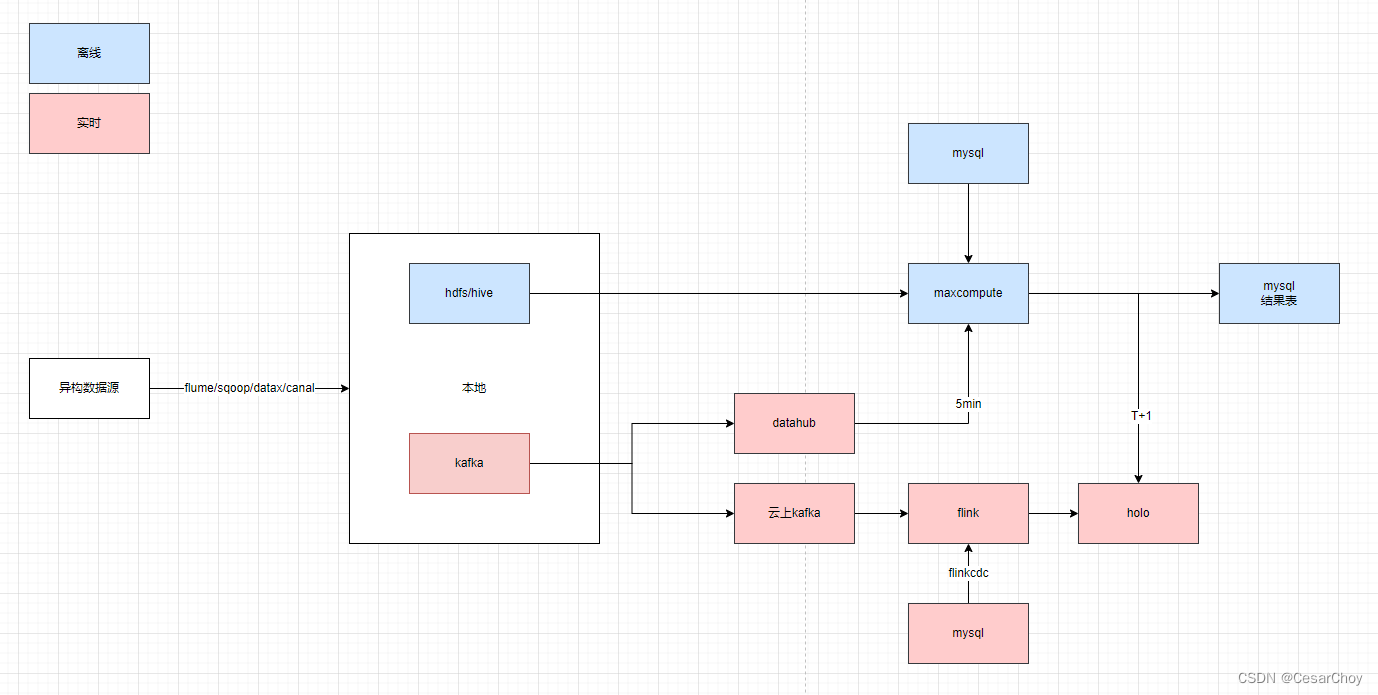
2.2 数据集成
2.2.1 业务库投递方案
目前所有数据库都在阿里云的数据库上,所以直接使用datawork数据同步工具即可。
2.2.2 实时日志投递方案
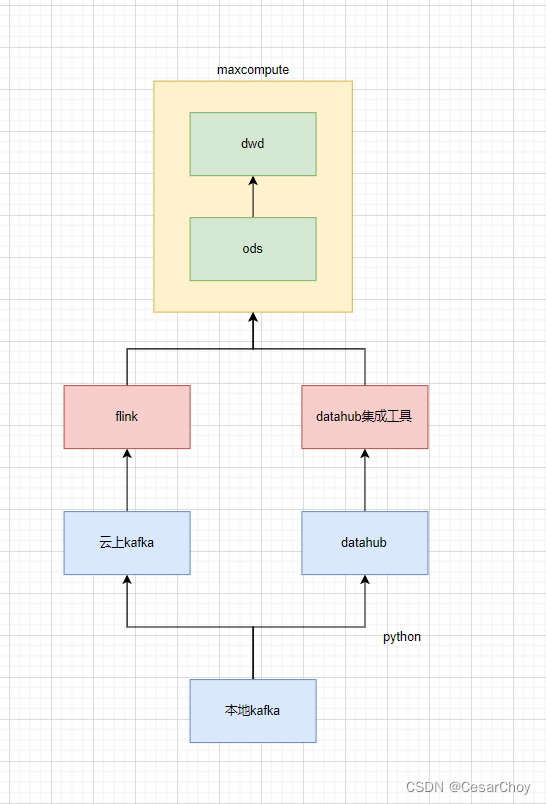
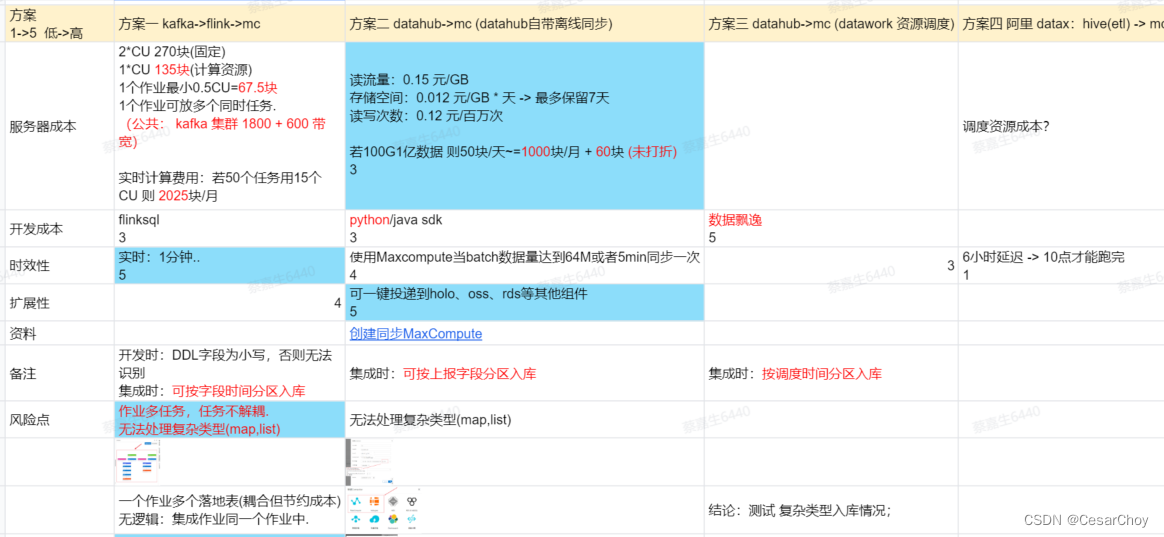
结论:实时链路通过使用datahub一键投递,按需付费更便宜,并可解决数据偏移问题。这里有个小片段,如果没啥实时需求kafka开通了晾在那也蛮贵的,还需要懂 flink 的人员配置。
2.3 开发
2.3.1 离线开发
天/小时级别作业通过datawork开发,写入到 mysql 或 holo 外部表查询。
2.3.2 实时开发
分钟级别作业:基于 datawork 调度每 5/10分钟 调度holo脚本。
实时级别作业:通过 flink 实时计算后 入库。
主要还是看场景,增量/全量场景区分好选型即可;flink实时计算有定制语法帮助实现mysql数据实时同步到holo,满足实时场景,datawork就达不到这种效果。
详情参考:Hologres推荐的数仓分层-数据-场景-实时-实时数仓Hologres-阿里云
2.4 优缺点
2.4.1 优点
(1) 开发:数据地图,协助我们看每张表的血缘地图,并可一键查看该表所有信息。很多公司投入大量研发后基本没有产出。
(2) 调度:基于作业实例调度,当中间某个节点未完成/错误将导致下游所有节点阻塞,重跑该节点后下游节点可自动修复。像使用dolphinscheduler,下游作业要一个一个去重跑极其麻烦。
(3) 告警:一键配置全局作业告警,无需每个作业配置告警。
2.4.2 缺点
(1) 价格昂贵,预算不足,很多组件无法测试/开通。
(2) datawork 无法/微批次 更新贴源层数据,T+1拉取业务库大表对业务库影响较大。虽然有实时同步作业,但是应该是个kpi诞生下的怪胎。业界基本都有hudi、iceberg等解决方案,不知道后续是否有兼容计划,或还是得去用另一个数据湖分析组件。
相关文章
- Confluence 如何在页面中显示目录
- 运维文档的几点看法
- OpenJDK 8 安装
- Markdown 语法
- 使用MySQLBinlog按时间查询二进制日志时易疏忽的地方
- 戈登·摩尔
- 编写 Dockerfile 生成自定义镜像
- 对比Imagick和Gmagick的像素迭代功能
- 反弹SHELL介绍及原理
- 使用Imagick实现图像直方图
- 2020总结来了,文末有福利
- CentOS 用户请关注,你期待的 CentOS Linux 9 再也不会来了
- PHP数组交集的优化
- 浅谈Heatmap
- 快速排序算法介绍
- 完美实现GIF动画缩略图
- python scrapy框架 爬取网页页数多时,造成数据为空
- Umask补习班
- Linux bash 命令行快捷键
- 白话BigPipe