
Openstack 通信
OpenStack的通信方式有两种,一种是基于HTTP协议的RESTFul API方式,另一种则是RPC调用。
两种通信方式的应用场景有所不同,在OpenStack中,前者主要用于各组件之间的通信(如nova与glance的通信),而后者则用于同一组件中各个不同模块之间的通信(如nova组件中nova-compute与nova-scheduler的通信)。
1.OpenStack中基于RESTFul API的通信方式主要是应用了WSGI
2.RPC采用AMQP协议实现进程间通信,而RabbitMQ正是AMQP的实现方式,所以可以说OpenStack中的RPC调用都是基于RabbitMq完成的
**
WSGI
**
全称是Web Server Gateway Interface,WSGI只是一种规范,描述web server与web application通信的规范
WSGI协议主要包括server和application两部分:
• Web server/gateway: 即 HTTP Server,处理 HTTP 协议,接受用户 HTTP 请求和提供并发,调用 web application 处理业务逻辑。WSGI server负责从客户端接收请求,将request转发给application,将application返回的response返回给客户端;
• Python Web application/framework: WSGI application接收由server转发的request,处理请求,并将处理结果返回给server。application中可以包括多个栈式的中间件(middlewares),这些中间件需要同时实现server与application,因此可以在WSGI服务器与WSGI应用之间起调节作用:对服务器来说,中间件扮演应用程序,对应用程序来说,中间件扮演服务器。
WSGI协议其实是定义了一种server与application解耦的规范,即可以有多个实现WSGI server的服务器,也可以有多个实现WSGI application的框架,那么就可以选择任意的server和application组合实现自己的web应用。
Application/Framework
Application/framework 端必须定义一个 callable object,callable object 可以是以下三者之一:
function
method
class/instance with a _call_ method
Callable object 必须满足以下两个条件:
• 接受两个参数:字典(environ),回调函数(start_response,返回 HTTP status,headers 给 web server)
• 返回一个可迭代的值
基于 callable function 的 application/framework 样例如下:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['This is a python application!']
基于 callable class 的 application/framework 样例如下:
class ApplicationClass(object):
def __init__(self, environ, start_response):
self.environ = environ
self.start_response = start_response
def __iter__(self):
self.start_response('200 OK', [('Content-type', 'text/plain')])
yield "Hello world!n"
Server/Gateway
Server/gateway 端主要专注 HTTP 层面的业务,重点是接收 HTTP 请求和提供并发。每当收到 HTTP 请求,server/gateway 必须调用 callable object:
接收 HTTP 请求,但是不关心 HTTP url, HTTP method 等
为 environ 提供必要的参数,实现一个回调函数 start_response,并传给 callable object
# application/framework side
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['This is a python application!']
# server/gateway side
if __name__ == '__main__':
from wsgiref.simple_server import make_server
server = make_server('0.0.0.0', 8080, application)
server.serve_forever()
Middleware: Components that Play Both Sides
Middleware 处于 server/gateway 和 application/framework 之间,对 server/gateway 来说,它相当于 application/framework;对 application/framework 来说,它相当于 server/gateway。每个 middleware 实现不同的功能,我们通常根据需求选择相应的 middleware 并组合起来,实现所需的功能。比如,可在 middleware 中实现以下功能:
• 根据 url 把用户请求调度到不同的 application 中。
• 负载均衡,转发用户请求
• 预处理 XSL 等相关数据
• 限制请求速率,设置白名单
**
RPC
**
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议”。这个概念听起来还是比较抽象,下面我会结合OpenStack中RPC调用的具体应用来具体分析一下这个协议。
其次,为什么要采用RPC呢?单纯的依靠RESTFul API不可以吗?其实原因有下面这几个:
- 由于RESTFul API是基于HTTP协议的,因此客户端与服务端之间所能传输的消息仅限于文本
- RESTFul API客户端与服务端之间采用的是同步机制,当发送HTTP请求时,客户端需要等待服务端的响应。当然对于这一点是可以通过一些技术来实现异步的机制的
- 采用RESTFul API,客户端与服务端之间虽然可以独立开发,但还是存在耦合。比如,客户端在发送请求的时,必须知道服务器的地址,且必须保证服务器正常工作
基于上面这几个原因,所以OpenStack才采用了另一种远程通信机制,这就是我们今天要讨论的鼎鼎大名的RPC。
要了解OpenStack中的RPC,有一个组件是必不可少的,那就是RabbitMQ(消息队列)。OpenStack中,RPC采用AMQP协议实现进程间通信,而RabbitMQ正是AMQP的实现方式,所以可以说OpenStack中的RPC调用都是基于RabbitMq完成的
在Nova中,定义了两种远程调用方式——rpc.call和rpc.cast。其中rpc.call方式是指request/response(请求/响应)模式,即客户端在发送请求后,继续等待服务器端的响应结果,待响应结果到达后,才结束整个过程。rpc.cast方式是指客户端发送RPC调用请求后,不等待服务器端的响应结果。不难看出,较rpc.cast模式,rpc.call更为复杂。为了处理rpc.call,Nova采用了Topic Exchange(主题交换器)和Direct Exchange(直接交换器)两种消息交换器。其中Topic Exchange用于客户端向服务器端rpc.call的发起,Direct Exchange用于服务器端向客户端返回rpc.call。对应于这两种交换机,Nova中定义了Topic/Direct消息消费者、Topic/Direct消息发布者、Topic/Direct交换器。
需要说明的是一个主题交换器可以关联多个队列,而一个直接交换器只能关联一个队列。
cinder-api是cinder 服务的endpoint, 提供了rest接口,负责处理client的请求,并将rest请求解封,并重新封装成RPC请求至cinder-scheduler组件;除dashboard之外,所有的服务均有XXX-api作为XXX服务的endpoint,提供rest 接口,负责处理XXXclient 的请求
openstack组件内部的RPC(Remote Producer Call)机制的实现是基于AMQP协议作为通讯模型,从而组件内部的松耦合性。AMQP是用于异步消息通讯的消息中间件协议;AMQP模型有四个重要的角色:
• Exchange: 根据Routing key转发消息到对应的Message Queue中;
• Routing key: 用于Exchange判断那些消息需要发送对应的Message Queue
• Publisher: 消息发送者,将消息发送的Exchange并指明Routing Key,以便Message Queue可以正确的收到消息;
• Consumer:消息接受者,从Message Queue获取消息;
消息发布者 Publisher 将 Message 发送给 Exchange 并且说明 Routing Key。Exchange 负责根据 Message 的 Routing Key 进行路由,将 Message 正确地转发给相应的 Message Queue。监听在 Message Queue 上的 Consumer 将会从 Queue 中读取消息。
Routing Key 是 Exchange 转发信息的依据,因此每个消息都有一个 Routing Key 表明可以接受消息的目的地址,而每个 Message Queue 都可以通过将自己想要接收的 Routing Key 告诉 Exchange 进行 binding,这样 Exchange 就可以将消息正确地转发给相应的 Message Queue。
OpenStack层封装call和cast接口用于远程调用RPC的server上的方法,这些方法都是构造RPC的server的endpoints内的方法。远程调用时,需要提供一个字典对象来指明调用的上下文,调用方法的名字和传递给调用方法的参数(用字典表示)。如:
cctxt =self.client.prepare(vesion=’2.0’)
cctxt.cast(context,‘build_instances’, **kw)
通过cast方式的远程调用,请求发送后就直接返回了;通过call方式远程调用,需要等响应从服务器返回.
AMQP messaging 中的基本概念
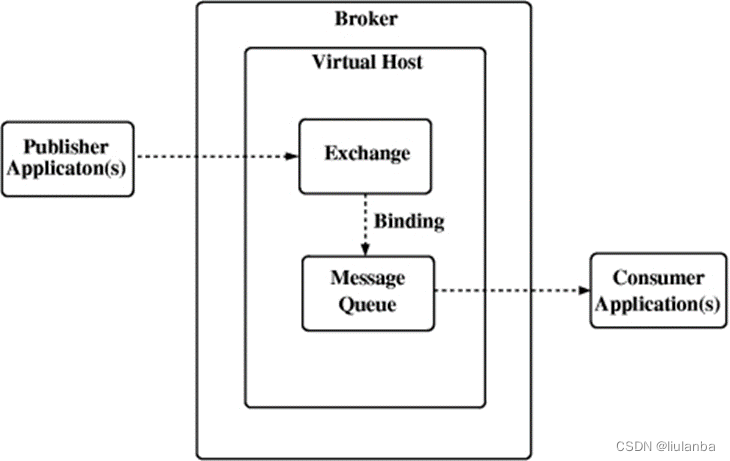
• Broker: 接收和分发消息的应用,RabbitMQ Server就是Message Broker。
• Virtual host: 出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue等
• Connection: publisher/consumer和broker之间的TCP连接。断开连接的操作只会在client端进行,Broker不会断开连接,除非出现网络故障或broker服务出现问题。
• Channel: 如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
• Exchange: message到达broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。常用的类型有:direct (point-to-point), topic (publish-subscribe) and fanout (multicast)。
• Queue: 消息最终被送到这里等待consumer取走。一个message可以被同时拷贝到多个queue中。
• Binding: exchange和queue之间的虚拟连接,binding中可以包含routing key。Binding信息被保存到exchange中的查询表中,用于message的分发依据。
“生产/消费”消息模型
生产者发送消息到broker server(RabbitMQ)。在Broker内部,用户创建Exchange/Queue,通过Binding规则将两者联系在一起。Exchange分发消息,根据类型/binding的不同分发策略有区别。消息最后来到Queue中,等待消费者取走。
在线程世界里,生产者就是生产数据(或者说发布任务)的线程,消费者就是消费数据(或者说处理任务)的线程。在任务执行过程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者提供更多的任务,本质上,这是一种供需不平衡的表现。为了解决这个问题,我们创造了生产者和消费者模式。
生产者消费者模式的工作机制:
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而是通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不直接找生产者要数据,而是从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力,解耦了生产者和消费者。
Exchange类型
Exchange有多种类型,最常用的是Direct/Fanout/Topic三种类型。
Direct (point 2 point 点对点模式)
Message中的“routing key”如果和Binding中的“binding key”一致, Direct exchange则将message发到对应的queue中。
Fanout (多播模式)
每个发到Fanout类型Exchange的message都会分到所有绑定的queue上去。
Topic (发布-订阅模式)
根据routing key,及通配规则,Topic exchange将分发到目标queue中。
相关文章
- 参数量仅0.5B,谷歌代码补全新方法将内部生产效率提升6%
- 15年软件架构师经验总结:在ML领域,初学者踩过的五个坑
- Linux 5.19 正式发布!这次用的竟然是 MacBook.....
- 2022年世界各国程序员薪资水平报告:第1名是中国程序员的5倍
- 微软新工具准确率达80%,程序员:真的栓 Q
- 七月超受欢迎的AI研究榜单出炉,马毅最新「标准模型」排名第九
- 司机路上的“神助攻”!北理工研发混合脑机接口驾驶辅助系统,提高驾驶安全性
- “C++继任者”火到GitHub趋势榜一,C++之父:规范不足,无法评价
- Meta这篇语言互译大模型研究,结果对比都是「套路」
- 报告:想学AI的学生数量已涨200%,老师都不够用了
- 这个困扰程序员50年的问题,终于要被解决了?
- 用上这个开源本地缓存工具,Redis读写完全没压力!
- B站接入层网络演进实践
- 角速度、线速度之外,描述宇宙还有另一种方式?AI发现新变量登Nature子刊
- 软件工程师的硬件抓狂指南
- 不堆概念、换个角度聊多线程并发编程
- 华为鸿蒙3.0正式发布,这次破了安卓圈?
- 谷歌团队推出新Transformer,优化全景分割方案
- 谁来助我与算法共舞——算法管理中的领导力
- 最新的目标检测的深度架构 参数少一半、速度快3倍+