
print(torch.cuda.is_available()) 返回false的解决办法
print(torch.cuda.is_available()) 返回false的解决办法
1.问题简述
今天给新电脑配置pytorch深度学习环境,最后调用python打印print(torch.cuda.is_available())一直出现false的情况(也就是说无法使用GPU),最后上网查找资料得出报错的原因:下载的pytorch是CPU版本,而非GPU版本。
2.报错原因
按照最开始的方法,在pytorch的官网上根据自己的cuda版本(笔者为cuda11.5)使用对应的指令在conda prompt中在线下载:conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch。为了使下载速度加快,我们一般会将后面的-c python删除,采用清华镜像源地址进行安装,例如:
conda install pytorch torchvision torchaudio cudatoolkit=11.3
(清华源加速需要提前部署好,可参考其他博客)。
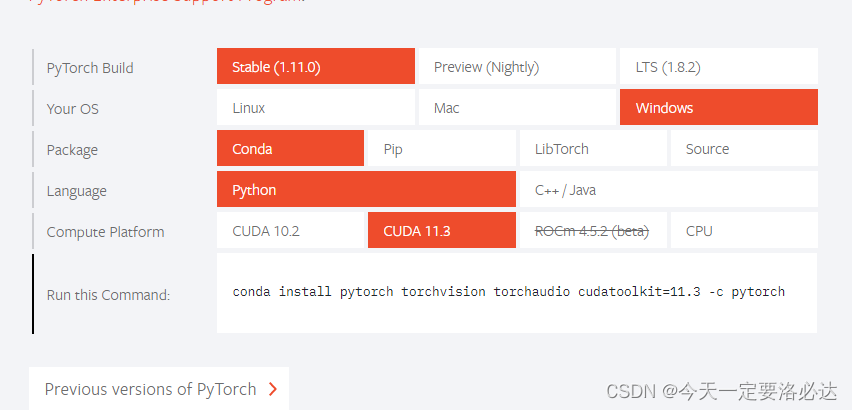
然鹅错误就出在清华镜像源这里,从网上查资料可得,镜像源下载的一般为CPU版本,也是这导致前面所说一直返回false。如果不使用清华源,在官网下载速度又太慢,这个时候我们考虑pip安装。
3.解决办法
首先进入离线文件的下载地址:link.

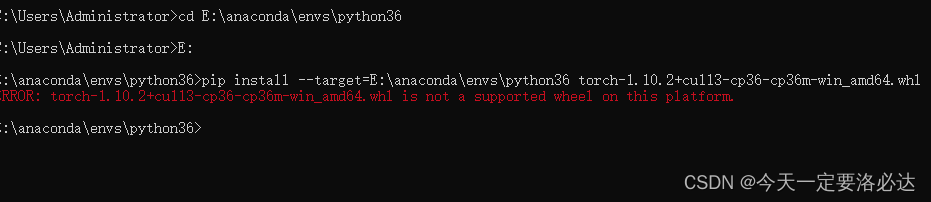
在其中找到符合自己的那个文件。注意看清要下载的包的名字,torch还是其他啥。cuxxx一般是支持cuda的包。看好自己环境中的python处理器是什么版本的,不要下载错了,比如python3.6就是cp36。window,linux版本区分清楚。如下图所示就是python对应版本出错后的结果(后续安装离线文件报错)
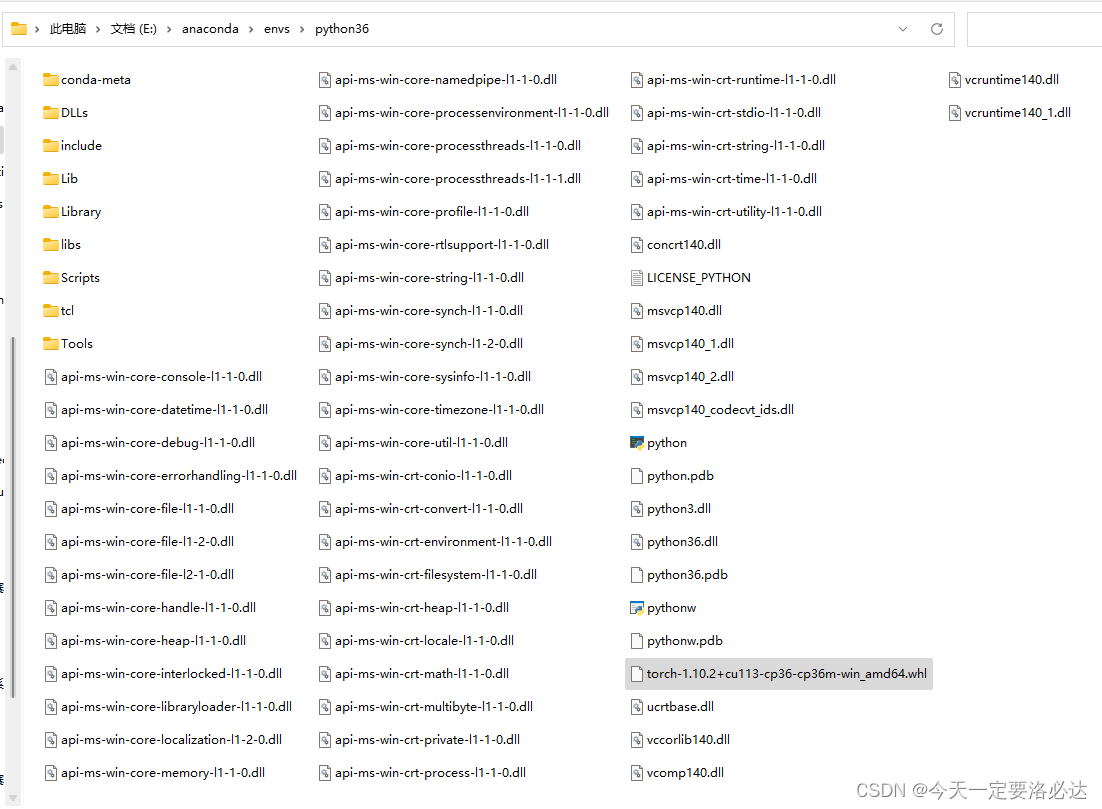
下载完离线文件后,将离线文件放在你需要安装的环境中,如下图,我放在了我自己的深度学习环境python36中,在anconda的envs中。
最后一步就是打开conda prompt ,从base环境切到你自己的环境里,通过cd命令切换到那个环境的文件地址中(切cd操作可以参考其他文章),同时最后输入指令pip install 文件名,例如:pip install torch-1.10.2+cu113-cp36-cp36m-win_amd64.whl

最后静等不到一分钟,就安装好了。去python测试,终于不报错了,也能显示存在一张工作的显卡
检查GPU是否可用的代码:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.device_count())
最后结果:
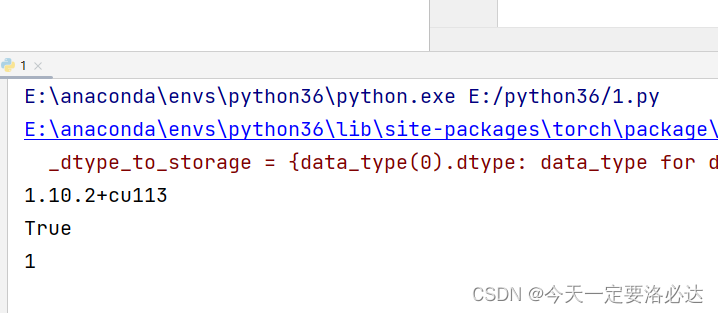
这里有一个报错是numpy的版本不对,后面卸载了重装就是了。
相关文章
- 谷歌云试图抢占SAP软件云市场 但击败微软和亚马逊并不易
- 「黑悟空」实机演示炸裂登场,英伟达大秀光追技术
- Google人工智能技术“Transframer”可根据一张图片创建短视频
- 华为云工业互联网加持,云鲸发展夯实数字底座
- 华为云首席产品官方国伟:全栈云原生技术助力金融突破创新瓶颈
- 早知道早受益,将成趋势的NaaS究竟是什么?
- 消费级GPU成功运行1760亿参数大模型
- 研究表明:数据来源仍然是 AI 的主要瓶颈
- 云上奥运:更高!更快!更强! 2021MAXP全球高性能云计算创新大赛隆重开幕!
- VMware创新网络:从开源协作到现实共赢
- IDC 预测到 2025 年云支出将达到 1.3 万亿美元
- 集成AI和ML 以很大限度地提高运营效率的好处
- 5G承载网里的FlexE,到底是什么?
- 选择性风险可以提高AI的公平性和准确性
- ResearchAndMarkets:2027年全球云计算服务产业规模将达3131亿美元
- 长亭科技新品发布会在北京举行 重构网络防护新体系
- 解读京东零售云mPaaS中Flutter中热重载原理
- 人脸识别案件频发,多模态生物核验能否成为新的“银弹”?
- 风口之下,车企如何掘金万亿级智慧出行市场
- 能源领域物联网边缘计算的挑战和机遇