
ElasticSearch的数据存储及写入原理
数据存储
数据存储介绍
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。
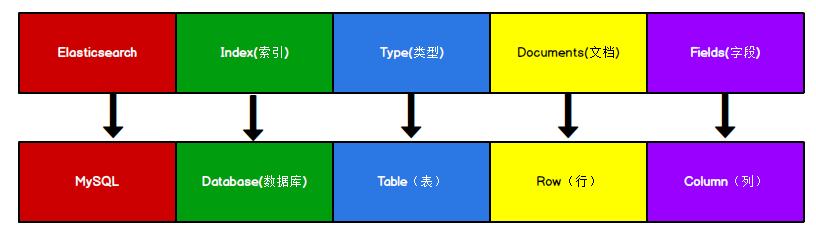
注意:Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。可以理解为一个索引就是一个数据集。
数据存储形式
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
注意:id可以自己指定,可以理解为Mysql中的主键,不指定会自动生成。
数据写入原理
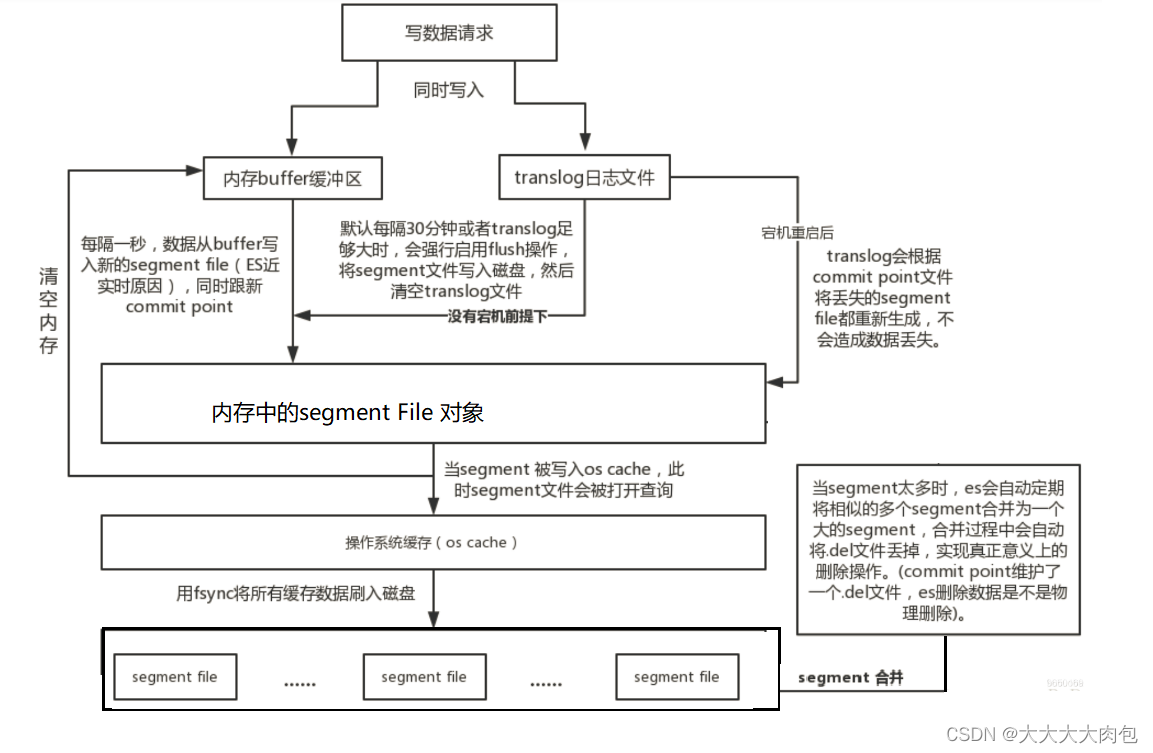
写入流程
- 数据先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
-
每隔 1 秒钟或者buffer 快满了,es 将 buffer 中的数据写入一个新的 segment file ,每秒钟会产生一个新的segment file ,这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。
-
将内存segment file刷写到系统缓存(os cache),此时可以数据可以被搜索到(refresh),并且会清空buffer,translog 保留。
-
随着这个过程推进,translog 会变得越来越大。当 translog 足够大或者到达30分钟的时候,就会触发 commit 操作。
-
commit 操作发生第一步,就是将 buffer 中现有数据 refresh 到 os cache 中去,清空 buffer。然后,将一个 commit point 写入磁盘文件,里面标识着这个 commit point 对应的所有 segment file ,同时强行将 os cache 中目前所有的数据都 fsync 到磁盘文件中去。最后清空现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。
-
当磁盘中的segment文件太多的时候,es会自动定期的将相思的segment合并成一个大的segment,并且会根据 .del 文件,来实现物理删除。
总结
数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们说es 是准实时的, es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
translog日志文件的作用
在执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件 translog 中,一旦此时机器宕机重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。
注意:translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
refresh操作和flush操作的对比
refresh操作:数据从Segment File到os cache这个过程被称为refresh。
flush操作:es默认每隔30分钟会将os cache中的数据刷入磁盘同时清空translog日志文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了,这个过程叫flush。
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!