
Kettle(二)数据同步、迁移(基础版)
2023-04-18 16:26:26 时间
目录
Kettle支持多种数据源,MySql、Oracle、Excel等,本文以最简单的Mysql向MySql迁移为例。后续逐步增加复杂度,如:表格不一致时,增加数据常亮、数据筛选、新增自增列等等,甚至增加脚本逻辑代码。
1.配置源数据库A
1.1 文件-->数据库连接
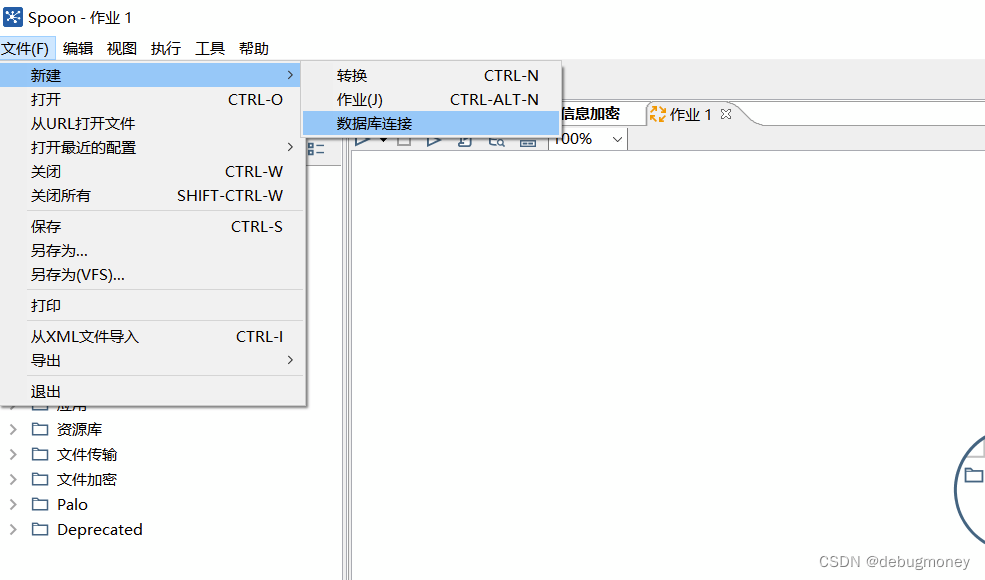
1.2 配置数据库,选择自己的数据库并配置。
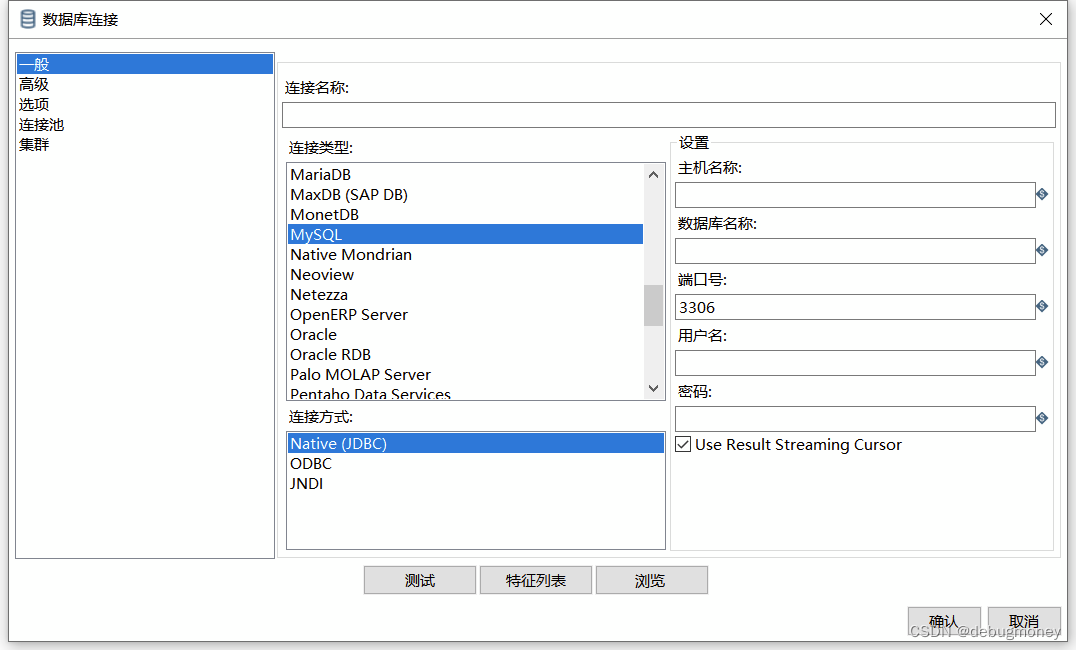
1.3 数据库配置可能会报错,原因是缺少数据库驱动
错误连接数据库 [kettle_mysql] : org.pentaho.di.core.exception.KettleDatabaseException:
Error occurred while trying to connect to the database
Driver class 'org.gjt.mm.mysql.Driver' could not be found, make sure the 'MySQL' driver (jar file) is installed.
org.gjt.mm.mysql.Driver解决办法:拷贝响应的数据库驱动(例如 mysql-connector-java-5.1.47.jar)至 目录bin,并重启客户端
2.配置目标数据库(与源数据库一致)
3.数据迁移(举例)
3.1 创建数据转化任务
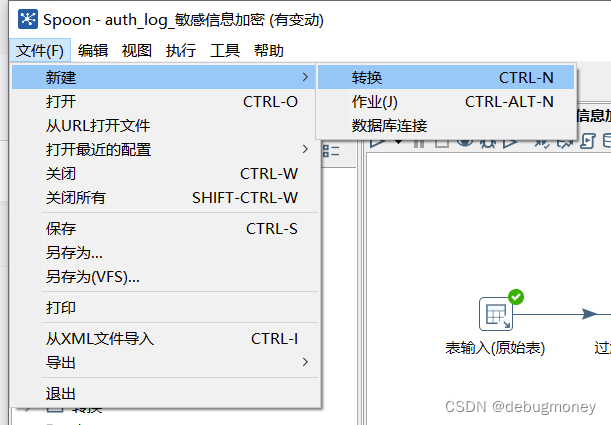
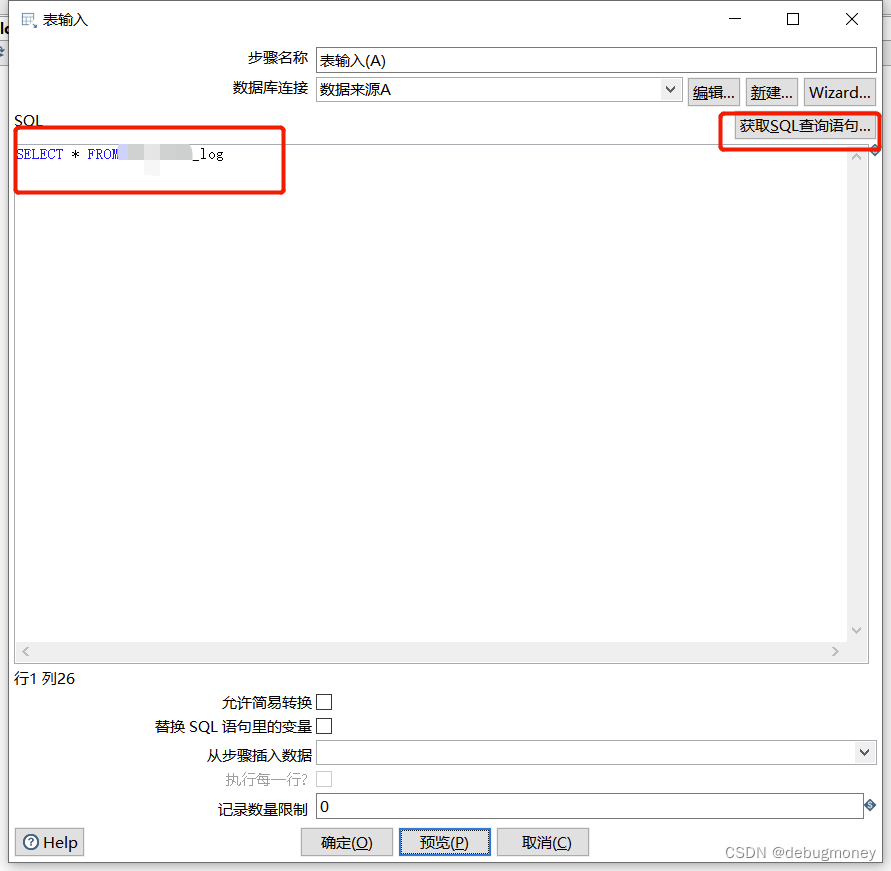
3.2 选择数据来源(输入--> 表输入)
1)可以手动写SQL语句,可以手动增加筛选条件 where
2) 也可以通过“获取SQL语句”,通过界面化页面选择
3)选择数源的结果,可以通过“预览” 进行查看
3.3 选择数据去向(输出--> 表输出)
1)根据自己的业务选择输出目标 数据表、Excel文件等
2)表输出选择与表输入一致
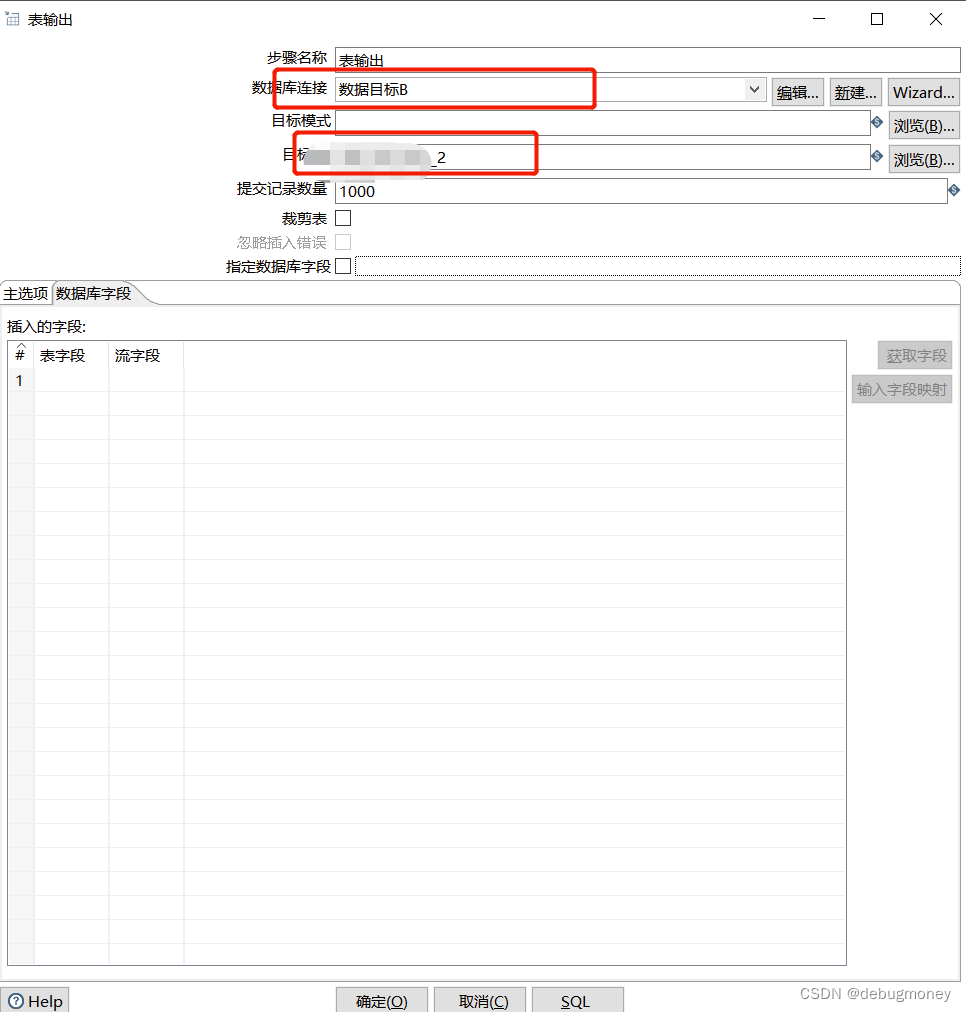
3)如果来源表与目标表结构一致,其实这一步已经可以了。
4)开始做表数据关联
选中“表输入A” 关联按钮指向 “表输出B”

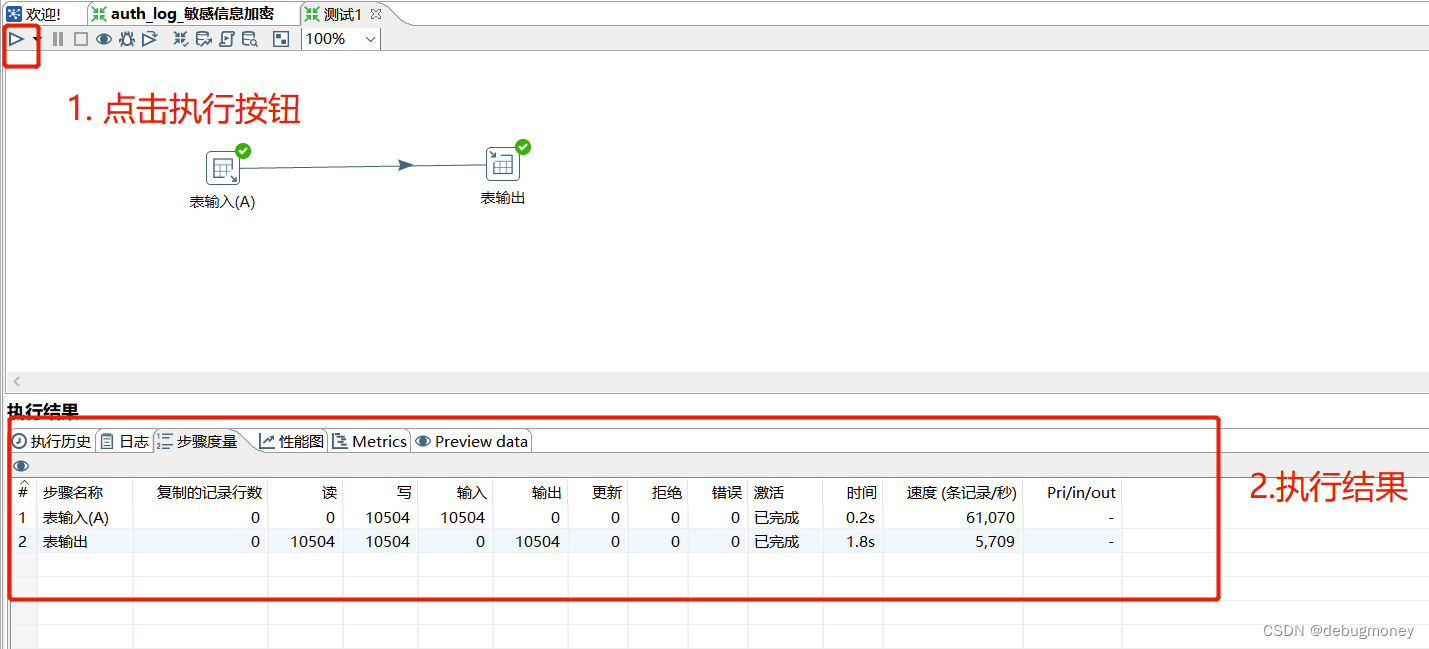
4. 数据转化开始执行
5.其他
往往在工作中表输入A 与 表输出B的结构可能不一致。也可能“表输出B”在写入时需要依据“输入表A”的数据增加一些业务逻辑判断,从而进行不同逻辑的处理之后才可以应用。后续将逐步完善
相关文章
- 备份的 “算子下推”:BR 简介丨TiDB 工具分享
- Spark 入门简介
- Spark Shuffle 机制解析
- 详解操作系统之进程间通信 IPC (InterProcess Communication)
- SQL 优化技术系列: 谓词下推
- HBase vs Redis
- 什么是 Spark RDD ?
- Spark 极简教程
- 详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS
- 前端编程-大气模拟计算之周边排放源影响
- 图解聊聊分库分表:如何做到永不迁移数据和避免热点?
- 【Spark重点难点06】SparkSQL YYDS(中)!
- 引入RabbitMQ后,如何保证全链路数据100%不丢失?
- SoC接口技术之低速接口
- 生态学JAGS模拟数据、回归、CORMACK-JOLLY-SEBER (CJS) 模型拟合MCMC 估计动物存活率
- (8/30)Blazor系列:CSS样式修改和数据绑定详述
- MyBatis 批量插入几千条数据,请慎用Foreach
- 玩转SQLite4:SQLite数据插入与查看
- DRF的Request对象和Response对象
- 新入坑的SageMaker Studio Lab和Colab、Kaggle相比,性能如何?