
mysql 批量数据插入很慢(kettle 输入输出组件) 性能优化办法
背景
最近在做数仓重构项目,遇到一些性能瓶颈,这里记录一下解决办法。
随着业务数据每天都在增加,几年前开发的etl任务开始跑不动了。大表一般是通过增量的方式插入,但是修复bug 或者每月/季度跑一次的情况 需要跑全量,原来的etl任务可能需要跑几个小时,甚至出现超时失败的情况。因此需要优化,下面介绍一些优化方法。(项目是用kettle做的,如果使用其他开发工具,也可以参考下面的思路)
1、配置数据库连接参数
2、去掉临时表 DDL的primary key
3、调整输出组件的数量
4、暂时关闭索引
优化方法
1、配置数据库连接参数
defaultFetchSize:5000
useCursorFetch : true 相当于告诉数据库,分批读取数据,每次打包5000条回来
rewriteBatchedStatements : true 插入数据的时候,批量插入
useServerPrepStmts : true 启动预编译
useCompression : true 客户端跟服务器之间的数据压缩传输
以kettle为例,配置方法如下:

测试结果:
配置参数前: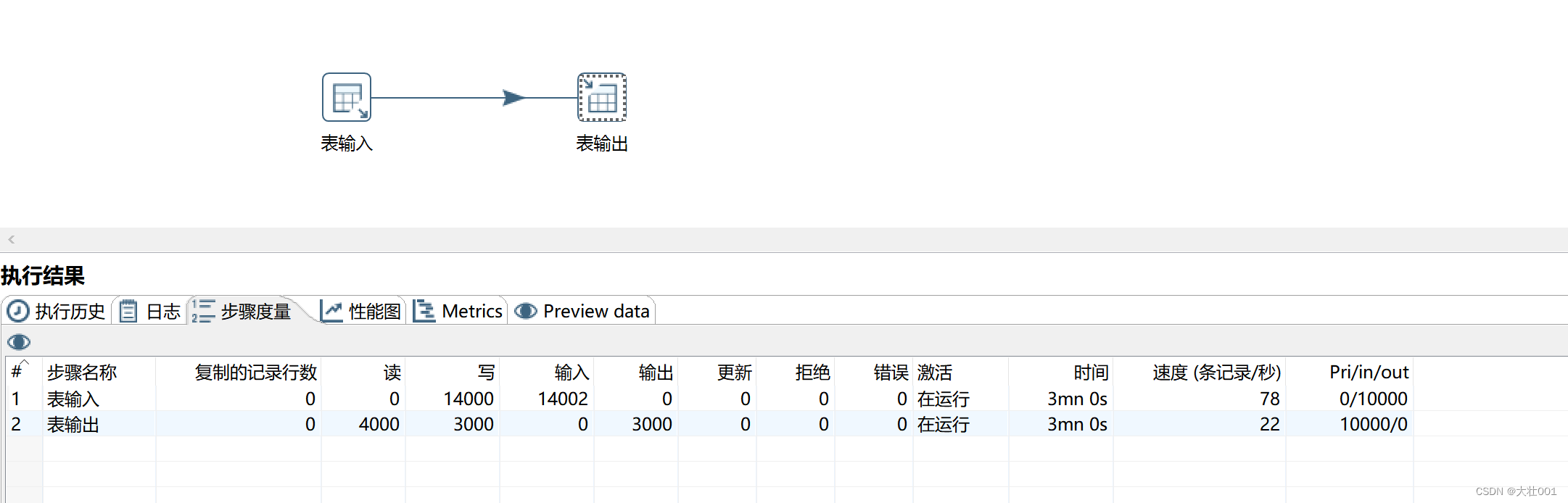
配置参数后:
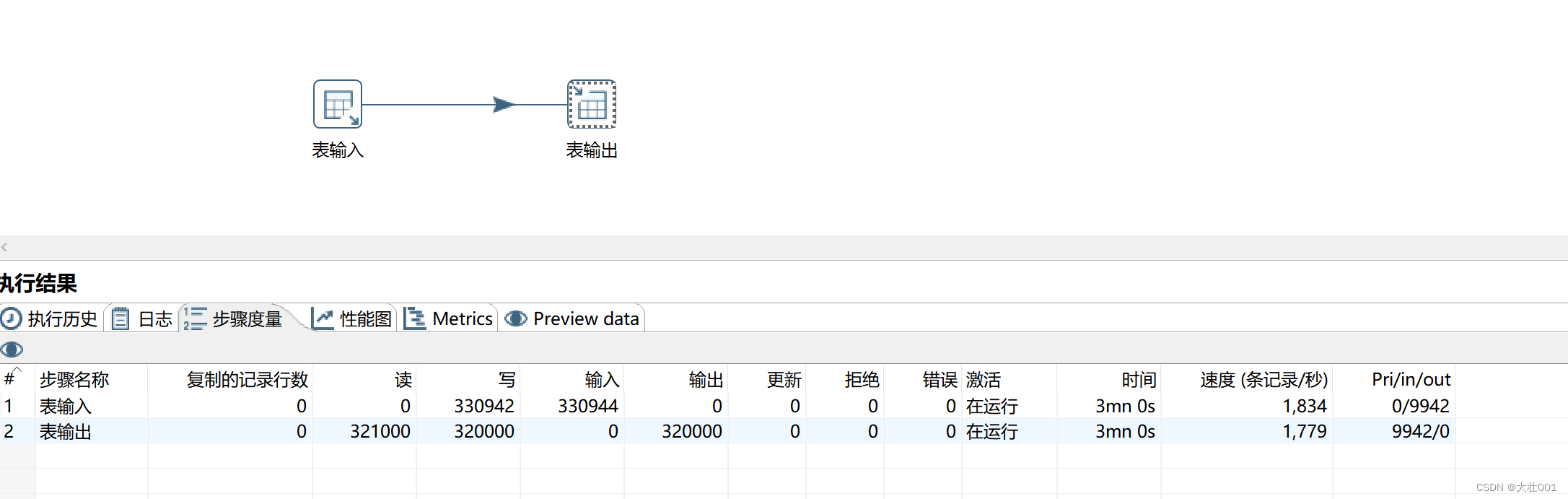
性能提升了80倍!
2、去掉DDL中的 primary key
在 etl 的过程中会用中间表来存放一些临时数据,这些中间表可以去掉 ddl中的 primary key,通过逻辑来保证唯一性,只在结果表中使用primary key。primary key会检查相关字段是否重复,从而降低插入速度。(下面的案例 读写字段多,且表输入sql很复杂,所以插入很慢)
测试结果如下:
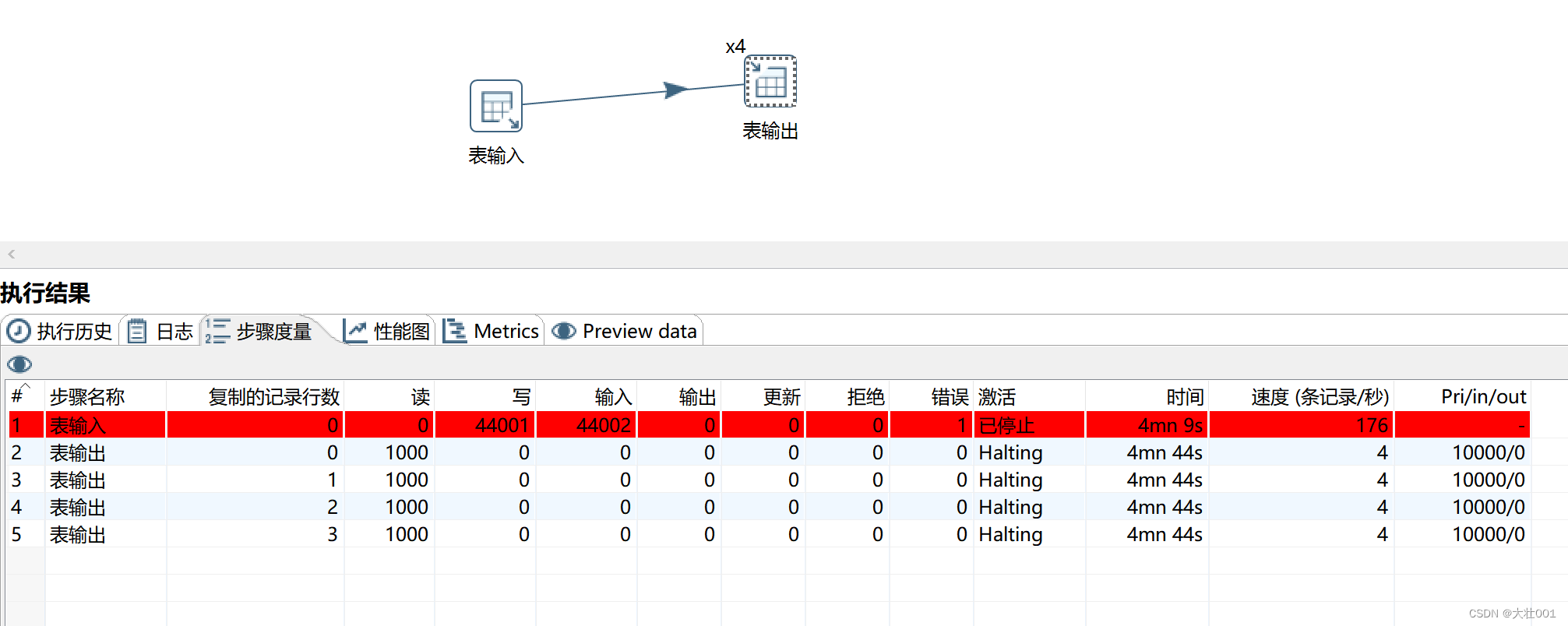
去掉目标表primary key 后
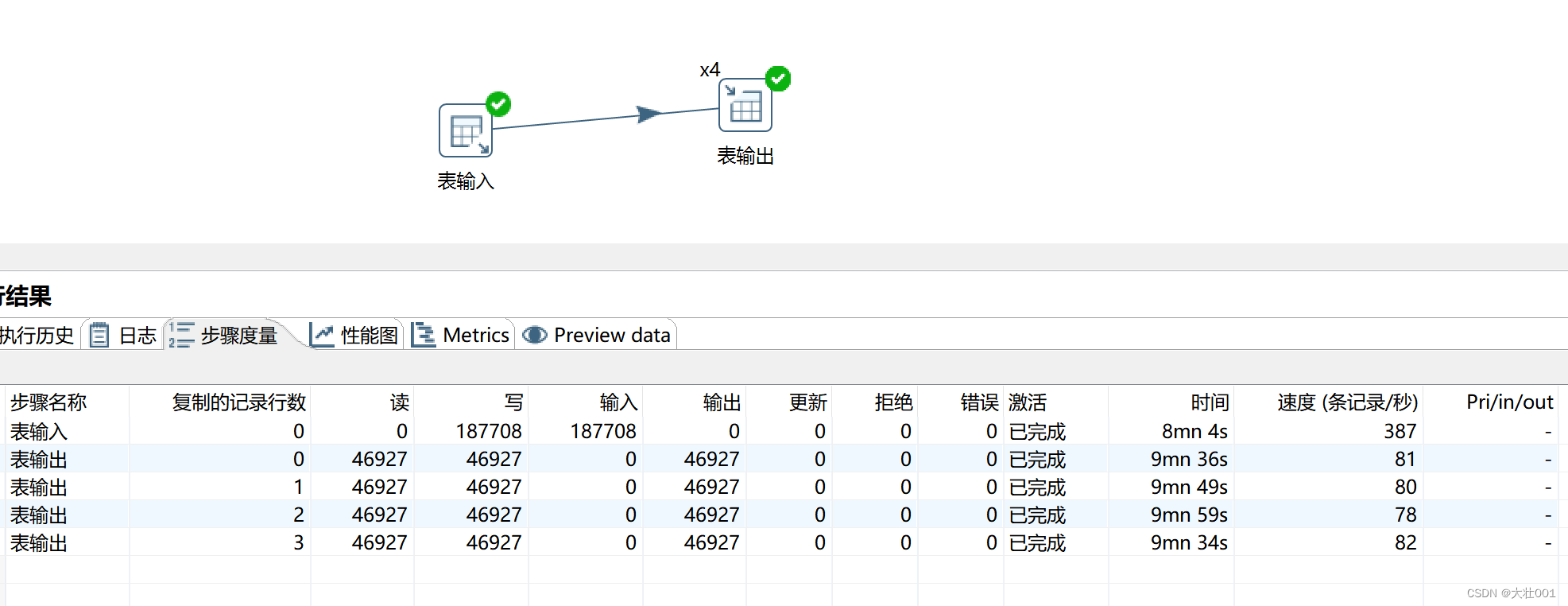
性能提升了20倍!
3、调整 输出组件数量
如果输出组件还是慢,可以复制多个输出。具体操作:输出组件 右键-改变开始复制的数量
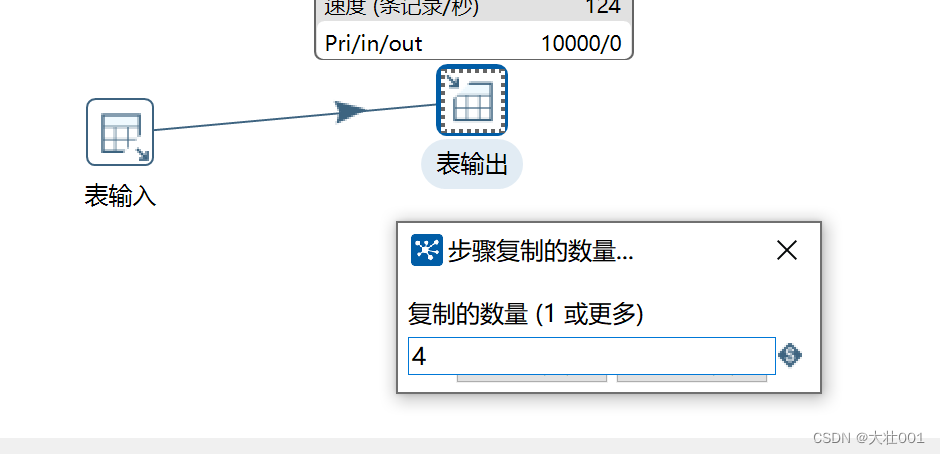
4、暂时关闭索引
维护索引数据需要大量额外的开销,因此全量数据插入前,可以先关掉索引,插入完毕再打开索引。
ALTER TABLE table_name DISABLE KEYS;
ALTER TABLE table_name ENABLE KEYS;
效果对比如下:
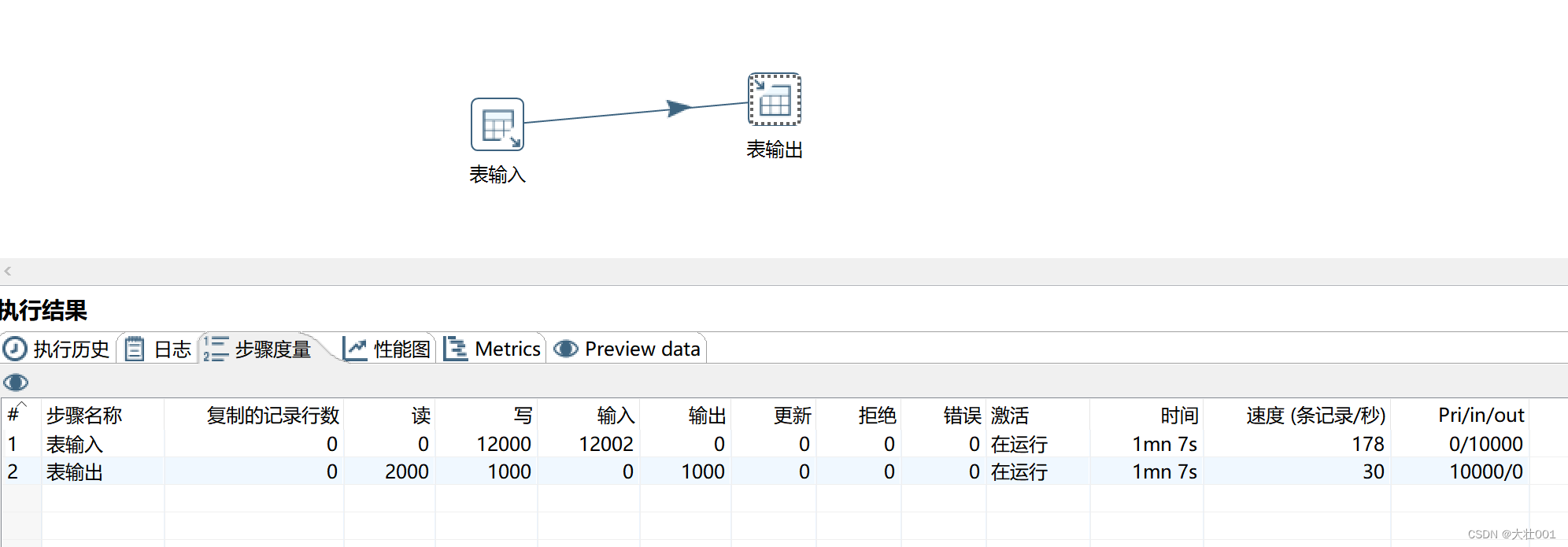
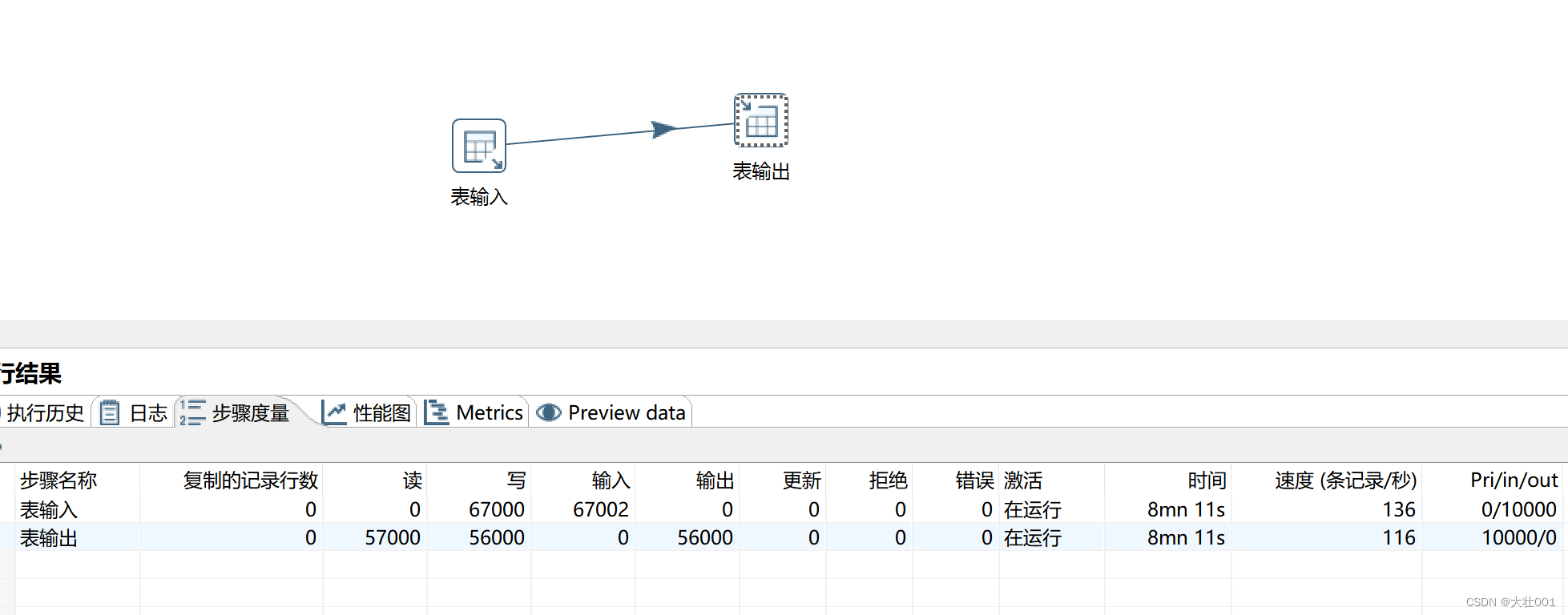
性能提高了4倍!
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!