
大数据基础原理与应用
第一章
1.大数据问题的定义和来源 (信息爆炸,三大技术支撑,数据产生方式变革)
答:信息量会急剧增加达到一定程度将会信息爆炸,主要有两大原因。在硬件方面由三个技术组成,软件方面由数据产生方式组成。
2)三大技术支持:存储设备容量不断增加;CPU处理能力大幅提升;网络宽带不断增加。
3)数据产生方式变革:运营式系统阶段,用户原创内容阶段,感知式系统阶段。
2.大数据问题的特点 (大数据的概念,4V)
答:特点:数据量大,类型繁多,处理速度快,价值密度低。
3.大数据应用四大层面的关键技术
答:1)采集与预处理:利用ETL工具将分布的、异构数据源中的数据,如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;也可以利用日志采集工具把实时采集的数据作为流计算系统的输入,进行实时处理分析;
2)存储和管理:利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理;
3)处理与分析:利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据;
4)安全和隐私保护:在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全。
4.大数据四大计算模式
答:1)批处理计算:针对大规模数据的批量处理,主要代表产品:MapReduce、Spark等;
2)流计算:针对流数据的实时计算Streams、Storm、S4、Puma、DStream、SuperMario;
3)图计算:针对大规模图结构数据的处理,Pregel、GraphX、Giraph、PowerGraph;
4)查询分析计算:大规模数据的存储管理和查询分析,SparkSQL、Hive、Cassandra、Impala等。
5.云计算的概念,物联网的概念,云计算与物联网之间的关系
答:云计算:云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种的IT资源。
物联网:物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、计算机、人员和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
关系:云计算为物联网提供海量数据存储能力,物联网为云计算技术提供了广阔的应用空间。
第三章
6.HDFS的本质:分布式文件系统
答:HDFS本质:分布式文件系统是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。把文件分布到存储到多个计算机节点上。
7.HDFS块存储的概念和好处
答:块存储的概念:默认块的大小为64MB,在HDFS中的文件都会被拆分成多个块,每个块作为单独的单元进行存储。
好处:支持大规模文件存储;适合数据备份;简化系统设计。
8.名称节点和数据节点的功能
答:名称节点:负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog。
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据;
FditLog记录了所有针对文件的创建、删除及重命名等操作。
数据节点:是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表。
9.第二名称节点的意义和工作原理
答:首先,可以完成EditLog与FsImage的合并操作,减小EditLog文件大小,缩短名称节点重启时间;其次,可以作为名称节点的“检查点”,保存名称节点中的元数据信息。
工作原理:1)首先,第二名称节点定期与名称节点通信,请求其停止Editlog文件且暂时将新的操作写入一个新的文件Edit.new上,第二名称节点把名称节点的两文件拉回本地再载入内存中;
2)中间:对二者进行合并操作,即在内存中逐条执行EditlLog使得FsImage保存最新,合并后将最新的FsImage发至名称节点,收到后将FsImage替换新的,同时EditLog.new也替换从而减小了EditLog的大小;
3)最后:由以上操作得知第二名称节点在此时相当于 “检查点”,周期性地备份元数据信息,当名称节点发生故障时,可用第二名称节点中记录的元数据进行恢复,但在第二名称节点合并得到的最新FsImage是合并时HDFS记录的元数据,所以还是会丢失部分数据,因此只能起到“检查点”作用。
10冗余存储的三大优点
答:加快数据传输速度;容易检查数据错误;保证数据的可靠性。
11.冗余复制因子为3时的数据存放策略
答:1)如果是在集群内发起写操作请求,则把第1个副本放置在发起写操作请求的数据节点上,实现就近写入数据。如果是在集群外发起写操作请求,则把集群内部挑选一台磁盘空间较为充足、CPU不太忙的数据节点,作为第1个副本的存放地。(满足需求则作为第一个副本存放地);
2)第2个副本会被放置在与第1个副本不同的机架的数据节点上;
3)第3个副本会被放置在与第1个副本相同的机架的其他节点上;
4)如果还有更多的副本,则继续从集群中随机选择数据节点进行存放。
12.数据的读取与复制策略
(注意:API 是用于构建应用程序软件的一组子程序定义,协议和工具。一般来说,这是一套明确定义的各种软件组件之间的通信方法。)
答:HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID,当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID。当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据。
HDFS的数据复制采用了流水线复制的策略。当客户端要往HDFS中写入一个文件时,这个文件会首先被写入本地,并被切分成若干个块,每个块的大小是由HDFS设定值来决定的。每个块都向HDFS集群中的名称节点发起写请求,名称节点会被首先写入列表中的第1个数据节点,同时把列表传给第1个数据节点,当第1个数据节点接收到4KB的数据的时候,写入本地,并且向列表中的第2个数据节点发起连接请求,把自己已经接收到的数据4KB数据和列表传给第2个数据节点。依次类推,列表中的多个数据节点形成一条数据复制的流水线。最后,当文件写入完成时,数据复制也同时完成。
13.HDFS中三种可能的错误和恢复方法
答:错误与恢复:名称节点:可把第二名称节点作为一种弥补措施,利用第二名称节点中的元数据信息进行系统恢复;
数据节点:定期检查时某数据块的副本数量小于冗余因子就会启动数据冗余复制;
数据:如果在读取时发现检验出错则客户端会请求另一数据节点读取该文件块,并向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。
第四章
14.HBASE与传统数据库的不同(数据类型,数据操作,存储模式,数据索引,数据维护,可伸缩性)
答:考选择题
数据类型(数据库采用关系模型。HBASE采用字符串)
数据操作(数据库有插入,删除,更新,查询;HBASE不存在复杂的表与表之间的关系,只有插入、查询、删除、清空)
存储模式:关系数据库(行存储)HBase(列存储)
数据索引:关系数据库(多个索引) HBase(只有一个索引-行键)
数据维护:关系数据库会替换旧值,HBase会保存数据旧的版本
可伸缩性:关系数据库难实现横向扩展,HBASE可灵活实现。
15.HBASE的数据模型概念、数据坐标(理解表、行、列族、列限定符、单元格与时间戳的作用,能够举例说明)

HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。
表:HBase 采用表来组织数据,表由行和列组成,列划分为若干个列祖。
行:每个HBase表都由若干行组成,每个行由行键标识。
列族:一个HBase表被分组成许多“列族”的集合,它是基本的访问控制单元。
列限定符:列族的数据通过列限定符来定位。
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。单元格:通过行、列族和列限定符确定一个单元格
-
16.HBASE概念视图与物理视图的不同,能够举例说明


物理视图在硬盘上。
17.HBASE列式存储的实例

18. HBASE的三层结构下客户端如何访问到数据。
答:客户端是在获得Region的存储位置信息后,直接从Region服务器上读取数据。
ZooKeeper文件 :记录ROOT表位置信息;
-ROOT-表(根数据表):记录META表 的Region位置,再通过ROOT表访问META表的信息
.META.表:记录用户数据表的Region位置,保存了HBASE所有用户数据表的Region位置
19.Region服务器工作原理(读写数据,MemStore、HLOG和StoreFile的定义,缓存刷新,StoreFile合并)
答 :Region内部管理了一系列Region对象和一个HLog文件,其中HLog是磁盘上面的记录文件,它记录着所有的更新操作。每个Region对象又是由多个Store组成的,每个Store对应了表中的一个列族的存储。每个Store又包含了一个MemStore和若干个StoreFile,其中,MemStore是在内存中的缓存,保存最近更新的数据;StoreFile是磁盘中的文件,这些文件都是B树结构,方便快速读书。StoreFile在底层的实现方式是HDFG文件系统的HFile,HFile的数据块通常采用压缩方式存储,压缩之后可以大大减少网络I/O的磁盘I/O。
详细理解:
1)用户读写数据的过程
当用户写入数据会被分配到(相应的)Region服务器去执行(操作)。(用户数据)首先被写入MemStore和HLog中,(当操作)写入HLog后,(commit())调用才会(将其)返回给客户端。
当用户读取数据(时)Region将首先访问MemStore缓存,如数据不缓存中则到磁盘(上面的)的StoreFile寻找。
2)缓存的刷新
MemStore缓存量有限,系统周期性调用Region.flushcache()(数据持久化)把MemStore内容写入磁盘的StoreFile(文件)中,清空缓存并在HLog文件中(写入一个)标记。(用来表示缓存中的内容已被写入StoreFile文件中)每次缓存刷新(操作)都在磁盘中生成(一个)新StoreFile(文件),所以Store中有多个StoreFile文件。
每个Region都有(一个自己的)HLog在启动时(每个)Region会检查自己的HLog文件,确认最近的一次执行缓存是否发生新的写入操作。如未更新则代表数据已被永久保存到磁盘StoreFile中,若发现更新则先写入新操作再刷新缓存写入磁盘StoreFile中。最后删除旧的HLog(文件),并开始为用户提供数据访问服务。
3)StoreFile的合并
每次MemStore缓存的刷新操作都会在磁盘中生成(一个)新的Storefile文件,系统中的每个Store则存在多个StoreFile文件。当需访问某个Store的某个值时则必须查找所有的StoreFile文件很耗时,因此调用Store.compact()可以将多个StoreFile合并成一个大文件。合并操作较耗费资源,所以只在StoreFile文件的数量达到一定才会触发合并操作。
第五章
20.NoSQL数据库三大特点
答:灵活的可扩展性、灵活的数据模型、与云计算紧密融合
21.关系型数据库不满足Web2.0应用的三大原因
答:1)无法满足海量数据的管理需求2)无法满足数据高并发的需求3)无法满足高可扩展性和高可用性的需求
22.关系型数据库的特性为何不适用于Web 2.0
答:1)Web2.0网站系统通常不要求严格的数据库事务
2)Web2.0并不要求严格的读写实时性3)Web2.0通常不包含大量负责的SQL查询
23.NoSQL数据库与关系型数据库比较(优势与劣势)
答:NoSQL数据库的明显优势在于,可以支持超大规模数据存储,其灵活性的数据模型可以很好地支持Web2.0的应用,具有强大的横向扩展能力;其劣势在于,缺乏数学理论基础,复制查询性能不高,一般都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
24.四大类型NOSQL数据库名称,数据模型特点,适用场合,优缺点。
答:键值数据库:键值对 内容缓存 扩展性好,灵活性好,大量写操作时性能高 无法存储结构化信息,条件查询效率较低
列族数据库:列族 分布式数据存储与管理 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 功能较少,大都不支持强事务一致性
文档数据库:版本化的文档 存储、索引并管理面向文档的数据或者类似的半结构化数据 性能好,灵活性高,复杂性低,数据结构灵活 缺乏统一的查询语法
图数据库:图结构 应用于大量复杂,互连接,低结构化的图结构场合 灵活性高,支持复杂的图算法,可用于构建复杂的关系图谱 复杂性高,只能支持一定的数据规模
25.CAP的定义
答:Consistent一致性:它是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的。
Available可用性: 它是指快速获取数据,且在确定的时间内返回操作结果。
Partition Tolerant分区容忍性: 它是指当出现网络分区的情况时,分离的系统也能够正常的运行。
26.CAP三种选择两种时的实现方法,不同选择的代表性产品
答:CA:MySQL、SQL Server、PostgreSQL。把所有与事务相关的内容都放到同一台机器上。
CP: Neo4j、BigTable、HBase。当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间无法对外提供服务。
AP: DYnamoDB、Riak、CouchDB、Cassandra。允许系统返回不一样的数据。
27.BASE的具体含义
答:基本含义:
基本可用:指分布式系统的一部分发生问题时,其他部分仍可正常使用,允许分区失败的情形出现。
软状态:“软状态”是与“硬状态”相对应的一种提法,软状态有滞后性,硬状态有一致性。
最终一致性:分为强一致性和弱一致性,主要在于高并发的数据访问下能否获取最新数据。
(注意:四性:
Atomic原子性:它是指事务必须是原子工作单元,对于其数据修改,要么全部执行,要么全部不执行。
Consistent一致性: 它是指事务在完成时,必须使所有的数据都保持一致状态。
Isolated隔离性: 它是指由并发事务所做的修改必须与任何其他并发事务所作的修改隔离。
Durable持久性: 它是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持。)
第七章
28.MapReduce与Hadoop的关系
答:MapReduce是分布式并行编程模型,Hadoop MapReduce是它的开源实现。
29.Map与Reduce函数的输入、输出与处理过程

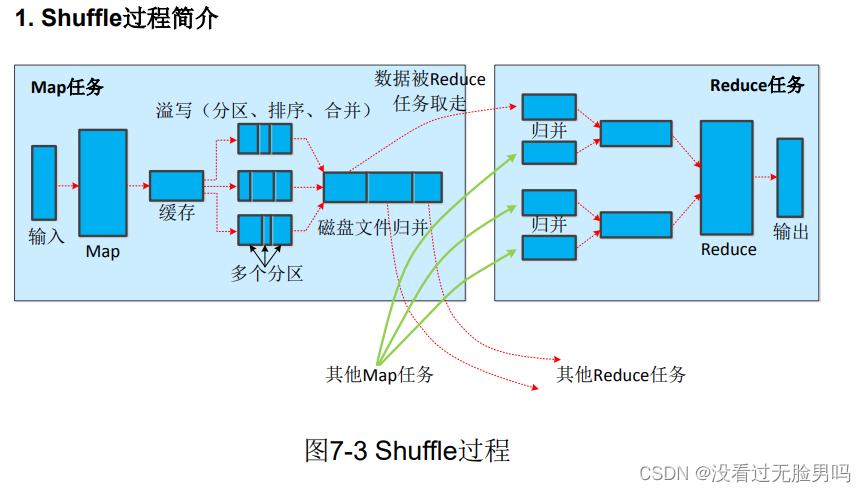
30.MapReduce基本工作流程 (各个执行阶段:Map,Shuffle,Reduce)

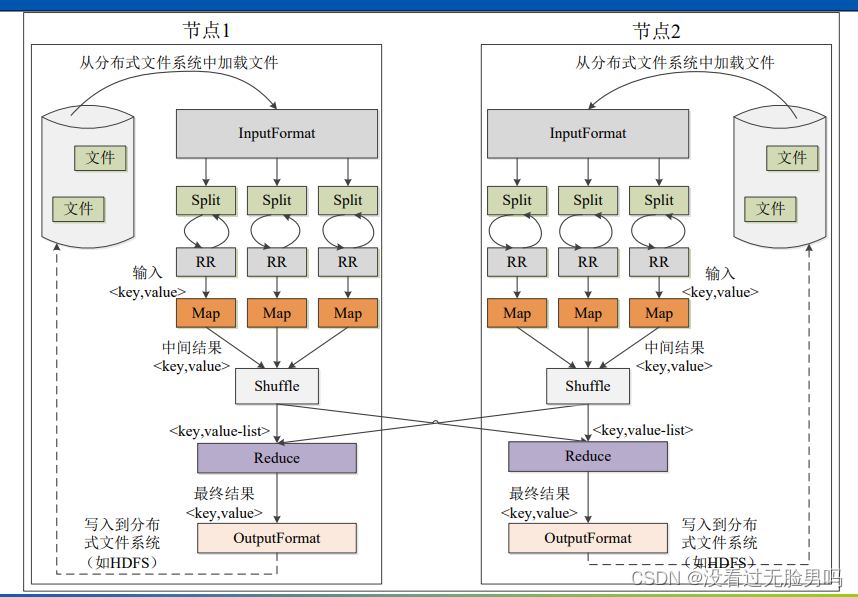
31.什么是“计算向数据靠拢”?为什么采用这一思想?
答:在一个集群中,只要有可能,MapReduce框架就会将Map程序就近地在HDFS数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少节点间的数据移动开销。
因为移动数据需要大量的网络传输开销,尤其是在大规模数据环境下。
所谓“计算向数据靠拢”就是将程序发到数据所在的地方,而不是把数据发送到程序所在的地方,因为移动数据需要大量的网络开销。
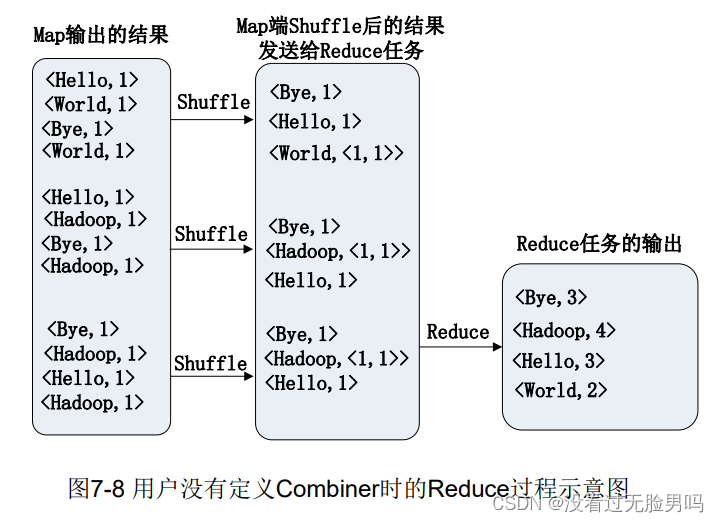
32.Combiner的作用(定义归并数据的合并)?使用combiner与不使用combiner时的MapReduce执行Wordcount的区别。
作用:Combiner可以给结果进行合并后再发送给Reduce任务,大大减少网络传输的数据量。
实现(本地key)归并,作用和Ruduce一样,但只用Reduce则会效率相对较低。

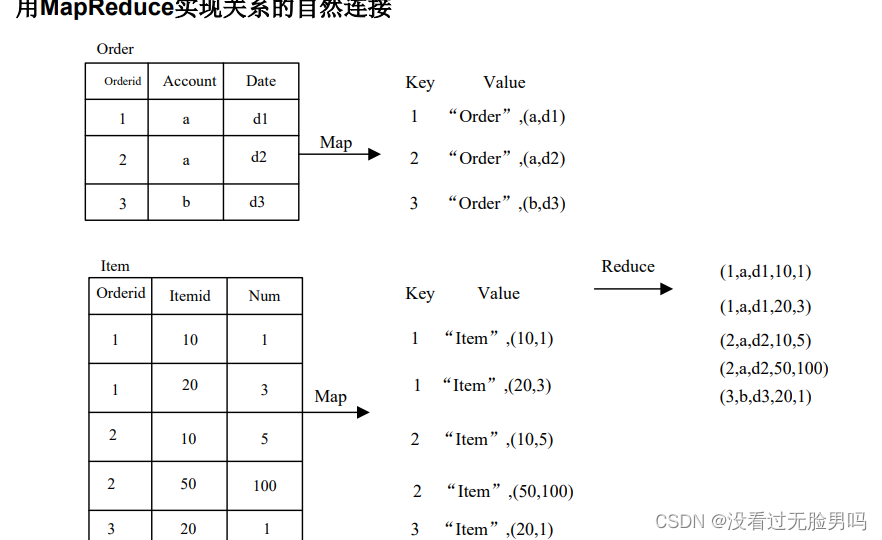
33.MapReduce的关系自然连接运算
第九章
34.Hadoop的缺陷与SPARK的优点。Spark优点的实现方式。
答:Hadoop的缺陷:表达能力有限、磁盘IO开销大、延迟高;
Spark优点:Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活。
Spark提供了内存计算,中间结果直接放到内存中,带来了更高的的迭代运算效率。
Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
35.Spark生态系统的组件与其功能。
答:Spark Core:包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面向批量数据处理。
Spark SQL:允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。
Spark Streaming:支持高吞吐量、可容错性处理的实时流数据处理。
Structure Streaming:使得使用者可以像编写批处理程序一样编写流处理程序,简化了使用者的使用难度。
MLib:提供常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等。
GraphX:能在海量的数据上自如地运行复杂的图算法。
36.RDD与DAG的基本概念
答:RDD:是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:(有向无环图的缩写)反映RDD之间的依赖关系。
37.RDD转换操作与行动操作的区别。
答:行动操作:在数据集上进行运算,返回计算值。接受RDD并返回RDD
转换操作:基于现有的数据集创建一个新的数据集。接受RDD但返回非RDD
38.RDD哪些操作属于转换操作,哪些操作属于行动操作(常用API表)?
答:Action是行动,Transformation是转换。

39.RDD惰性调用与DAG的构建。
答:RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成轨迹,并不会触发真正的计算。
DAG的构建:
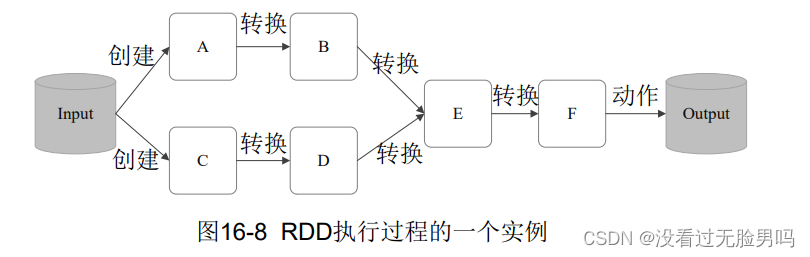
- 40.Spark宽依赖与窄依赖的定义,DAG阶段的划分
答:宽依赖表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
窄依赖表现为一个父RDD的分区对应一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区。

第十章
41.流数据的特点
答:
1)数据快速持续到达,潜在数据量也许是无穷无尽的。
2)数据来源众多,格式复制。
3)数据量大,但是不十分关注存储,一旦流数据中的某个元素经过处理,要么被丢弃,要么被归档存储。
4)注重数据的整体价值,不过分关注个别数据。
5)数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。传统数据42.处理与流数据处理的不同(批处理与流计算)
答:批处理可以在很充裕的时间内对海量的数据进行批量处理,计算得到有价值的信息。
流计算是当事件出现时应该立即进行处理,而不是缓存起来进行批量处理。
43..MapReduce为什么不适用于流计算
答:
1)切分成小的片段,虽然可以降低延迟,但是也增加了任务处理的附加开销,而且还要处理片段之间的依赖关系,因为一个片段可能需要用到前一个片段的计算结果。
2)需要对MapReduce进行改造以支持流式处理,Reduce阶段的结果不能直接输出,而是保存在内存中。这种做法大大增加MapReduce框架的复杂度,导致系统难以维护和扩展。
3)降低了用户程序的可伸缩性。
44.流计算一般处理流程
答:
数据实时采集阶段:
- Agent:主动采集数据,并把数据推送到Collector部分。
- Collector:接收到多个Agent的数据,并实现有序、可靠、高并发的转发。
- Store:存储Collector转发过来的数据
数据实时计算阶段对采集的数据进行实时的分析和计算。
实时查询服务:经由流计算框架得出的结果可供用户进行实时查询、展示或存储。
45.流计算的两大框架:Storm和Spark streaming
答:Storm:是一个免费、开源的分布式实时计算系统,对于实时计算的意义类似于Hadoop对批处理的意义,它可以简单、高效、可靠地处理流数据并支持多种编程语言。Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统。
特点:整合性、简易的API、可扩展性、容错性、可靠的消息处理、支持各种编程语言、快速部署,免费开源。
Spark streaming:是Spark的核心组件之一,为spark提供了可拓展性。高吞吐、容错的流计算能力。
基本原理:将实时输入数据以时间片为单位进行拆分,然后Spark引擎以类似批处理的方式处理每个时间片数据。
区别:Spark streaming无法实现毫秒级的流计算,而Storm可以实现。
相关文章
- 装在手机里的3D姿态估计,模型尺寸仅同类1/7,误差却只有5厘米
- 互联网行业如何“拆墙”?“安全”成焦点,乱码现象仍存在
- 华为张熙伟:聚集全产业链力量做生态,为世界贡献第二选择
- 谷歌Android反垄断上诉案开庭 律师称欧盟淡化苹果的存在
- 华为全联接2021:鲲鹏全面升级、深耕数字化,共同繁荣鲲鹏计算产业生态
- 共筑计算新生态 共赢数字新时代
- 为什么手机的换机频率很高,而电脑的换机频率很低呢?
- 你下载国家反诈中心APP了吗?
- 复旦的新衣再登Nature!穿在身上能为手机充电,可水洗可弯折
- 日本搞出奇妙充电屋,坐在任意位置都能隔空充电!|Nature子刊
- 若NVIDIA收购Arm失败 软银将得到13亿美元补偿
- 再遇坎坷 欧盟将对英伟达收购Arm进行调查
- 以色列科技企业研发AI工具,可识别员工是否真生病
- 数字人民币场景战白热化 专家称要尽快与第三层运营推广合作
- 英伟达 400 亿收购 ARM 计划,或将遭到英国政府否决
- Python+Appium实现APP自动化测试
- 如何创建Django项目
- 小程序开发环境搭建
- 安卓so ida动态调试
- 人人都可以使用的NFC技术 - 非手机数字化应用