
Flink任务失败,检查点失效:Exceeded checkpoint tolerable failure threshold.
项目场景:
最近实时平台flink任务频繁失败,报检查点方面的错误,最近集群的hdfs也经常报警:运行状况不良,不知道是否和该情况有关,我的状态后端位置是hdfs,废话不多说,干货搞起来~
问题描述
日志中报错如下:
2022-07-16 06:26:46,566 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Checkpoint 670223 of job 61103d713243c4a71befb436fa3f32ee expired before completing.
2022-07-16 06:26:46,571 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Trying to recover from a global failure.
org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold.
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleCheckpointException(CheckpointFailureManager.java:98) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:67) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1934) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1906) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:96) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:1990) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_201]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_201]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_201]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) ~[?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_201]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_201]
注意:
在报
Exceeded checkpoint tolerable failure threshold.错误的之前,是先报的是Checkpoint expired before completing.大概意思是检查点在完成前过期了。
解决方案:
这个错误也是头一次见,更让我好奇的是报这个错误的时间点大概差不多(每两天大概报一次,早晨6点多)。
最开始调整了检查点的频率(5s -> 10s)和任务重启间隔(5s -> 30s),以为频率太快了,但调整后并没能解决该问题。
后来又将jobmanager和taskmanager运行内存调大,但也没能解决…
通过查找flink检查点相关配置,发现了配置项TolerableCheckpointFailureNumber即可容忍检查点失败次数的配置,默认值为0表示不允许容忍任何检查点失败。
报的错就是超过检查点可容忍失败阈值,试试观察观察再说,因此在程序里加上了这个配置。
//设置可容忍的检查点失败数,默认值为0表示不允许容忍任何检查点失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
配置说明:
限制的是最大可容忍的连续失败checkpoint计数 continuousFailureCounter,例如将tolerableCheckpointFailureNumber设置成3,连续失败3次,continuousFailureCounter会累计到3,作业就会尝试重启。如果中间有一个checkpoint成功了,continuousFailureCounter 就会重置为零。
按之前的规律第二天任务就得报这个错误失败了,查看flink任务web界面,任务正常,但检查点确实失败过一次,也是大概那个时间失败的,失败原因和之前一样Checkpoint expired before completing.
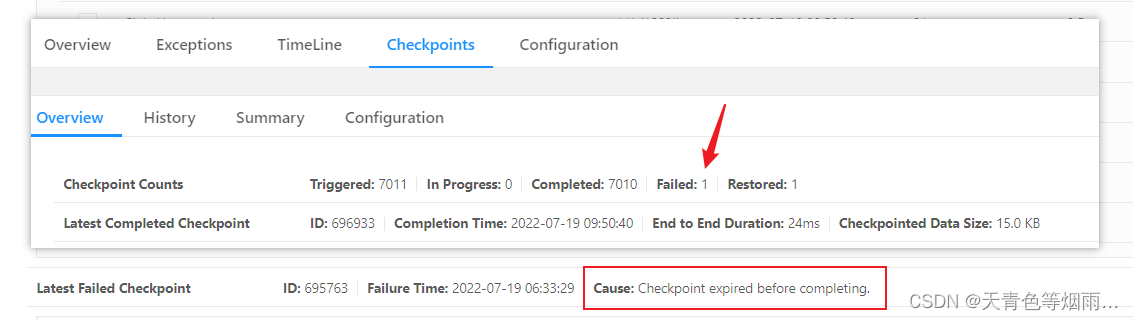
说明该配置对报错的解决有效,问题解决!!!
记得点赞收藏奥,后续遇到问题会持续更新,关注不迷路~
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击