
常见大数据面试题汇总带答案
大数据面试题汇总
牛客网刷sql题
redis
为什么快
首先,采用了多路复用io阻塞机制
然后,数据结构简单,操作节省时间
最后,运行在内存中,自然速度快
– 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
– 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
– 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
– 使用多路I/O复用模型,非阻塞IO;
– 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
flume
https://flume.liyifeng.org/
flink(大部分知识点写过的帖子里都有)
interval join不上的数据,怎么处理?怎么做数据修复?
需要匹配join不上的,用cogroup实现
(CoGroup算子:将两个数据流按照key进行group分组,并将数据流按key进行分区的处理,最终合成一个数据流(与join有区别,不管key有没有关联上,都可以合并成一个数据流),只能在window中使用)
或者用flinkSQL的左右外关联
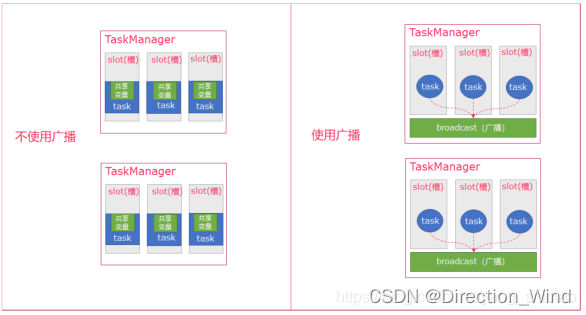
广播变量优势劣势
– 优势:Flink支持广播。可以将一份数据广播到一个TaskManager所有的task ,数据存储到内存中。这样可以减少大量的shuffle操作,而不需要多次传递给集群节点;
– 劣势:广播变量是要把dataset广播到内存中,所以广播的数据量不能太大,否则会出现OOM;广播变量的值不可修改,这样才能确保每个节点获取到的值都是一致的;
mr,java ,集群
hashSet底层去重原理
step1–>存入元素时,先比较要存入的元素的哈希值和集合中元素的哈希值是否一样
step2–>如果要存入的元素哈希值不同直接存入集合
step3–>如果存入元素的哈希值和集合元素的哈希值相同,再调用equals比较属性值,如果属性值相同,就不存入集合,属性值不相同,就存入集合
列存优势 lsm的存储结构和优势
行式存储可以看成是一个行的集合,其中每一行都要求对齐,哪怕某个字段为空(下图中的左半部分),而列式存储则可以看成一个列的集合(下图中的右半部分)。列式存储的优点很明显,主要有以下 4 点:
– 查询时可以只读取涉及的列(选择操作),并且列可以直接作为索引,非常高效,而行式存储则必须读入整行。
– 列式存储的投影操作非常高效。
– 在数据稀疏的情况下,压缩率比行式存储高很多,甚至可以考虑将相关的表进行预先连接,来完全避免投影操作。
– 因为可以直接作用于某一列上,聚合分析非常迅速。
– 行式存储一般擅长的是插入与更新操作,而列式存储一般适用于数据为只读的场景。对于结构化数据,列式存储并不陌生。因此,列式存储技术经常用于传统数据仓库中。
– lsm树 日志追加append的方式写入,会存几个副本 hbase就是,天生适合写多读少的场景, 会先写入 后合并,所以写入效率非常高,删除也是内存里先标记,后面异步合并操作才会真正的删除数据,效率高
mr的过程:
Mapreduce:
1、input 阶段:将数据源输入到 MapReduce 框架中
2、split 阶段:将大规模的数据源切片成许多小的数据集,然后对数据进行预处
理,处理成适合 map 任务输入的 key-value 形式。
3、map 阶段:对输入的 key-value 键值对进行处理,然后产生一系列的中间结
果。通常一个 split 分片对应一个 map 任务,有几个 split 就有几个 map 任务。
4、Shuffle 阶段:对 map 阶段产生的一系列 key-value 进行分区、排序、归并
等操作,然后处理成适合 reduce 任务输入的键值对形式。
5、reduce 阶段:提取所有相同的 key,并按用户的需求对 value 进行操作,最
后也是以 key-value 的形式输出结果。
6、output 阶段:进行一系列验证后,将 reduce 的输出结果上传到分布式文件
系统中。
6.3 Mapreduce 中 Shuffle 阶段?
shuffle 阶段分为四个步骤:依次为:分区,排序,规并,分组,其中前三个步 骤 在 map 阶段完成,最后一个步骤在 reduce 阶段完成。
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和
reduce 阶段。一般把从 Map 产生输出开始到 Reduce 取得数据作为输入之前的过程称 作 shuffle。
1Collect 阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,
保存的是 key/value,Partition 分区信息等。
2.Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入 本地
磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果 配置了 combiner,还
会将有相同分区号和 key 的数据进行排序。
3.MapTask 阶段的 Merge:把所有溢出的临时文件进行一次合并操作,以确保
一个 MapTask 最终只产生一个中间数据文件。
4.Copy 阶段:ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点 上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当 内存的缓冲区达 到一定的阀值的时候,就会将数据写到磁盘之上。
5.ReduceTask 阶段的 Merge:在 ReduceTask 远程复制数据的同时,会在后
台开启两个线程对内存到本地的数据文件进行合并操作。
6.Sort 阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶 段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的 最终整体有效性 即可。
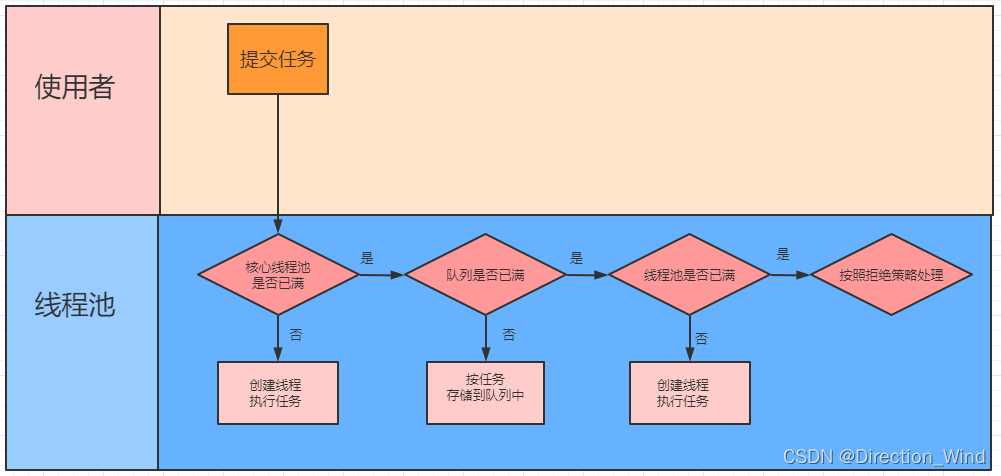
java线程池的实现原理
算法题
请你找出其中不含有重复字符的 最长子串 的长度?
public static int lengthOfLongestSubstring(String s) {
if (s == null || "".equals(s)) {
return 0;
}
int n = s.length();
Map<Character, Integer> map = new HashMap<>(16);
int maxLength = 0;
for (int i = 0,j = 0; j < n; j++) {
if (map.containsKey(s.charAt(j))) {
i = Math.max(map.get(s.charAt(j)), i);
}
maxLength = Math.max(maxLength, j - i + 1);
map.put(s.charAt(j), j + 1);
}
return maxLength;
}
public static int lengthOfLongestSubstring(String s) {
if (s == null || "".equals(s)) {
return 0;
}
List<Character> list = new ArrayList<>();
int n = s.length();
int maxLength = 0;
for (int i = 0; i < n; i++) {
int index = list.indexOf(s.charAt(i));
if (index == -1) {
list.add(s.charAt(i));
maxLength = Math.max(list.size(), maxLength);
} else {
for (int j = index; j >= 0; j--) {
list.remove(j);
}
list.add(s.charAt(i));
}
}
return maxLength;
}
微信红包
还是以10元10个红包为例,随机10个数,红包金额公式为:红包总额 * 随机数/随机数总和,假设10个随机数为[5,9,8,7,6,5,4,3,2,1],10个随机数总和为50,
第一个红包105/50,得1元。
第二个红包109/50,得1.8元。
第三个红包10*8/50,得1.6元。
以此类推。
写个快排
package Launcher;
import java.util.Arrays;
public class QuickSort {
public static int partition(int[] array, int low, int high) {
// 取最后一个元素作为中心元素
int pivot = array[high];
// 定义指向比中心元素大的指针,首先指向第一个元素
int pointer = low;
// 遍历数组中的所有元素,将比中心元素大的放在右边,比中心元素小的放在左边
for (int i = low; i < high; i++) {
if (array[i] <= pivot) {
// 将比中心元素小的元素和指针指向的元素交换位置
// 如果第一个元素比中心元素小,这里就是自己和自己交换位置,指针和索引都向下一位移动
// 如果元素比中心元素大,索引向下移动,指针指向这个较大的元素,直到找到比中心元素小的元素,并交换位置,指针向下移动
int temp = array[i];
array[i] = array[pointer];
array[pointer] = temp;
pointer++;
}
System.out.println(Arrays.toString(array));
}
// 将中心元素和指针指向的元素交换位置
int temp = array[pointer ];
array[pointer] = array[high];
array[high] = temp;
return pointer;
}
public static void quickSort(int[] array, int low, int high) {
if (low < high) {
// 获取划分子数组的位置
int position = partition(array, low, high);
// 左子数组递归调用
quickSort(array, low, position -1);
// 右子数组递归调用
quickSort(array, position + 1, high);
}
}
public static void main(String[] args) {
int[] array = {6,72,113,11,23};
quickSort(array, 0, array.length -1);
System.out.println("排序后的结果");
System.out.println(Arrays.toString(array));
}
}
kafka


kafka offset在一个名为 __consumer_offsets 的Topic中
kafka的ISR机制 副本同步机制 保证数据准确性
— 首先我们知道kafka 的数据是多副本的,某个topic的replication-factor为N且N大于1时,每个Partition都会有N个副本(Replica)。kafka的replica包含leader与follower。每个topic 下的每个分区下都有一个leader 和(N-1)个follower,
—每个follower 的数据都是同步leader的 这里需要注意 是follower 主动拉取leader 的数据
---- Replica的个数小于等于Broker的个数,也就是说,对于每个Partition而言,每个Broker上最多只会有一个Replica,因此可以使用Broker id 指定Partition的Replica
http@s://www.c@nblogs.com/@zzzzrrrr/p/13197390.html
Kafka 并不支持主写从读(读写分离),这是为什么呢?
1.kafka的follower与leader会有延时,不好解决
2.kafka写多读也多,不太适合
3.之后支持读写分离,为了解决跨数据中心消费的问题(就是机器不在一个地儿,带宽不够),才搞得读写分离。
kafka保证分区内顺序
设置一个分区
生产时指定分区;生产时用相同的key
维度建模分为哪几种?
https:/@/www.csdn.net/tags/NtT@aUg2sNTYx@MzMtYmxvZwO0O0OO0O0O.html
星型 : 事实表+维度
雪花 :事实表+维度-维度
星座:事实+维度+事实+维度
SQL高频面试题
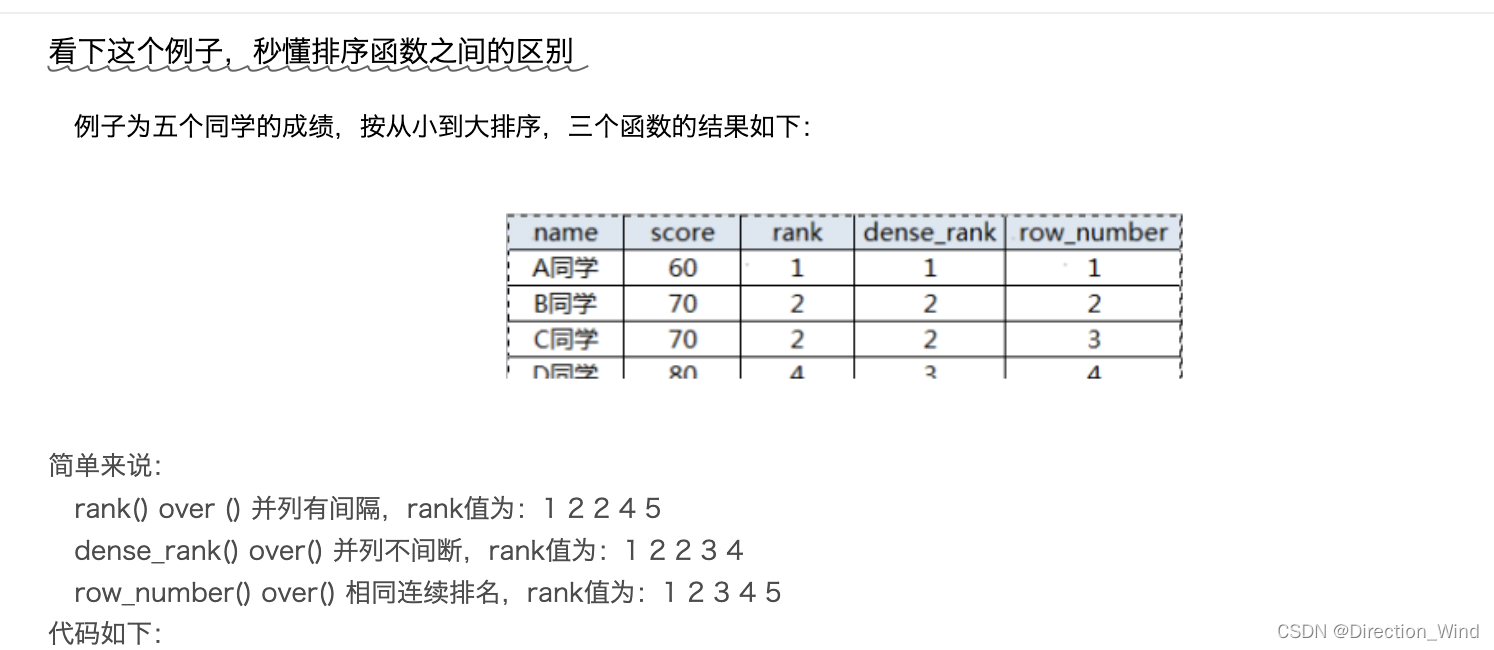
刷题网站:https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=268
sql面试题:求连续最大登录天数
连续签到领金币:https://www.nowcoder.com/practice/aef5adcef574468c82659e8911bb297f?tpId=268&tqId=2285347&ru=/exam/oj&qru=/ta/sql-factory-interview/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3DSQL%25E7%25AF%2587%26topicId%3D268
连续签到领金币 7天一周期 3天7天 多领 计算总领的金币
WITH t1 AS( -- t1表筛选出活动期间内的数据,并且为了防止一天有多次签到活动,distinct 去重
SELECT
DISTINCT uid,
DATE(in_time) dt,
DENSE_RANK() over(PARTITION BY uid ORDER BY DATE(in_time)) rn -- 编号
FROM
tb_user_log
WHERE
DATE(in_time) BETWEEN '2021-07-07' AND '2021-10-31' AND artical_id = 0 AND sign_in = 1
),
t2 AS (
SELECT
*,
DATE_SUB(dt,INTERVAL rn day) dt_tmp,
case DENSE_RANK() over(PARTITION BY DATE_SUB(dt,INTERVAL rn day),uid ORDER BY dt )%7 -- 再次编号
WHEN 3 THEN 3
WHEN 0 THEN 7
ELSE 1
END as day_coin -- 用户当天签到时应该获得的金币数
FROM
t1
)
SELECT
uid,DATE_FORMAT(dt,'%Y%m') `month`, sum(day_coin) coin -- 总金币数
FROM
t2
GROUP BY
uid,DATE_FORMAT(dt,'%Y%m')
ORDER BY
DATE_FORMAT(dt,'%Y%m'),uid;
sql:表名:test,字段(user_id1,user_id2,time)求这个表里,互相关注的用户有多少?
select
a.from_user,
a.to_user,
if( sum(1) over (partition by feature) > 1, 1, 0) as is_friend
from
(
select
a.from_user,
a.to_user,
if(from_user > to_user, concat(to_user, from_user), concat(from_user, to_user)) as feature
from table_relation
)a
hbase
写入过程
1)客户端处理阶段:客户端将用户的写入请求进行预处理,并根据集群元数据定位写入数据所在的RegionServer,将请求发送给对应的RegionServer。
2)Region写入阶段:RegionServer接收到写入请求之后将数据解析出来,首先写入WAL,再写入对应Region列簇的MemStore。
3)MemStore Flush阶段:当Region中MemStore容量超过一定阈值,系统会异步执行flush操作,将内存中的数据写入文件,形成HFile。
注意:用户写入请求在完成Region MemStore的写入之后就会返回成功。MemStore Flush是一个异步执行的过程。
RowKey设计原则
– 1.Rowkey的唯一原则
– 2.Rowkey的排序原则:HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点。
– 3.Rowkey的散列原则 也就是热点问题,经常与2冲突。
热点问题:
– 1.Reverse反转
针对固定长度的Rowkey反转后存储,这样可以使Rowkey中经常改变的部分放在最前面,可以有效的随机Rowkey。
– 2.Salt是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标。
– 3.rowkey做hash
高可用原理
jvm
1、JVM 主要组成部分
1、类加载器(ClassLoader)
2、运行时数据区(Runtime Data Area)
3、执行引擎(Execution Engine)
4、本地库接口(Native Interface)
2、组件的作用
首先,通过类加载器(ClassLoader)会把 Java 代码转换成字节码;
其次,运行时数据区(Runtime Data Area)再把字节码加载到内存中,而字节码文件只是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行;
于是,需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行;
最后,此过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能
mysql
联合索引机制:
– 遵守最左前缀匹配原则,检索数据时从联合索引的最左边开始匹配,直到遇到范围查询就停止匹配。
– 本质上联合索引也是一个 B+树,和单列索引不同的是,联合索引的键值不是一个,而是大于 1 个。建立联合索引的时候,B+树只能选择一个字段构建有序的树,默认是第一个字段,即最左边的字段,只有当第一个字段的值是相同的,才会按照第二个字段的值进行排序,即先确定第一个字段有序,才会匹配第二个字段
– 对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找
4.mysql的主从节点数据复制机制,可以开启主从双写吗?会有什么问题?
不可以,MySQL 默认采用异步复制方 双写会有重复吧,
本来读写分离,现在双写,就不分离了
sql递归
WITH CTE AS(
SELECT 部门ID,父级ID,部门名称,部门名称 AS 父级部门名称
FROM Company
WHERE 父级ID=-1
UNION ALL
SELECT c.部门ID,c.父级ID,c.部门名称,p.部门名称 AS 父级部门名称
FROM CTE P
INNER JOIN Company c ON p.部门ID=c.父级ID
)
SELECT 部门ID,父级ID,部门名称,父级部门名称
FROM CTE
hive
reduceByKey和groupByKey:
reduceByKey在分区内会进行预聚合,而后再将所有分区的数据按照关键字来分组聚合。
而groupByKey则不会先进行预聚合,它直接将所有分区的数据一起分组,如果要再进行聚合,则groupByKey还需要使用其他函数,比如sum()
大小表数据倾斜,用MAPjoin 原理 :
join本来是reduce进行关联查找,改成了map端进行关联查找
适用于大表join小表,使用DistributedCache机制将小表存储到各个Mapper进程所在机器的磁盘空间上,各个Mapper进程读取不同的大表分片,将分片中的每一条记录与小表中所有记录进行合并
合并后直接输出map结果即可得到最终结果。
注:不需要进行shuffle流程,也不需要reduce处理
distinct 和 group by有什么区别?在哪种情况下使用group by性能会更优?
--------仅仅从查询的作用角度看:
distinct 和 group by 都可以用来去重
不同之处,distinct 是针对要查询的全部字段去重,而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。
-------- 从性能角度看:
两者执行方式不同,distinct主要是对数据两两进行比较,需要遍历整个表。group by分组类似先建立索引再查索引,当数据量较大时,group by速度要优于distinct。
hive的执行流程
客户端提交到接口 ,解析 校验 优化 执行,mr任务关联元数据库
数据倾斜
map倾斜 :mapjoin
group by倾斜:
set hive.map.aggr=true;
第一个参数表示在 Map 端进行预聚。 因为传到数据量小了,所以效率高了,可以缓解数据倾斜问题。
set hive.groupby.skewindata=true;
设置参数后,会有两次基于不同 key 的 shuffle,且会有两个 reduce task: 第 一次 shuffle 使相同的 GroupBy Key 有可能被分发到不同的 Reduce 中减少倾斜;
第二次则保证相同的 GroupBy Key 被分布到同一个 Reduce 中,最后完成最
终的聚合操作。
小文件过多怎么办?
1合并小文件命令参数 set odps.merge.cross.paths=true;
SET odps.merge.smallfile.filesize.threshold = 64;
SET odps.merge.maxmerged.filesize.threshold = 512;
ALTER TABLE a MERGE SMALLFILES
2调整参数减少 Map 数量
3减少 Reduce 的数量
4使用 hadoop 的 archive 将小文件归档
sql 逻辑优化:
in、not in 性能有问题 、避免建临时表、 用 with as 的方式提高性能
避免 distinct, 一个 reduce ,可能出现数据倾斜的情况,用 group by 多个
reduce row_number 双重去重 避免数据倾斜
手动切分热值 、Join 操作提前到 Map 端执行 /*+ mapjoin(b) */ 设置参数 map、reduce、join 阶段 内存&并发 union all 一次查询多次写入 在套一层 多次读取 多次写盘
解释一下hive 的 skew join?
set hive.optimize.skewjoin = true;
开启后,在运行时,会对数据进行扫描并检测哪个key会出现倾斜,对于会倾斜的key,用map join做处理,不倾斜的key正常处理。
hive 几种join
内连接 ,左右外联 ,全连接 ,笛卡尔积,(mapjoin ,skew join 是开启配置 实现 shuffle前对数据分配,另一个是应对数据倾斜的)
hive 行转列列转行
多行转一列:一般用case when,再做一个group by 去掉0值。
一行转多列:lateral view
select t.gameId, singleTag
from (
select gameId, tags from gamepublish.knights_game where date=20181127 limit 20
) t LATERAL VIEW explode(t.tags) v as singleTag
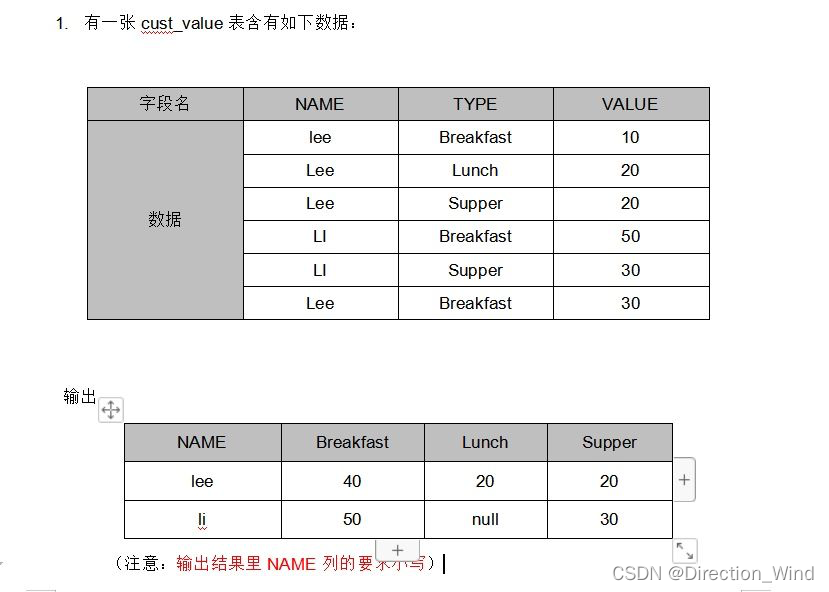
应该case when sum group by name
列转行:concat_ws
distinct 和 group by
在语义相同,有索引的情况下
group by和distinct都能使用索引,效率相同。
在语义相同,无索引的情况下:
distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by可能会进行排序,触发filesort,导致sql执行效率低下。
Hive的四种排序:
1.全局排序 order by(只有一个reduce,对所有数据进行排序) 只要使用 order by ,reduce只有一个。
2.sort by 内部有序
3.distribute by 分区字段 store by 排序字段
4.cluster by:当分区条件和排序条件相同使用cluster by .
5.group by:对检索的数据进行单纯的分组,一般和聚合函数一起使用。
6.partition by:用来辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
Hive的开窗函数:
over():over是用于数据的分区和排序,主要使用在聚合函数后边使用
row_number(): 对排序后的每行生成一个行号,且不存在重复的序号位
rank():排名函数
DENSE_RANK() 相同排序不跳序号位(允许并排次序):
LAG:落后N 个值 (默认落后1个值) 用于统计窗口内往上第n行值
LEAD:比LAG快N个值 用于统计窗口内往下第n行值
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
窗口函数与分析函数 应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
窗口函数与分析函数 区别:
窗口函数:对于每个组返回多行,
聚合函数:而聚合函数对于每个组只返回一行
java
LinkedeList和ArrayList的区别
- 1、数据结构不同
ArrayList是Array(动态数组)的数据结构,LinkedList是Link(链表)的数据结构。 - 2、效率不同
当随机访问List(get和set操作)时,ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
当对数据进行增加和删除的操作(add和remove操作)时,LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。【视频教程推荐:Java视频教程】 - 3、自由性不同
ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。 - 4、主要控件开销不同
ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储结点信息以及结点指针信息。
hdfs
在HDFS中,每一个文件块。都会有一条元数据用来唯一标识这个文件块的存在。而Fimage和edit.log这两个文件就是用来保存,处理这些元数据信息的文件
fsimage保存来最新的元数据检查点,包含来整个hdfs文件系统的全部目录和文件的信息。对于文件来讲包括了数据块描述信息,修改时间,访问时间等,对于目录老说包括修改时间,访问权限控制信息(目录所属用户,所在组)等。Fimage就是在某一时刻,整个hdfs的快照,就是这个时刻的hdfs上全部的文件块和目录,分别的状态,位于哪些个datanode,各自的权限,各自的副本个数。node
editlog主要是在Namenode已经启动状况下对hdfs进行的各类更新操做进行记录,hdfs客户端执行全部的写操做都会被记录到editlog中。客户端对hdfs全部的更新操做,好比说移动数据,或者删除数据,都会记录在editlog中。为了不editlog不断增大,secondary namenode 会周期性合并fsimage和deits 合并成新的fsimage新的操做记录会写入新的editlog中,这个周期能够本身设置(editlog到达必定大小或者定时)。blog
数据治理
数据治理 :
数据存储:空表、未管理的表、最近 90 天未访问表、生命周期很长、存储量占用 很大,但是没有下游表
数据计算:
- 1、冲突任务:多个任务写入同一张表
- 2、数据倾斜:产生数据倾斜的根本原因是:有少数伏羲实例处理的数据
量超过其它实例处理的数据量,导致少数实例的运行时长超过其它实例的平均运行时长,从
而导致整个任务的运行时间较长,造成任务延迟。 - 3、暴力扫描:如果在运行任务时未指定分区,会扫描大量数据。建议您
优化任务,减少数据的输入量。
数据采集: - 1、导入为空
- 2、持续导入一致 表数据不更新 3、同源导入 多个任务抽取一张表
相关文章
- 无代码的未来?
- 探索自然本源!谷歌2022年终总结第七弹:「生化环材」如何吃上机器学习红利?
- 一文通览自动驾驶三大主流芯片架构
- 国内外顶尖高校联合发布首个「新冠NLP数据集」METS-CoV|NeurIPS 2022
- 抖音超900万人在用的「卡通脸」特效技术揭秘
- 为什么所有GPT-3复现都失败了?使用ChatGPT你应该知道这些
- 开挖扩散模型小动作,生成图像几乎原版复制训练数据,隐私要暴露了
- 让大模型的训练和推理,比更快还更快!谷歌2022年终总结第四弹
- 九款日志采集&管理工具对比,选型必备!
- 存算一体技术是什么?发展史、优势、应用方向、主要介质
- 无损压缩鼻祖去世了,没有他就没有今天的Zip、PNG、MP3、PDF……
- ImageNet零样本准确率首次超过80%,地表最强开源CLIP模型更新
- 部署国产ChatGPT仅需6G显存!ChatYuan模型开放下载:业内首个功能型对话开源中文大模型
- 2022 AAAS Fellow名单出炉,杜克大学陈怡然、量子计算大牛Scott Aaronson等入选
- 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药
- 基于T5的两阶段的多任务Text-to-SQL预训练模型MIGA
- 谭济民、夏波等提出基因组构象预测模型及高通量计算遗传筛选方法
- 物理改变图像生成:扩散模型启发于热力学,比它速度快10倍的挑战者来自电动力学
- 登顶对话式语义解析国际权威榜单SParC和CoSQL,全新多轮对话表格知识预训练模型STAR解读
- 伯克利开源首个泊车场景下的高清数据集和预测模型,支持目标识别、轨迹预测