
kafka介绍(一)
0.0 什么是MQ
这个部分,需要简单的解答一下,其实MQ就是消息队列,那么本质上,就是一个 FIFO的队列数据结构。
因此,早期的使用方法,都是启动一个线程发送消息,写入消息队列,作为消息缓存,然后再启动一个线程消费消息。早期的windows程序(桌面程序)的设计方法。
后期,随着分布式微服务的快速发展,消息这个东西变成了组件,变成了中间件,直接分离出来使用了。
1.0 为什么需要Kafka
其实从需要kafka的角度,不如从需要MQ的角度来说.
从本质上来讲,是因为互联网发展太快,使用单体架构无疑会是的体量巨大。而微服务架构可以很好的解决这个问题,但是服务与服务之间会还是出现耦合、访问控制等问题。消息队列可以很好的满足这些需要。重要场景:
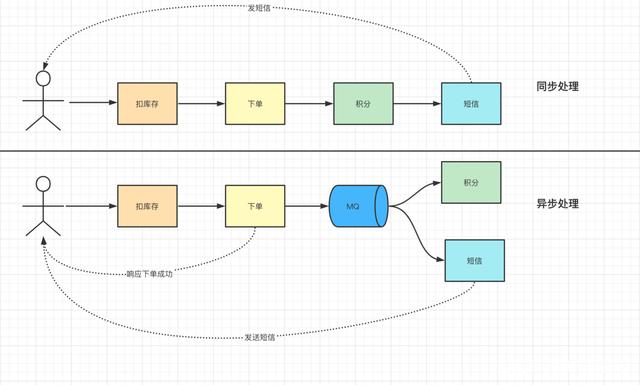
异步处理:
随着业务的不断扩展,通常会在原来的业务上不断地添加新的服务,这样会导致请求的链路非常长。比如,最开始电商,只需要处理下单,扣库存,后来处理积分,短信通知等等。再比如我们自己的业务,最开始只需要处理数据处理,后来需要监控数据分析,再后来需要输出报表清单。
而这些业务的共同特点就是及时性,要求不是那么的高。
所以只需要在下单结束的时候结束那个流程,把消息传给消息队列中就可以直接返回响应了。而且短信服务和积分服务可以并行的消费这条消息。这样响应的速度更快,用户体验更好;服务异步执行,系统整体latency(相对使用同步机制而言)也下降了
服务解耦
在采用API的模式下,可能会出现API格式的定义问题,对于任何API的改变,都有可能影响到原来的服务,尤其是在后续不断增加业务的情况下,就会出现这样的情况。所以这个时候,采用MQ就是最好的过程。
说明一下,服务的解耦,绝对不是简单的API调用问题,更多的可能是API调用的不确定性问题。比如调用深度的问题,也就是API聚合问题,还有就是
上面说的新加了短信服务和积分服务,现在又需要添加数据分析服务、以后可能又加一个策略服务等。可以发现订单的后续链路一直在增加,为了适配这些功能,就需要不断的修改订单服务,下游任何一个服务的接口改变都可能会影响到订单服务。
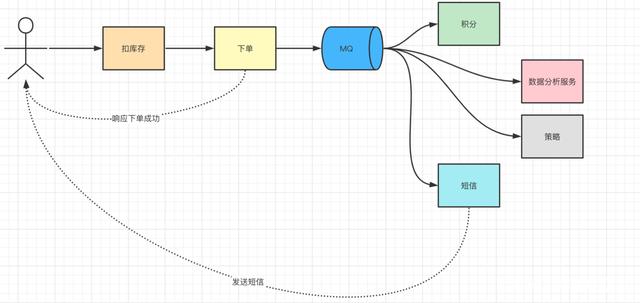
流量治理
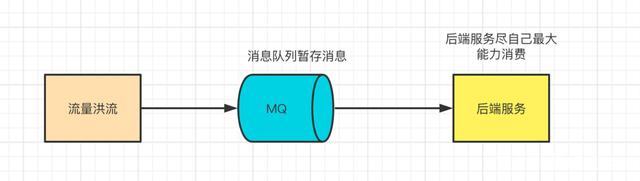
后端服务相对而言是比较脆弱的,因为业务较重,处理时间长。如果碰到高QPS情况,很容易顶不住。比如说题库数据写入到ES索引中,数据都是千万级别的。这个时候使用中间件来做一层缓冲,消息队列是个很不错的选择。
2.0 kafka介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
因为他是分布式的,所以可以很好的扩容,多副本保持,高吞吐量。这些决定了他的效率特别高。
3.0 使用场景
1、日志收集,可以用kafka进行日志收集,收集各个服务的日志,通过统一接口发送给不同的消费者。
2、用户追踪,可以使用kafka进行用户各种活动的最终,比如浏览页面,点击活动
3、运营指标,用于完成各种运营指标的监视
4、消息队列,解耦生产者和消费者,缓存消息
5、临时数据库,因为他可以实现多副本,保证了数据的不丢失,所以是可以作为副本实用的。
注意:随着新版本的kafka去掉了zookeeper,是的kafka可以单独使用,简化了复杂度,从而可以替代rabbitMQ的地步。
4.0 kafka版本
Apache自从接受LinkedIn捐赠Kafka之后,于2012年1月4日对外正式发布0.7这个版本,10年后的今天,Kafka已经陆续发布了46个版本 仔细研究发现Kafka目前总共演进了7个大版本,分别是0.7、0.8、0.9、0.10、0.11、1.0和2.0,比如2.0大版本中,期间历经了19个小版本,目前2.8.0去除对ZooKeeper的依赖算是一个大的更新
我们整理了一张图,用来阐述Kafka更新中有几个里程碑的一些特性,希望可以帮助大家更好的选择Kafka版本

5.0 架构说明
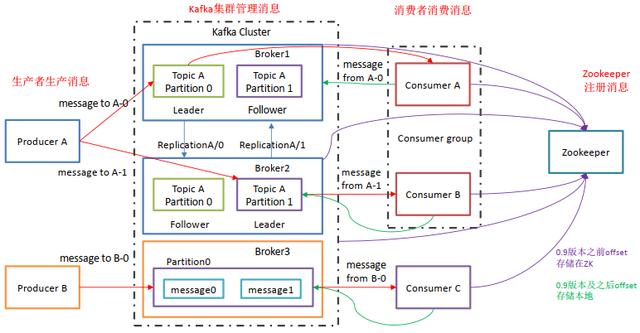
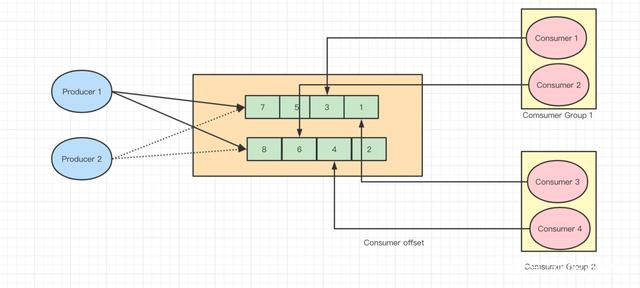
Producer : 消息生产者,就是向 Kafka发送数据 ;
Consumer : 消息消费者,从 Kafka broker 取消息的客户端;
Consumer Group (CG): 消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
Broker :经纪人 一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。
Topic : 话题,可以理解为一个队列, 生产者和消费者面向的都是一个 topic;
Partition: 为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;如果一个topic中的partition有5个,那么topic的并发度为5.
Replica: 副本(Replication),为保证集群中的某个节点发生故障时, 该节点上的 partition 数据不丢失,且 Kafka仍然能够继续工作, Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
Leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
Follower: 每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。 leader 发生故障时,某个 Follower 会成为新的 leader。
Offset:每个Consumer 消费的信息都会有自己的序号,我们称作当前队列的offset。即
消费点位标识消费到的位置。
相关文章
- Android studio 连接SQLite数据库 +创建数据库+创建数据库表
- 【Mac os系统】安装MySQL数据库
- 最简短最直白的解释:脏读、不可重复读、幻读,以及四种隔离级别的含义
- Mac上几款免费的MySql客户端
- 数据漂移问题及解决方案
- 数据问题排查思路
- MySQL 并行复制方案演进历史及原理分析
- Hive的4种排序
- 本地远程连接Oracle数据库的实现步骤
- flink-综合练习
- B+Tree树
- 数据库系统概论—概述
- 《数据治理行业实践白皮书》正式发布,开辟数据治理新范式(附下载)
- MySQL学习笔记-多表查询(下)
- MySQL数据库常用操作命令
- 推荐一款好用的数据一致性校验工具
- MySQL学习笔记-多表查询(上)
- TSBS 是什么?为什么时序数据库 TDengine 会选择它作为性能对比测试平台?
- ChunJun 1.16 Release版本即将发布,bug 捉虫活动邀您参与!
- redis(12)持久化操作-RDB