
冒泡排序算法详解之C语言版
一、算法原理
冒泡排序是一种常用的排序算法,属于稳定排序法,其时间复杂度为O(n^2)。
冒泡排序法的原理就是从前向后依次比较相邻两个元素的大小,大元素后沉,类似于水中的泡泡逐步上浮的过程,随着泡泡逐渐接近水面,水中压强逐渐减小,水泡体积逐渐增大,因此成为冒泡排序。
冒泡排序法包括多趟排序过程,每一趟排序都是从数组的第一个元素开始,以步长为1的增量依次对相邻的两个元素进行比较大小,反序的话则交换此二元素。
Demo:
假设有数据如下表所示:数组记为data

第一趟排序:
从下标为1的元素开始,向后依次比较相邻元素大小。首先比较data[1]和data[2],此时data[1] < data[2],因此不用交换元素。

之后比较data[2]和data[3]的大小,此时数据反序,需要交换
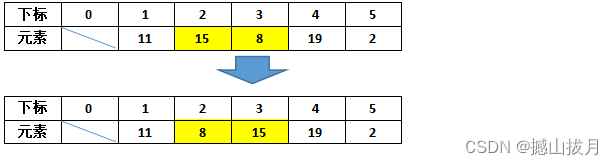
接着比较data[3]和data[4]的大小,此时数据不需要交换。

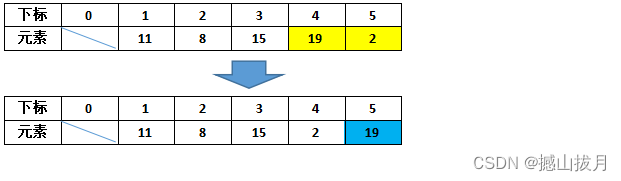
之后比较data[4]和data[5]的大小,此时数据需要交换。至此完成了第一趟冒泡排序过程,把数组中的最大元素冒泡到了最后的位置。
仔细想想,像不像水中的水泡冒泡的过程。
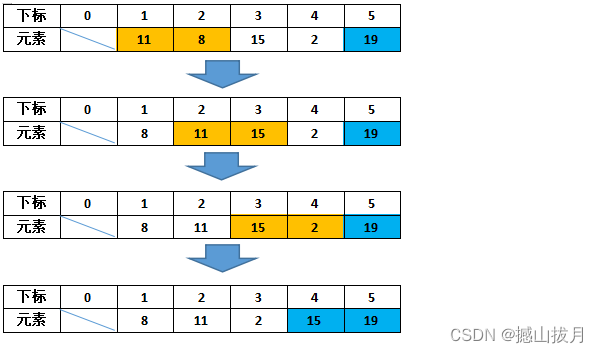
第二趟排序:
和第一趟排序一样,仍旧从数组的第一个元素开始向后依次进行比较大小。但是由于经过第一趟排序之后,最大的元素已经到了最后的位置,因此第二趟排序就截止到数组的倒数第二个位置。
第三趟排序:
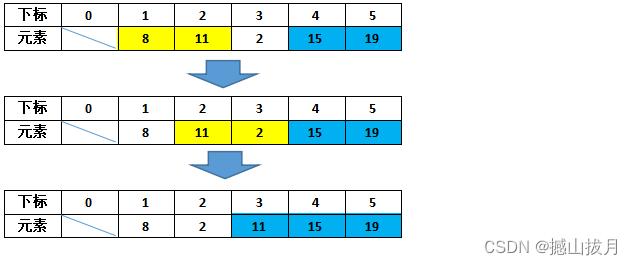
第四趟排序:
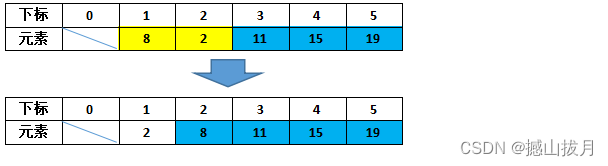
至此,该数组的冒泡排序结束。从上述演示过程可以看出,具有n个元素的数组使用冒泡排序法进行排序,需要进行n-1趟排序,每一趟排序都冒出剩余元素中的最大值,放到剩余元素的末尾。
二、冒泡排序算法流程图

三、冒泡排序算法之C程序
1.冒泡排序算法之C语言版
/*
功能:使用选择排序法对数组data进行排序
输入参数:
data[],已知数据散乱的数组
n,元素的个数
输出参数:
data[],排好序的数组
返回值:无
*/
void BubbleSort( int data[], int n )
{
int i, j, k, t;
for( i = 1; i <= n-1; i++ )
{
for( j = 1; j <= n-i; j++ )
{
if( data[j+1] < data[j] )
{
t = data[j+1];
data[j+1] = data[j];
data[j] = t;
}
}
}
}
2.完整的代码(仅供参考)
#include"stdio.h"
#define MaxLength 100
int TotalNum = 0;
void InputData( int &count, int arrt[] );
void BubbleSort( int data[], int n );
int main()
{
int count = 0, i, j;
int data[MaxLength];
InputData( count, data );
printf( "排序前的数据:" );
for( i = 1; i <= count; i++ )
{
printf( "%5d", data[i] );
}
printf( "
" );
BubbleSort( data, count );
return 0;
}
/*
功能:使用选择排序法对数组data进行排序
输入参数:
data[],已知数据散乱的数组
n,元素的个数
输出参数:
data[],排好序的数组
返回值:无
*/
void BubbleSort( int data[], int n )
{
int i, j, k, t;
for( i = 1; i <= n-1; i++ )
{
for( j = 1; j <= n-i; j++ )
{
if( data[j+1] < data[j] )
{
t = data[j+1];
data[j+1] = data[j];
data[j] = t;
}
}
//输出每一轮排序结果
printf( "第 %d 趟排序:", i );
for( k = 1; k <= n; k++ )
{
printf( "%5d", data[k] );
}
printf( "
" );
}
}
//从键盘读入一组整数存储到数组arr中,元素个数存储到count中
void InputData( int &count, int arrt[] )
{
int i = 0, data;
while( 1 )
{
printf( "input an integer(end of 65535)" );
scanf( "%d", &data );
if( data == 65535 )
{
break;
}
else
{
arrt[++i] = data;
}
}
count = i;
}
3.测试用例
测试用例一
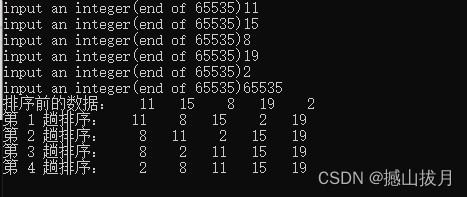
测试用例二
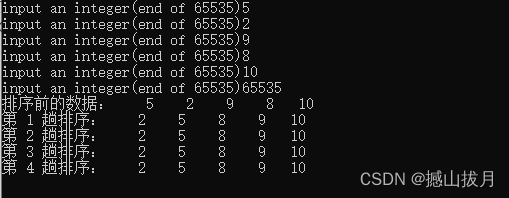
四、算法改进
上述算法,从第二个测试用例可以发现,经过第一趟排序之后,数据就已经处于排好序的状态了,因此不需要再进行后续的排序。为了解决此问题,提高算法的效率,可以对上述算法进行改进。改进的方法之一是引入提前结束排序标志flag,进行每一趟排序前将其值置为1,表示可以提前结束,之后进行相邻的两个元素比较大小时,如果需要交换数据,则将flag的值置为0,表示不能提前结束。这样当进行某一趟排序时,如果不需要交换数据的操作,则表示数据已经处于排好序的状态了,此时就可以提前结束排序。
具体算法实现如下:
void BubbleSort_V1( int data[], int n )
{
int i, j, k, t;
bool flag;//提前结束排序的标志,1表示提前结束
for( i = 1; i <= n-1; i++ )
{
flag = 1;
for( j = 1; j <= n-i; j++ )
{
if( data[j+1] < data[j] )
{
flag = 0;
t = data[j+1];
data[j+1] = data[j];
data[j] = t;
}
}
//输出每一轮排序结果
printf( "第 %d 趟排序:", i );
for( k = 1; k <= n; k++ )
{
printf( "%5d", data[k] );
}
printf( "
" );
if( flag == 1 )
{
break;
}
}
}
测试用例:
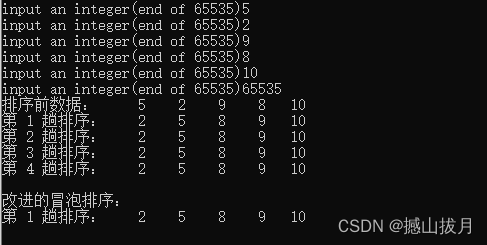
从测试用例可以发现,对于数组{11,15,8,19,2},元素个数n=5,需要进行n-1=4趟排序得到最终的排序结果。对于数组{5,2,9,8,10},元素个数n=5,只需要进行一趟排序就可以得到最终的排序结果。而改进的冒泡排序算法可以通过一趟排序即可以达成结果,因此其效率得到了提高。
相关文章
- 两年云原生落地实践在运维和开发侧踩过的六个坑
- UiPath业务自动化平台推出新功能以支持应用开发,扩展自动化用例
- 谷歌Recorder实现说话人自动标注,功能性与iOS语音备忘录再度拉大
- 受ChatGPT启发,10天完成能和数据聊天APP,回答问题不输本科生
- CARLA-GEAR: 为视觉模型对抗鲁棒性系统评估的数据生成器
- 真的这么丝滑吗?Hinton组提出基于大型全景掩码的实例分割框架,图像视频场景丝滑切换
- Gartner:到2023年全球低代码开发技术市场规模将增长20%
- 陶哲轩等人用编程方法,推翻了60年几何难题「周期性平铺猜想」
- 测量耐力也有算法了!仅需锻炼20分钟,就能知晓自己能跑多久
- 为什么开发人员离开谷歌
- 又一巨头宣布入局AIGC,一口气开源数个模型,还道出了它的变现之道
- 《Science》公布年度十大突破,AIGC、AI for science赢麻了
- 杀猪盘被AI大模型套路,倒贴520块钱,骗子破大防
- 关于运维,阿里云、字节、华科的专家如是说
- 行业 SaaS 微服务稳定性保障实战
- 提前在开发阶段暴露代码问题,携程Alchemy代码质量平台
- Twitter 抛弃开源
- 编辑部已成羊村,这几天幸亏有ChatGPT(doge)
- 首次不依赖生成模型,一句话让AI修图!
- 德勤发布2023年六大技术趋势:“信任”贯穿其中