
Java缓存面试题——Redis解决方案
文章目录
1、什么是缓存击穿?该如何解决
缓存击穿是指一个热点的Key在某个瞬间过期失效了,持续的并发请求在缓存获取不到数据后直接请求数据库的现象。
如何解决
- 使用互斥锁
在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先去设置一个互斥锁(比如Redis的SETNX),当获取到锁再进行load db的操作并回设缓存;否则就重试获取缓存的方法。
伪代码如下图:

- 永远不过期
- 不设置过期时间,就保证了不会出现热点key过期问题,也就是“物理”不过期。
- 我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建。
2、什么是缓存穿透?该如何解决
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
造成缓存穿透的基本原因有两个
- 自身业务代码或者数据出现问题。
- 一些恶意攻击、爬虫等造成大量空命中。
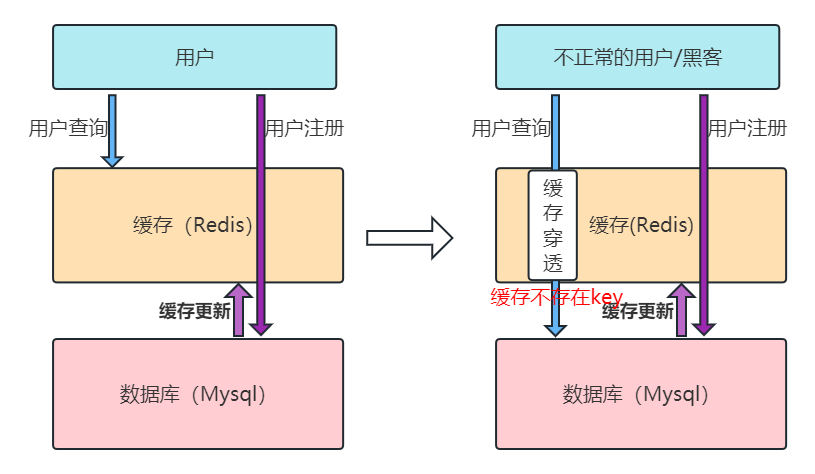
如何解决
- 缓存空对象
当存储层不命中,到数据库查发现也没有命中,那么设置空值到缓存层中。不过空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
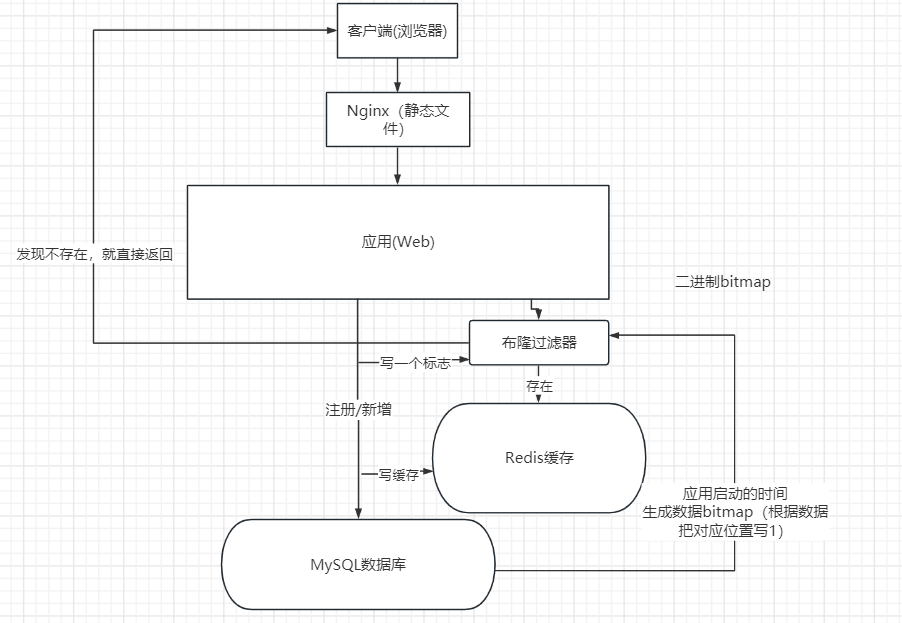
这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
3、什么是缓存雪崩?该如何解决
缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向存储。
缓存层由于某些原因不能提供服务,比如同一时间缓存数据大面积失效,所有的请求都会达到存储层,存储层的调用量会暴增,造成级联宕机的情况。
如何解决
- 保证缓存层服务高可用性。
- 依赖隔离组件为后端限流并降级。
- 将缓存失效时间分散开,降低缓存过期时间的重复率。
4、什么是BigKey?该如何解决
bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。
bigkey的危害
- 内存空间不均匀:在Redis Cluster中,bigkey 会造成节点的内存空间使用不均匀。
- 超时阻塞:由于Redis单线程的特性,操作bigkey比较耗时,也就意味着阻塞Redis可能性增大。
- 网络拥塞:每次获取bigkey产生的网络流量较大
假设一个bigkey为1MB,每秒访问量为1000,那么每秒产生1000MB 的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾。
发现bigkey
redis-cli --bigkeys可以命令统计bigkey的分布。
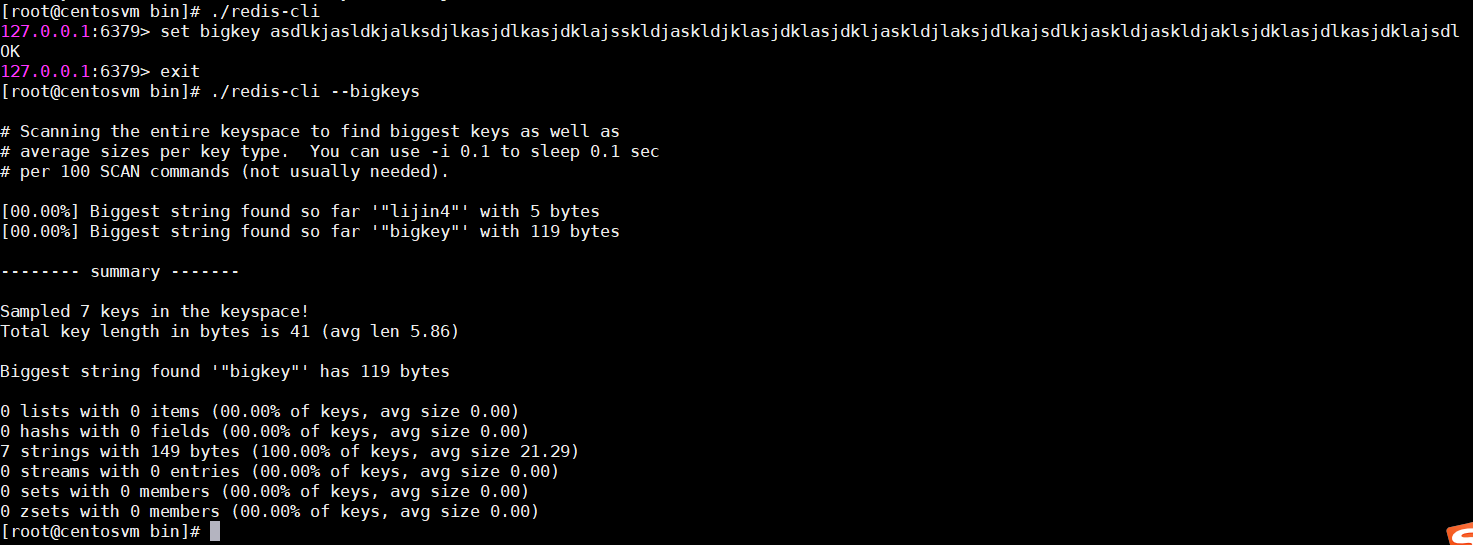
但是在生产环境中,开发和运维人员更希望自己可以定义bigkey的大小,而且更希望找到真正的bigkey都有哪些,这样才可以去定位、解决、优化问题。
判断一个key是否为bigkey,只需要执行debug object key查看serializedlength属性即可,它表示 key对应的value序列化之后的字节数。

解决bigkey
主要思路为拆分,对 big key 存储的数据 (big value)进行拆分,变成value1,value2… valueN等等。
例如big value 是个大list,可以拆成将list拆成。= list_1, list_2, list3, …listN
5、redis过期策略都有哪些?
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap)。交换会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样龟速的存取效率基本上等于不可用。
在生产环境中我们是不允许 Redis 出现交换行为的,为了限制最大使用内存,Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。
当实际内存超出 maxmemory 时,Redis 提供了几种可选策略(maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务。


noeviction : 不会继续服务写请求,DEL请求可以继续服务,读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
volatile-lru : 淘汰设置了过期时间的key,最少使用的key优先被淘汰。
volatile-ttl : 淘汰设置了过期时间的key,过期时间最接近的key优先被淘汰。
volatile-random : 淘汰设置了过期时间的key,随机选择一个key。
allkeys-lru : 所有的 key 中,最少使用的key优先被淘汰。
allkeys-random :所有的 key 中,淘汰随机的 key。
6、讲一讲Redis缓存的数据一致性问题和处理方案
只要使用到缓存,无论是本地内存做缓存还是使用 redis 做缓存,那么就会存在数据同步的问题。通常有以下几种同步方法:
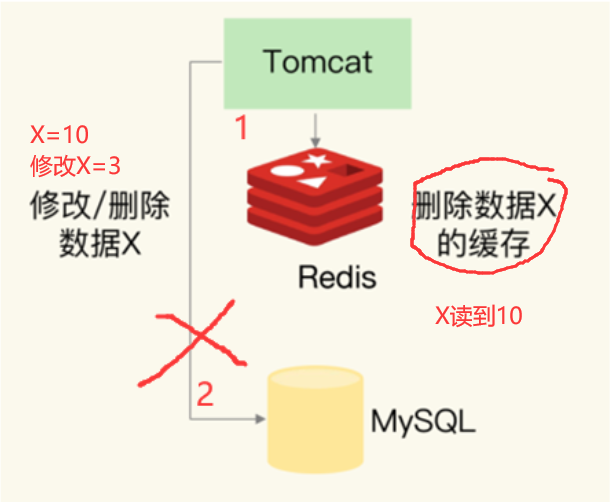
-
先更新缓存,再更新数据库
这个方案我们一般不考虑。这种方案如果不处理好,比如更新数据库失败之后没有回滚缓存,就会拿到错误的值。
-
先更新数据库,再更新缓存
这个方案也我们一般不考虑,原因跟第一个一样,数据库更新成功了,缓存更新失败,同样会出现数据不一致问题。同时还有以下问题:-
并发问题:同时有请求A和请求B进行更新操作,那么可能会出现:
(1)线程A更新了数据库
(2) 线程B更新了数据库
(3) 线程B更新了缓存
(4) 线程A更新了缓存这样会因为缓存更新顺序问题造成脏数据的产生。
-
业务场景问题:如果是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致:数据压根还没读到,缓存就被频繁的更新,浪费性能。
-
-
先删除缓存,后更新数据库
该方案也会出问题,具体出现的原因如下。

(1)此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)
(2) 请求 A 会先删除 Redis 中的数据,然后去数据库进行更新操作
(3)此时请求 B 看到 Redis 中的数据时空的,会去数据库中查询该值,但是此时请求 A 并没有更新成功,得到旧值补录到 Redis 中利用延时双删策略解决这一问题,是在更新数据库后睡眠一会,将B写的脏数据再次删除,伪代码如下:
redis.delKey(X) db.update(X) Thread.sleep(N) redis.delKey(X) -
先更新数据库,后删除缓存
这种方式,被称为Cache Aside Pattern,读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。
一般情况下我们可能会先用先更新DB,后删除缓存的操作。因为这种情况下缓存不一致性的情况只有可能是查询比删除慢的情况,而这种情况相对来说会少很多。
相关文章
- java程序员转正述职报告PPT
- Java学习笔记之继承与修饰符
- Java学习笔记之多态&抽象类&接口
- java中continue和break区别
- java中实现创建目录、创建文件的操作
- jenkins详细安装过程
- java计算两个时间相差多少小时
- 简单聊了一下 JVM 的基础知识
- Java中int和Integer值之间相互比较
- java应用性能监控的需求 系统的成本怎么样
- Java反射(通俗易懂)
- JAVA数据类型的强制转换
- 【2022最新Java面试宝典】—— Spring面试题(75道含答案)
- Java中两个字符串进行大小比较
- 并发编程系列之CountDownLatch用法简介
- 并发编程系列之CyclicBarrier用法简介
- 并发编程系列之Phaser用法简介
- 并发编程系列之Semaphore用法简介
- 并发编程系列之什么是并发协同?
- Java注解@JsonFormat