
IO多路复用原理(大白话,通俗易懂)
IO多路复用技术:
讲IO多路复用技术之前,我们得先了解NIO和BIO。
BIO
BIO (Block IO):同步阻塞IO。一般我们传统的JDK内置的Socket编程就是阻塞IO。其底层流程是:①创建socket接口,号为x,通过bind函数将接口号与端口号进行绑定,然后进行listn监听事件或者是read读事件,且会一直阻塞在该命令,直到有客户端连接或者发送数据。
缺点:如果是在单线程环境下,由于是阻塞地获取结果,只能有一个客户端连接。而如果是在多线程环境下,需要不断地新建线程来接收客户端,这样会浪费大量的空间。
NIO
NIO(NONBLOCK IO):同步非阻塞IO。非阻塞意味着程序无需等到结果,持续进行。其底层原理是:①同样与BIO相同创建Socket接口,号为x,绑定接口号与端口号,然后进行listen监听事件或者是读数据事件。②通过configureBlock函数传入参数false,底层命令为 fcntl(socket号,nonblock)将socket号标记为非阻塞。③循环执行。假如有客户端进行连接,则返回一个新的socket号,将新的socket号加入一个list中,然后遍历list中的元素查看有无发生read事件;如果没有客户端进行连接,则返回-1,代表没有客户端连接,再不断地循环。
缺点:需要遍历list中的每个集合查看有无监听的事件发生,时间复杂度为O(n),浪费CPU资源。
IO多路复用之select模型和poll模型
IO多路复用技术(select函数模型和poll函数模型):进程通过告诉多路复用器(内核)(也就是select函数和poll函数)所有的socket号,多路复用器再去获取每一个socket的状态,当程序获取到某个socket号有事件发生了,则去该socket号上进行处理对应的事件,read事件或者是recived事件。(补充select函数与poll函数的区别是,前者底层是数组,所以有最大连接数的限制,后者是链表,无最大连接数的限制)
缺点:①同样与NIO相同,需要遍历所有socket,O(N)复杂度。②重复传递数据。因为内核是无状态的,每次都要根据进程不断重复从用户态向内核态传递所有的socket号去遍历每一个socket,获取它们的状态。浪费资源与效率,可以使用一个记事本记录每个socket的监听事件。
IO多路复用之epoll模型
IO多路复用技术(epoll函数模型):epoll函数模型主要是调用了三个函数:epoll_create() , epoll_ctl() , epoll_wait();
底层流程:①通过epoll_create() 函数创建一个文件,返回一个文件描述符(Linus系统一切对象皆为文件)fd ② 创建socket接口号4,绑定socket号与端口号,监听事件,标记为非阻塞。通过epoll_ctl() 函数将该socket号 以及 需要监听的事件(如listen事件)写入fd中。③循环调用epoll_wait() 函数进行监听,返回已经就绪事件序列的长度(返回0则说明无状态,大于0则说明有n个事件已就绪)。例如如果有客户端进行连接,则,再调用accept()函数与4号socket进行连接,连接后返回一个新的socket号,且需要监听读事件,则再通过epoll_ctl()将新的socket号以及对应的事件(如read读事件)写入fd中,epoll_wait()进行监听。循环往复。
优点:不需要再遍历所有的socket号来获取每一个socket的状态,只需要管理活跃的连接。即监听在通过epoll_create()创建的文件中注册的socket号以及对应的事件。只有产生就绪事件,才会处理,所以操作都是有效的,为O(1).
补充:众所周知,设备(进程)是通过中断机制来请求CPU进行IO处理。使用epoll模型能加快CPU的处理效率。如网卡想通过IO来向系统传输一个数据,就通过中断获取CPU时间片,将该数据放置就绪事件序列中,等待CPU下一次进行epoll_wait()即可获取到对应数据,无需再通过往fd中注册socket号对应的事件等等。
epoll函数的边缘触发与水平触发的区别:
边缘触发:当文件描述符关联的读内核缓冲区发生变化时候,才发出可读信号进行通知
水平触发:只要文件描述符关联的读内核缓冲区非空,有数据可以读取,就一直发出可读信号进行通知
举个例子:
1.读缓冲区刚开始是空的
2.读缓冲区写入2KB数据
3.水平触发和边缘触发模式此时都会发出可读信号
4.收到信号通知后,读取了1kb的数据,读缓冲区还剩余1KB数据
5.水平触发会再次进行通知,而边缘触发不会再进行通知
因为边缘触发对于一次就绪事件只会触发一次,所以需要一次性的把缓冲区的数据读完为止,也就是一直读,直到读到缓冲区为空为止,因为这一点,边缘触发需要设置文件句柄为非阻塞。
但是,还没完,epoll模型(selector模型)还有不足,就是如果当epoll_wait()方法返回了10w个就绪事件,就需要等待这10w个就绪事件处理完成,才能继续下面的命令,去响应新的事件,这样就容易让新的事件超时。因此,提出了Reactor模型。
Reactor模型
我们可以通过更多的处理器和更多的线程来更快地处理事件。所以,提出了主从Reactor多线程模型(1个主Reactor+多个从Reactor+线程池)。

主Reactor只会进行响应客户端连接的事件,即accept事件,其余的事件交给剩下的从Reactor进行处理,进行了解耦。且由于我们的CPU一般是多核的,可以利用多线程来加快事件的处理速度。Nginx和Redis都是基于Reactor模型来实现在单线程的环境下实现与多个客户端并发交互。
Redis的IO多路复用模型:

(该图片引用来自有盐先生的文章)
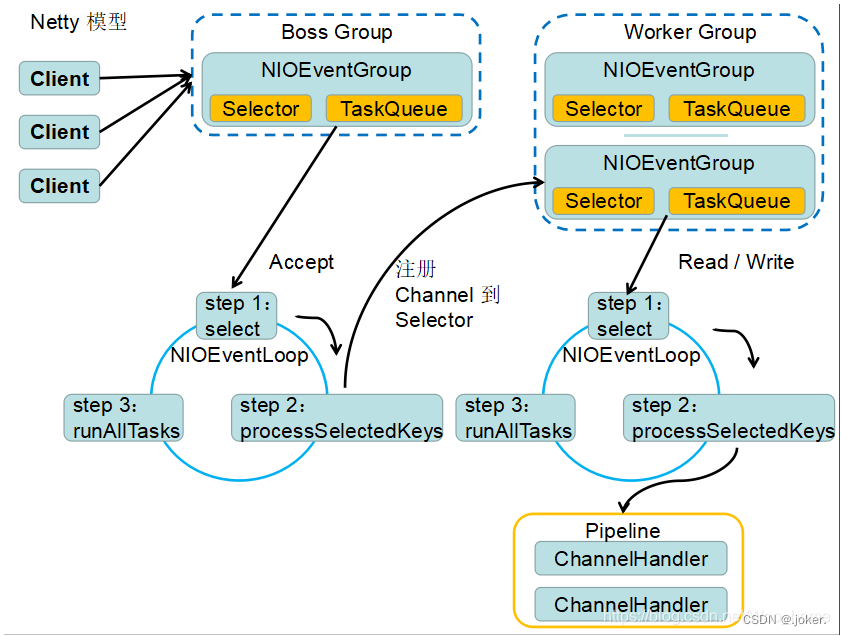
Netty的多路复用模型:(可以看出来是有多个Selector的,所以是基于多线程的)
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!