
【C++】string类的使用
目录
4.1、push_back、append、operator+=
4.6、find_first_of 与 find_last_of
一、标准库中的string类
string类是由模板 basic_string 显示实例化为 char 类型得到的类,并用关键字 typedef 命名为 string 。

当模板参数是 char 时,类名为 string ,与之相对的,还有其他各种各样由模板 basic_string 显示实例化的到的类名,比如:wstring、u16string、u32string等
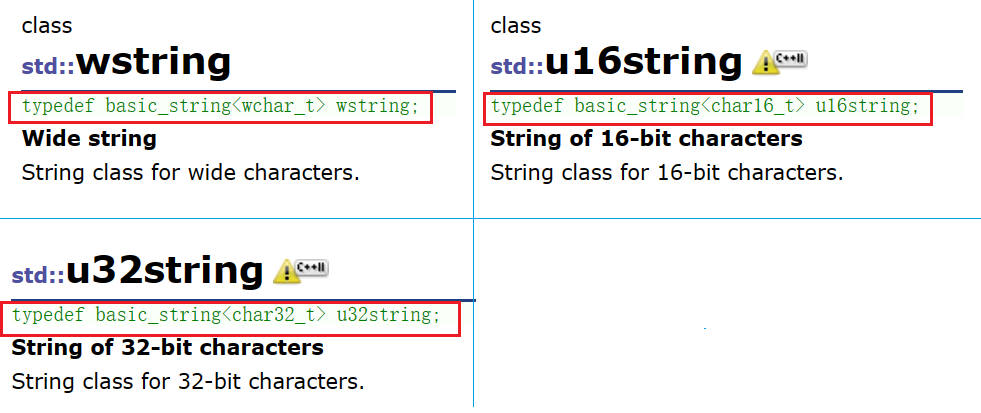
wstring 类管理的是 wchar_t 类型的字符,一个字符占据 2 个字节。
u16string 类管理的是 char16_t 类型的字符,一个字符占据 2 个字节。
u32string 类管理的是 char32_t 类型的字符,一个字符占据 4 个字节。
之所以要区分出这么多字符类,是为了满足各种各样不同的需求,比如编码的需求。
以 ascll 码为例,ascll码的出现是为了更好的表示英文,算上26个字母、10个数字以及各种各样的符号、控制字符等等,只需要 128 个字符的映射表就能满足几乎所有的表示需求。
但是对于中文、甚至是更加复杂的文字而言,128个字符的映射表就已经没有办法满足需求了,就需要更多字符的映射表,自然也需要占据更多字节大小的空间。
为了更好的满足这一需求,就出现了另一个编码规则:Unicode,即统一码。统一码又分为 3 种,分别为 UTF-8、UTF-16、UTF-32。
UTF-8兼容ascll码,对不同范围的字符使用不同长度的编码,也是我们最常用的编码方式。
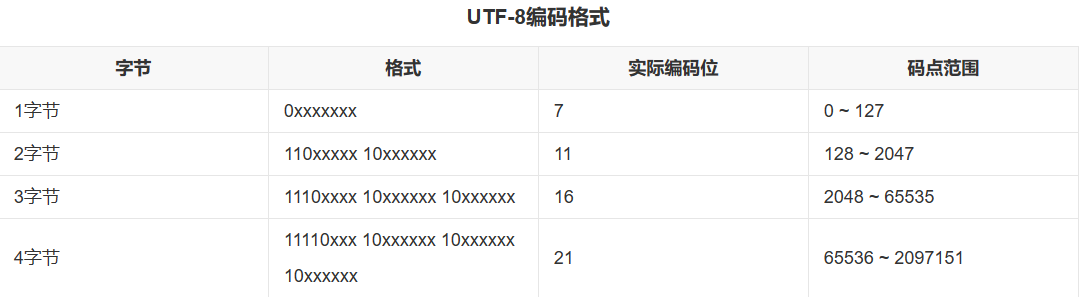
对于0x00-0x7F之间的字符,UTF-8编码与ascll编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。统一码的最大码位0x10FFFF也只有21位。UTF-8 编码以二进制数字的前缀来区分一个字符占据几个字节。
其中类 string 所对应的编码方式就是 UFT-8 。

我们来举个例子具体说明一下:
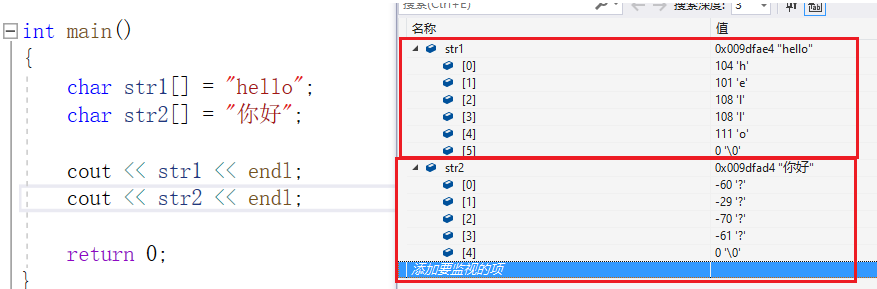
str1 中存储的是英文字母,使用 ascll 码即可表示(一个字符占据一个字节),例如 'h' 的值为十进制 104 ,换算到八位二进制为 01101000 ,前缀为零。
str2 中存储的是中文字符,一个字符占据两个字节,所以这两个字节的二进制数前缀分别为 110 与 10。转换成十进制表现为两个负数。两个中文字符就是四个字节,加上最后的 '�' 为五个字节大小。
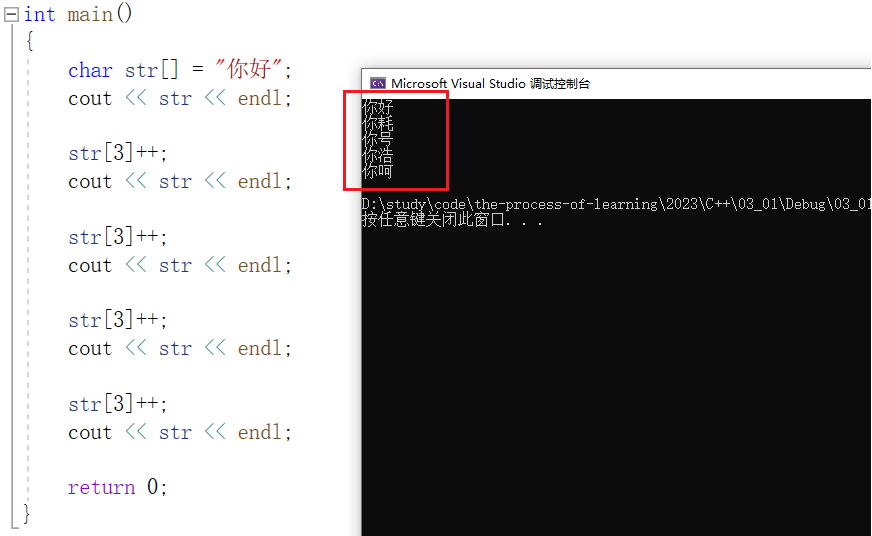
通过更改中文字符的数值,我们可以观察到中文字符编码的规律是把同音字编在一起的:
二、string类的常用接口
1、string类对象的常见构造
| (constructor)函数名称 | 功能说明 |
| string() | 构造空的string类对象,即空字符串 |
| string(const char* s) | 用C-string来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string& s) | 拷贝构造函数 |
| string (const string& str, size_t pos, size_t len = npos) | 拷贝从字符串第 pos 个字符开始向后的 npos 个字符 |
例如:

对于 string (const string& str, size_t pos, size_t len = npos) ,库中提供了一些额外的解释,如果 npos 的大小超出了字符串的有效长度范围,就自动取到字符串中最后一个有效字符为止。如果没有指定 npos 的值,就使用缺省参数 -1 ,由于 size_t 是无符号整型,所以 -1 实际上是二进制的全一,即最大的整型数值 2^32 - 1 。
2、string类对象的容量操作
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty (重点) | 检测字符串是否为空串,是返回true,否则返回false |
| clear (重点) | 清空有效字符 |
| reserve (重点) | 为字符串预留空间** |
| resize (重点) | 将有效字符的个数改成n个,多出的空间用字符c填充 |
2.1、size 与 length
size 与 length 都是返回字符串的有效字符长度,用法如下:
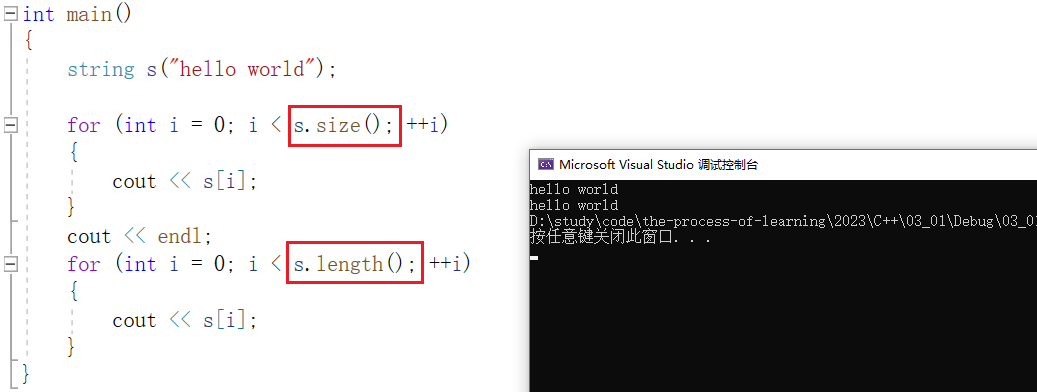
功能完全相同,只是为了名字与 stl 中其他模板的名称保持一致,就增加了一个 size ,除了名字不同外,没有区别。
2.2、capacity 与 reserve
capacity 返回空间总大小,用于观察开辟空间的情况:
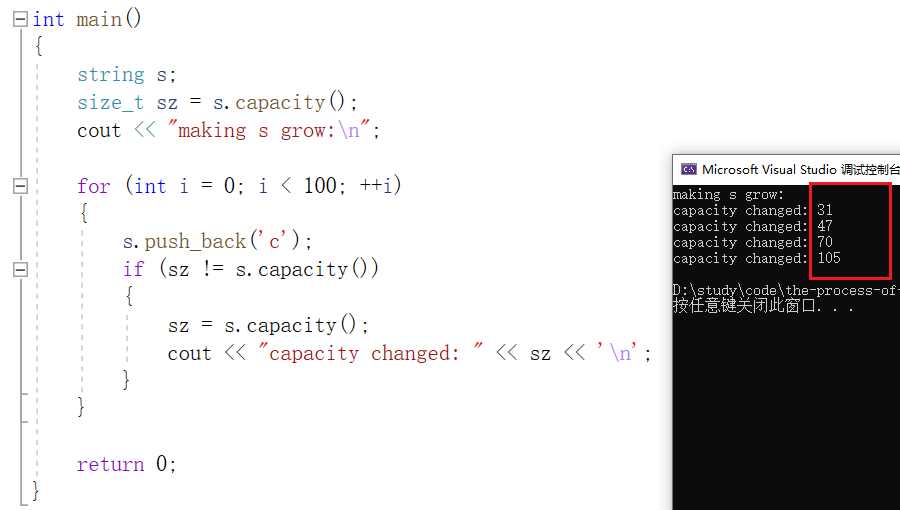
当不断向string对象 s 中尾插字符时,会导致 s 不断的扩容,可以发现除了第一次扩容外,其他扩容后的大小都是上一次的 1.5 倍。
string 对象第一次扩容的规则大致如下:

类string中有一个容量为 16 个字符的数组 buf ,如果对象中存储的字符数量小于等于 16 个,就会把字符存入数组 buf 中,不使用指针 _ptr 。如果对象中存储的字符数量大于 16 个,就会使用指针 _ptr 来开辟空间,第一次直接开辟 32 个字符的空间,并把字符存放在新开辟的空间中, buf 不再使用。之后每次开辟的空间大小是开辟之前大小的 1.5 倍。
这种规则只适用于VS编译器,不同的编译器有不同的扩容规则。
为了防止编译器不断的给 string 对象扩容空间,造成资源的浪费,我们可以使用 reserve 直接给对象预留一定大小的空间:
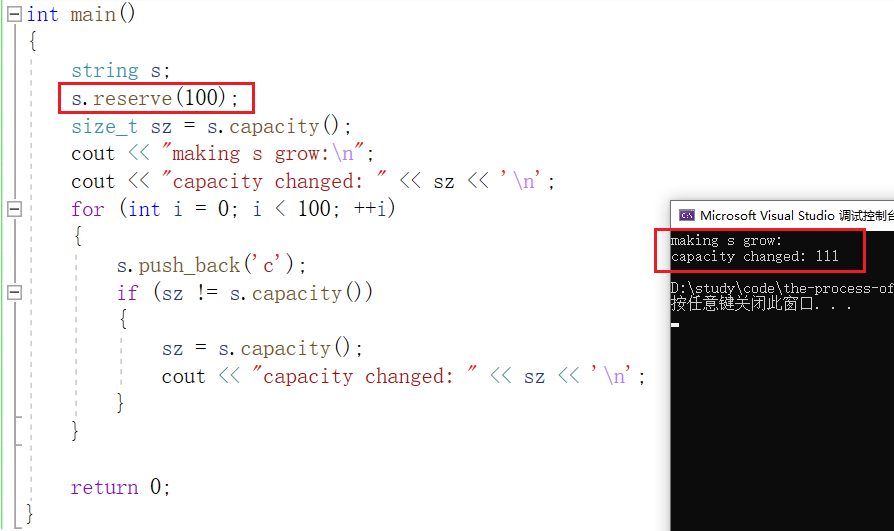
其中因为一些内存对齐等原因,实际内存空间与我们设定的有一些出入,但一定不会比我们设置的小。
2.3、resize
resize 将有效字符的个数改成 n 个,多出的空间用字符c填充。 resize 可以扩容空间,并进行初始值填充:
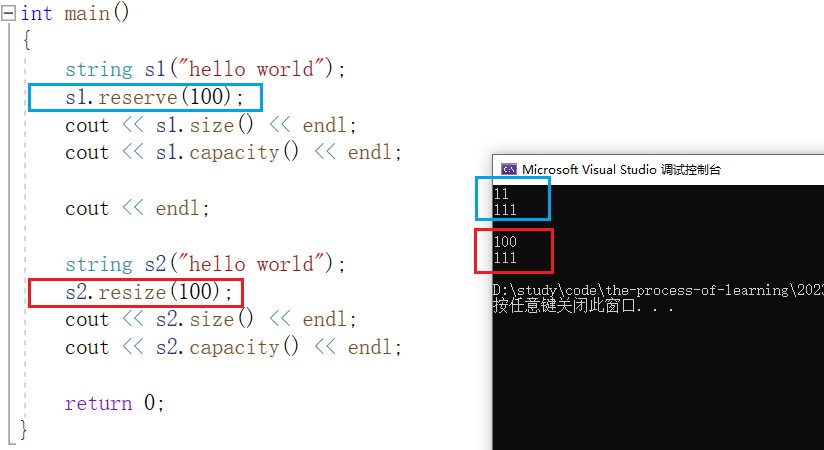
可以看到 resize 与 reserve 不同。使用 resize 进行扩容的时候,也进行了字符填充,使对象的有效字符长度也发生了变化。
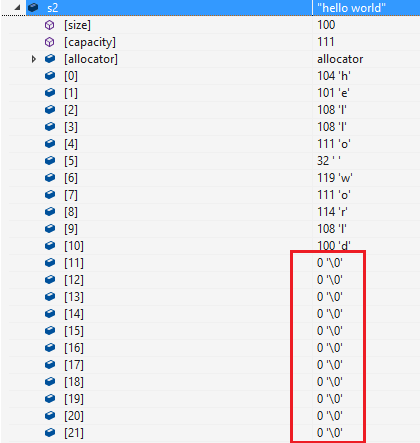
在vs编译器中,默认填充的字符是 '�' 。
我们也可以指定填充的字符,写成如下形式:
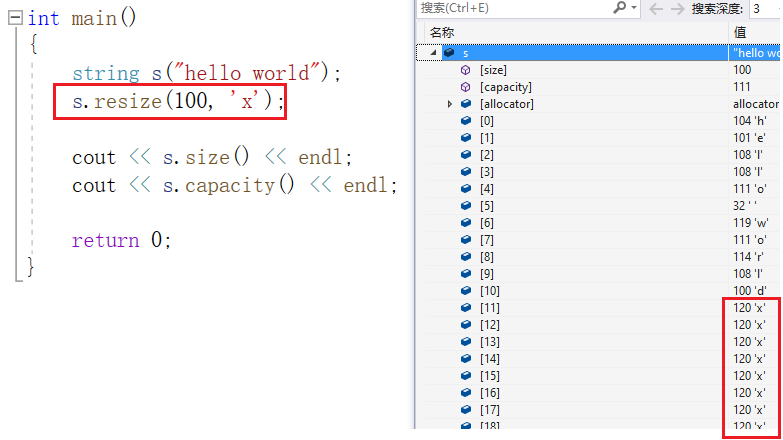
如果指定的 n 值比 size 小,则会删除数据,保留前 n 个:
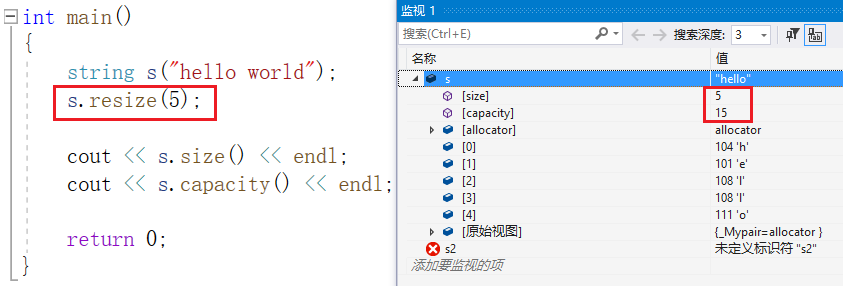
size 变为 5 , capacity 的值不变。
2.4、总结
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
- clear()只是将string中有效字符清空,不改变底层空间大小。
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
3、string类对象的访问及遍历操作
| 函数名称 | 功能说明 |
| operator[] | 返回pos位置的字符,const string类对象调用 |
| begin+ end | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭 代器 |
| rbegin + rend | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭 代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
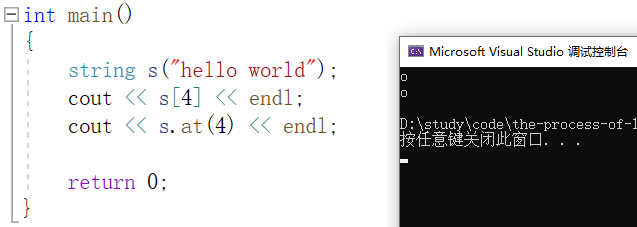
3.1、operator[] 与 at
operator[] 返回pos位置的字符,是一个运算符重载,关于运算符重载的内容,在《类和对象(二)》里有过详细的说明。
at 的作用与 [] 类似,都是获取指定下标的数据,只不过在越界的处理方面有些不同。如果 [] 中的下标越界,程序会直接发生断言错误,终止程序,而如果 at 指向的下标越界,则会进行抛异常。
3.2、begin + end
我们想要打印一个数组,除了使用运算符重载 [] 外,还可以使用 begin 与 end 获取迭代器。具体用法如下:
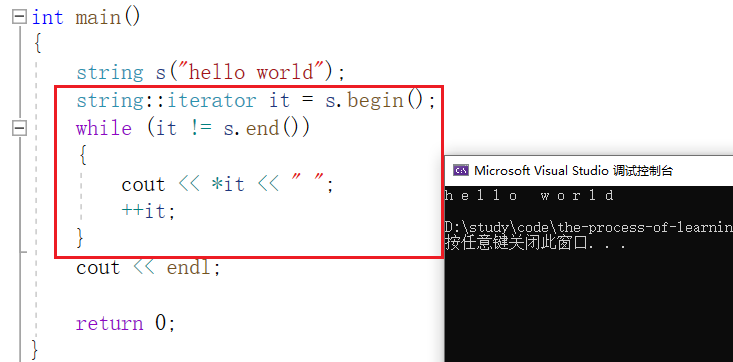
关于迭代器,大家暂时可以先理解为指针, begin 是第一个位置的指针, end 是最后一个位置的下一个位置的指针。
3.3、rbegin + rend
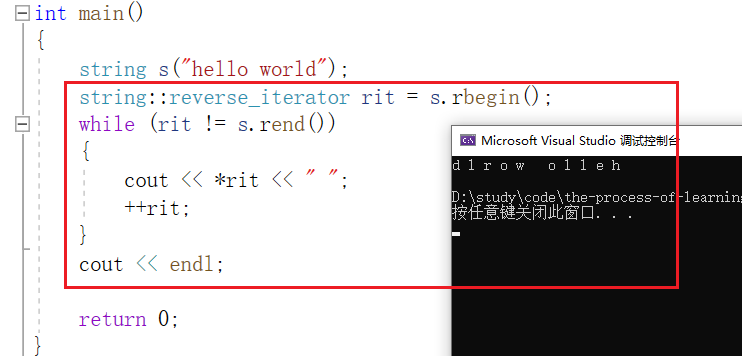
rbegin 与 rend 获取的是反向迭代器,目前阶段同样可以先把他们看作指针,其中 rbegin 指向最后一个数据的位置, rend 指向第一个位置的前一个位置:
用法如下:
3.4、 const类型迭代器
当使用 const 类型来接收string类对象时,如果直接使用关键字 interator 来定义迭代器变量,编译器会报错。
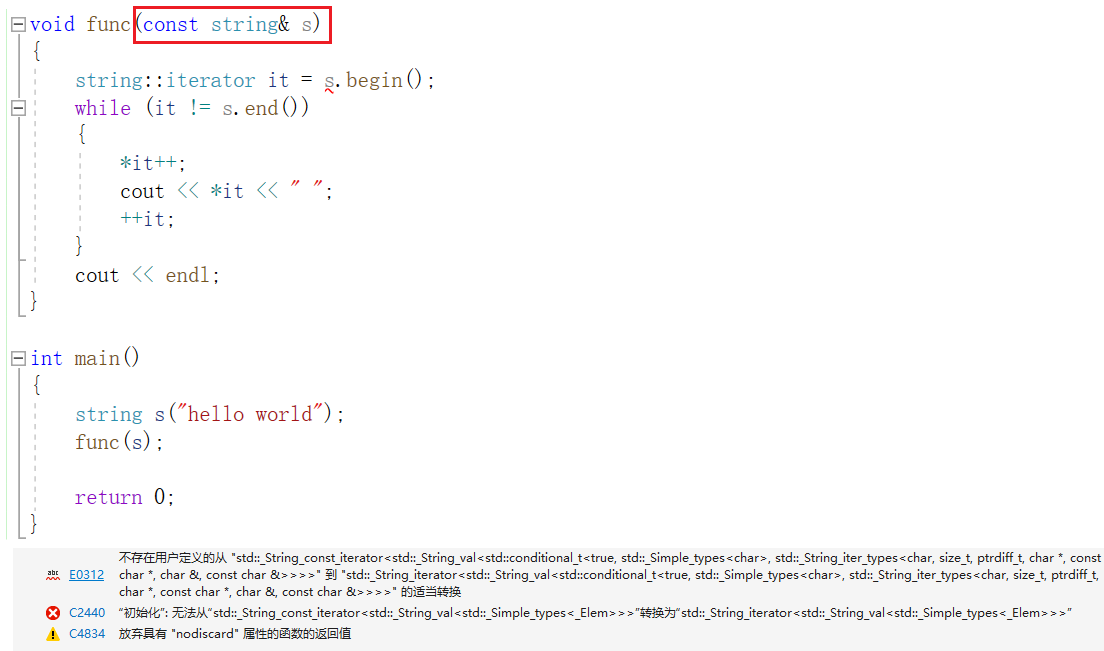
所以为了保证权限不被放大,需要使用关键字 const_iterator 来定义迭代器变量:
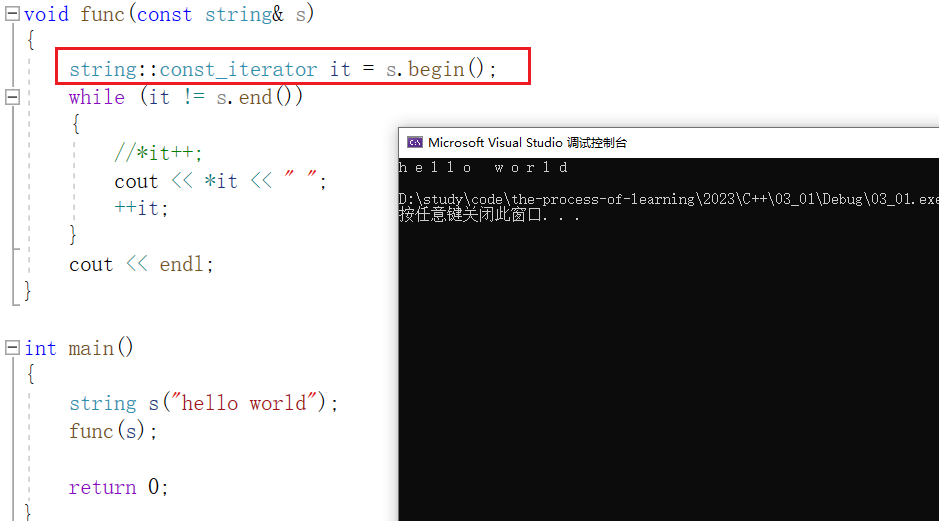
3.5、范围for
打印一个数组,还有另一种方法,就是使用 范围for ,具体用法如下:
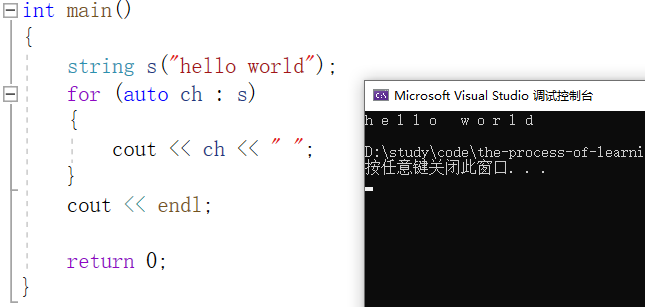
实际上,范围for的底层就是使用迭代器来实现的。
4. string类对象的修改操作
| 函数名称 | 功能说明 |
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串 |
| operator+= (重点) | 在字符串后追加字符串str |
| c_str(重点) | 返回C格式字符串 |
| find(重点) | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| replace | 替换字符串pos位置,len长度的字符 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
| insert | 在str中插入字符 |
| erase | 在str中删除字符 |
| find_first_of | 找到其中任意一个字符,并返回其位置 |
| find_last_of |
4.1、push_back、append、operator+=
push_back 在字符串尾部插入字符,具体用法如下:
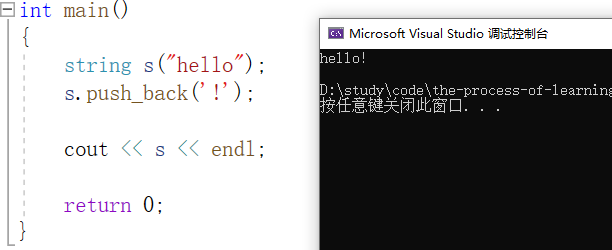
append 在字符串尾部插入字符串,具体用法如下:
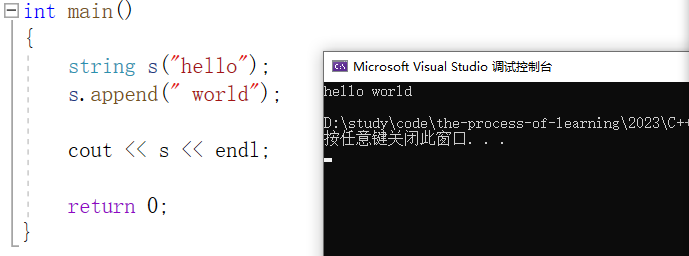
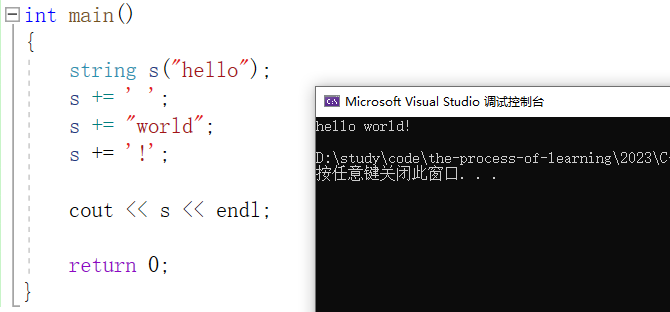
相比较于以上两种接口,最简单且最常用的其实是 operator+= ,具体用法如下:
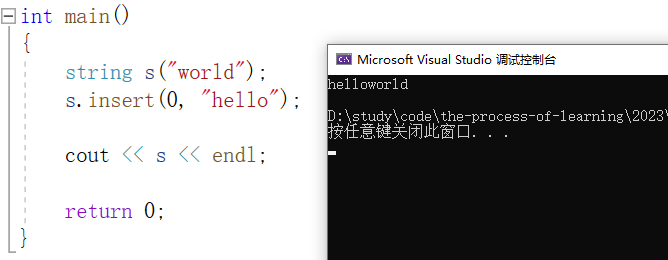
4.2、insert 与 erase
insert :在字符串的 pos 位置插入字符串或者 n 个字符。
比如在字符串 "world" 的第 0 个位置插入字符串 "hello" :
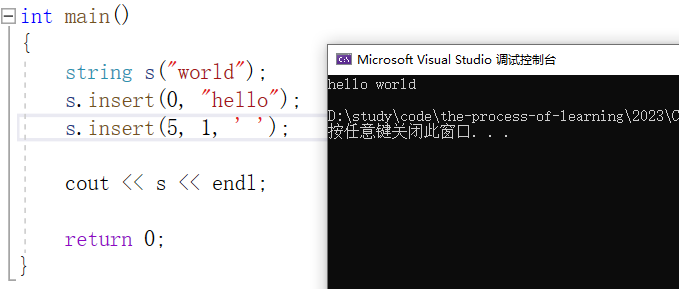
在字符串 "helloworld" 第 5 个位置插入 1 个字符 ' ' :
erase :在字符串的 pos 位置删除 n 个字符。
例如,在字符串 "hello world" 的第 6 个位置删除 1 个字符:
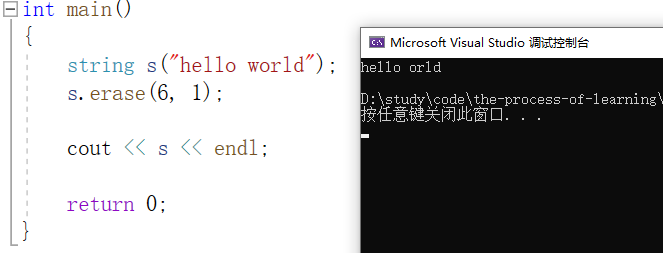
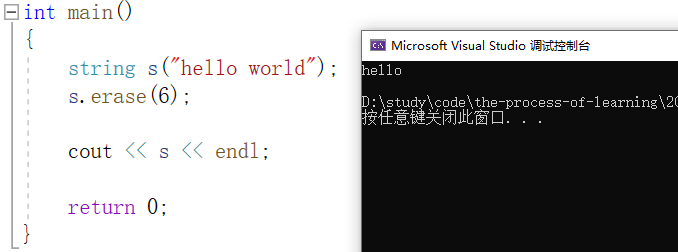
如果指定的 n 超出了字符串的有效范围,或者不指定 n 的值,就删除到字符串最后的位置。
注意: insert 与 erase 不推荐经常使用,因为他们可能都要挪动数据,效率低下。
4.3、find 与 replace
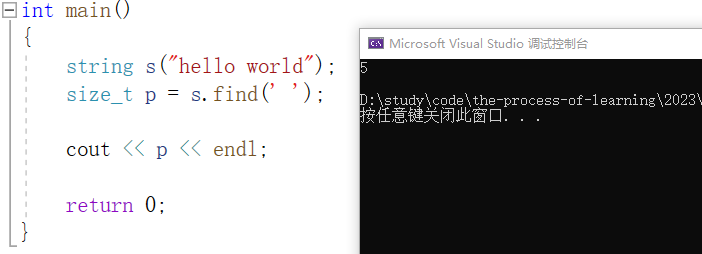
find :从字符串的 pos 位置向后寻找指定字符,返回该字符在字符串中的位置,如果没有指定 pos 的值,就使用缺省参数 0 。如果字符串中没有找到指定字符,就返回 npos ,即无符号整型 -1 。
例如,找到字符串 "hello world" 中 ' ' 的位置:
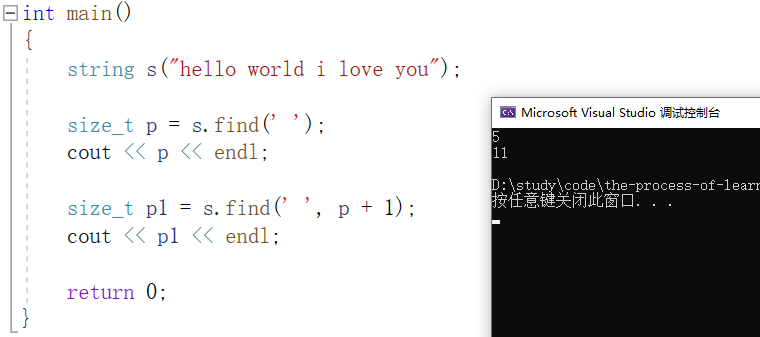
找到字符串 "hello world i love you" 中第二个 ' ' 的位置:
replace :替换字符串 pos 位置, len 长度的字符。
例如,把字符串 "hello world i love you" 中所有的 ' ' 都替换为 "%20" :
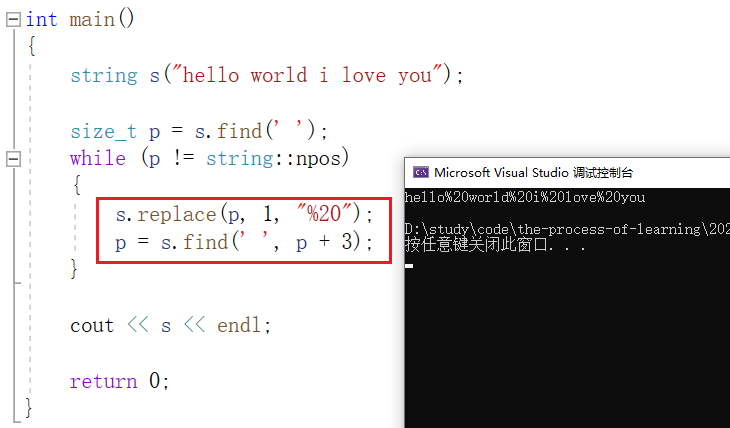
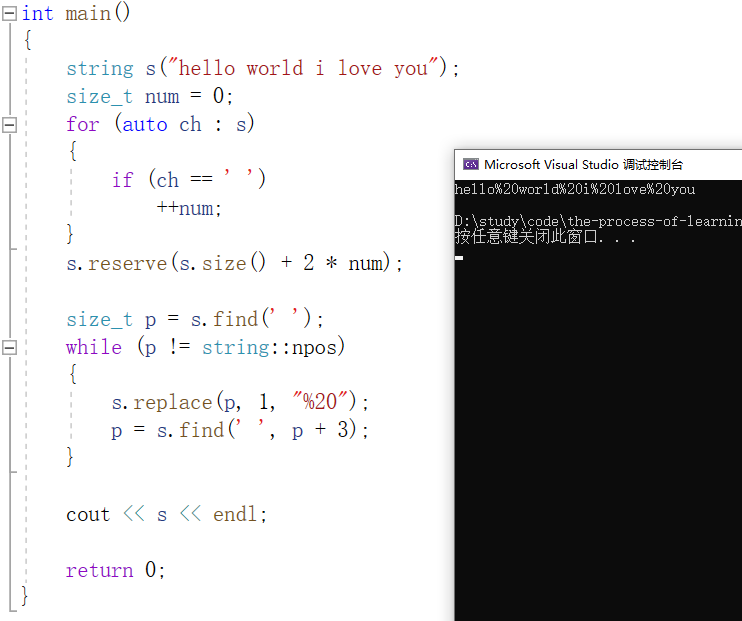
这样每次使用 replace 来替换字符,都会扩容空间,为了提高效率,我们可以使用 reserve 来提前开辟空间:
4.4、substr 与 rfind
substr :在str中从 pos 位置开始,截取 n 个字符,然后将其返回。
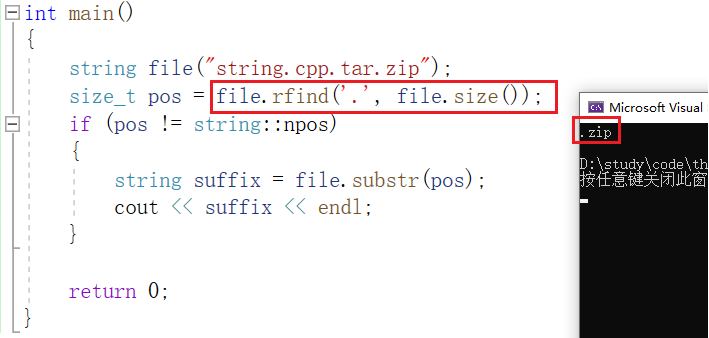
例如:打印字符串 "string.cpp" 的后缀:
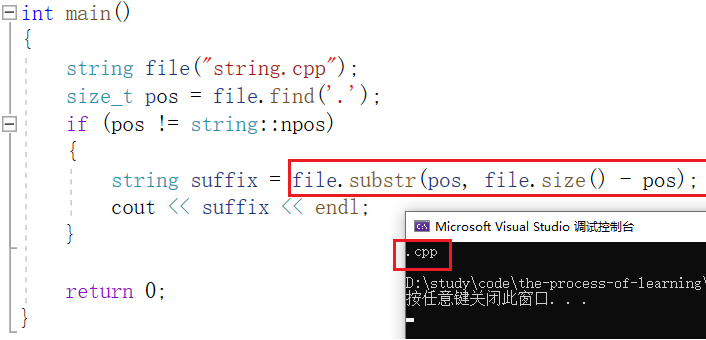
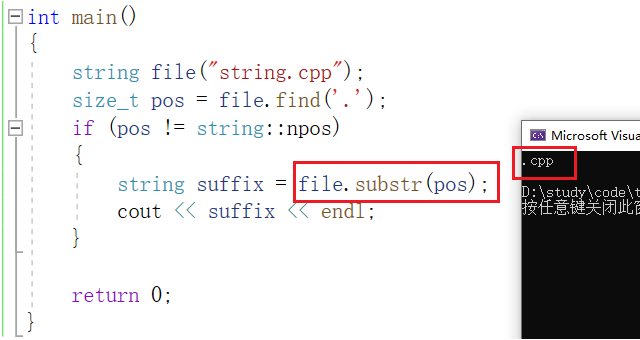
如果我们不指定 n 的值,就使用缺省参数 npos ,即无符号整型 -1 。 不指定 pos 的值,就是用缺省参数 0 :
不过也有时,文件的名字中存在多个字符 '.' , 为了寻找文件真正的后缀,我们需要找到最后一个 '.' 的位置。可以使用 rfind :从字符串pos位置开始往前找指定字符,返回该字符所在的位置:
4.5、c_str
c_str 返回C格式字符串。
打印字符串有如下两种方式:
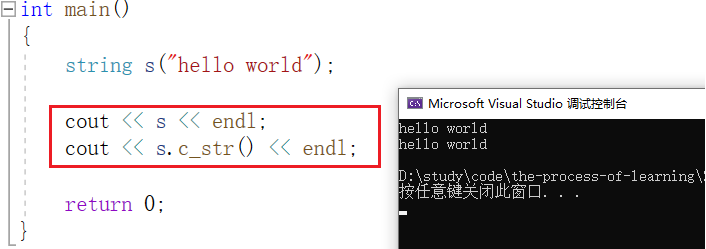
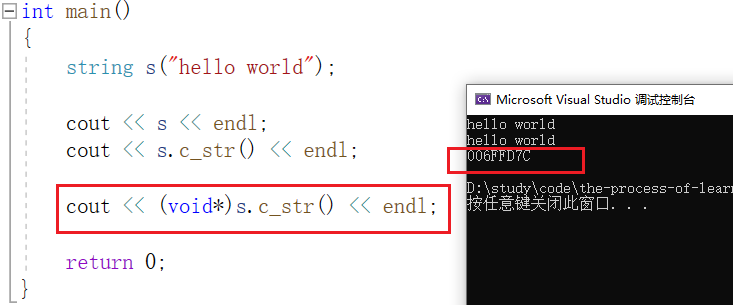
其中第一种,s 是自定义类型, "<<" 是自定义类型重载的流插入。第二种 s.c_str() 返回的是C格式字符串的指针,类型为 char* , "<<" 是库里面的流插入。如果把 s.c_str() 返回的指针强转成其他类型,就会打印出指针,而不是字符串:
如果把字符串进行以下处理后,这两种打印方式得到的结果是不同的:
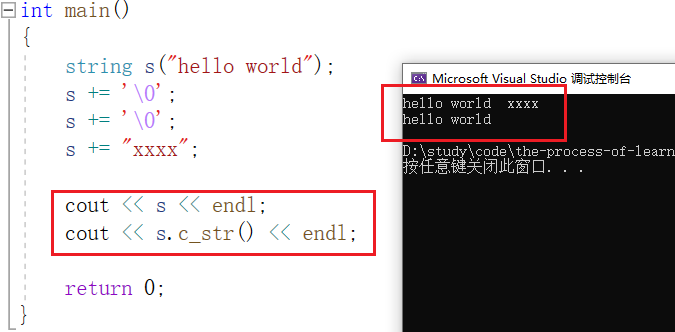
可知,如果我们使用流插入来打印string对象,会以 size 的大小来打印,不会关注 '�' 。而使用流插入来打印 char* 类型的指针,就会打印到 '�' 后结束。
4.6、find_first_of 与 find_last_of
find_first_of :在字符串中,从前往后找到其中任意一个字符,并返回其位置。
例如,把一段字符串中所有的 'a'、'b'、'c'、'd' 都替换为 '*' 。
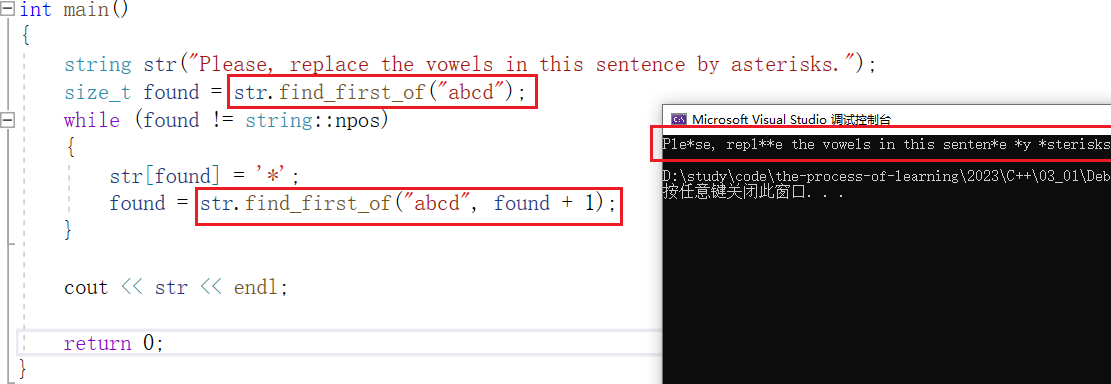
find_last_of :在字符串中,从后往前找到其中任意一个字符,并返回其位置。
5、string类非成员函数
| 函数 | 功能说明 |
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率低 |
| operator>> | 输入运算符重载 |
| operator<< | 输出运算符重载 |
| getline (重点) | 获取一行字符串 |
| relational operators | 大小比较 |
5.1、getline
当我们使用 cin 来提取字符串时,字符串中不能含有空格,因为 cin 在遇到空格、' ' 等字符时,会默认提取结束。
为了解决这个问题,我们可以使用 getline :
int main()
{
string str;
//cin >> str;
getline(cin, str);
return 0;
}关于string类的使用相关内容就讲到这里,希望同学们多多支持,如果有不对的地方欢迎大佬指正,谢谢!
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击